zotero基本使用
【抓取】从浏览器抓取条目时发生错误 抓取时不能自动下载 PDF 无法自动给添加的 PDF 附件创建条目


插件ID:%E6%8A%93%E5%8F%96-%E4%BB%8E%E6%B5%8F%E8%A7%88%E5%99%A8%E6%8A%93%E5%8F%96%E6%9D%A1%E7%9B%AE%E6%97%B6%E5%8F%91%E7%94%9F%E9%94%99%E8%AF%AF
%E6%8A%93%E5%8F%96-%E4%BB%8E%E6%B5%8F%E8%A7%88%E5%99%A8%E6%8A%93%E5%8F%96%E6%9D%A1%E7%9B%AE%E6%97%B6%E5%8F%91%E7%94%9F%E9%94%99%E8%AF%AF
%E6%8A%93%E5%8F%96 %E4%BB%8E%E6%B5%8F%E8%A7%88%E5%99%A8%E6%8A%93%E5%8F%96%E6%9D%A1%E7%9B%AE%E6%97%B6%E5%8F%91%E7%94%9F%E9%94%99%E8%AF%AF:
【抓取】从浏览器抓取条目时发生错误 抓取时不能自动下载 PDF 无法自动给添加的 PDF 附件创建条目
写在最前:达到什么程度算是抓取基本成功了?
Zotero Connector 在网页上能抓取两类东西:
- 文献信息(文献条目的元数据):只要浏览器插件图标或 Zotero 内抓取的条目图标不是蓝色(如下图抓取失败的图标),即能够能够正确地识别出文献类型 ,就已经意味着文献信息/元数据抓取成功。
- PDF 附件成功抓取的前提是:
- 该条目有 PDF 附件
- 有权限下载文献(例如在校外网,极可能无法下载文献)
- 当前网站的转换器(或称翻译器)支持抓取 PDF。对于知网需要更新转换器。
- 网络稳定且运气正常

注意
如果条目抓取正常,只是抓不到附件,通常是无解的。PDF 附件能正常抓到就抓,抓不到就手动添加。 继续折腾下去很可能是浪费了大把的时间,且很难有任何的积极效果。
如果你不能正确地抓取文献信息,或者抓取后的条目里文献信息缺失,那下面这一篇文档对你很重要,请 务必仔细阅读每一点提醒 。这些提醒会对你帮助很大。
如何解决知网等国内网站抓取失败的问题
以下的操作需要用到 茉莉花(Jasminum)插件。如果你还没有安装,请先参照下面这个教程安装茉莉花插件:
#I5004K:📃【常见问题】Zotero 插件安装和更新的问题(包括 Zotero Connecter 浏览器插件的问题)
茉莉花插件可以在这里下载到:
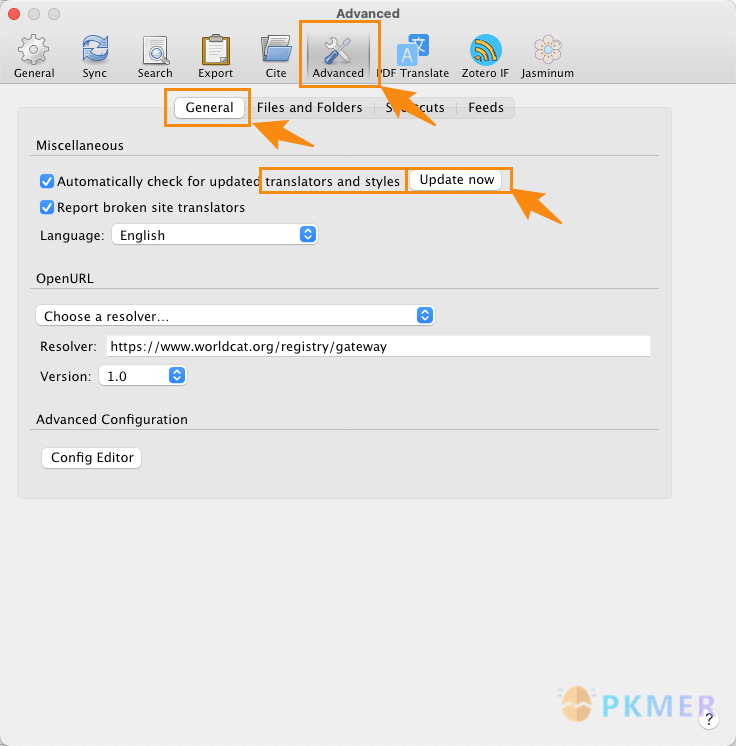
- 在 Zotero 首选项中,进入 [高级/Advanced] 设置。
- 更新官方的 translator: 点击下方“自动检查更新的转换器和样式” 后面的 [立即更新/Update now] 按钮(这里的 translator 可能会被翻译成 [转换器/翻译器/翻译人员]。如果你遇到了这几个描述,他们说的是同一个东西)。
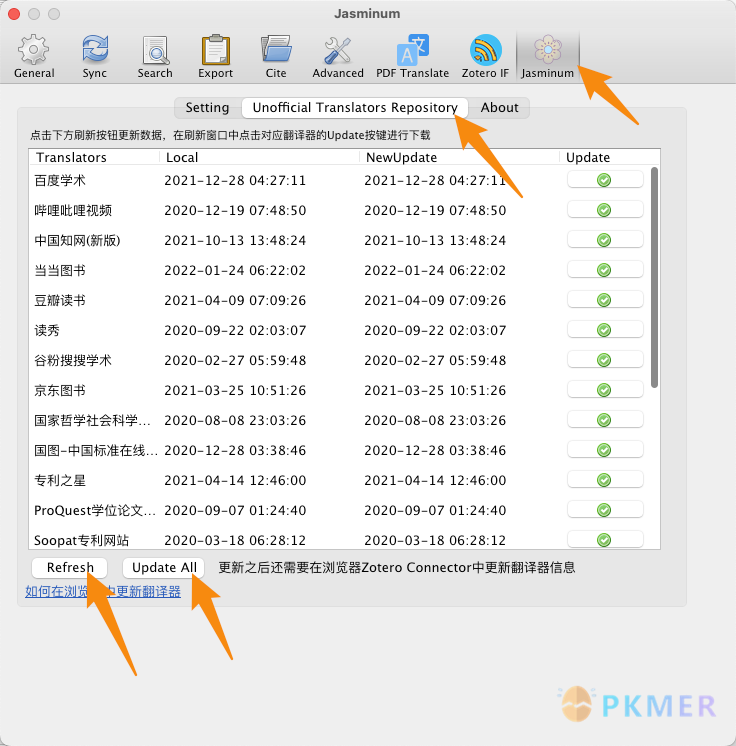
- 更新第三方维护的中文网站 translator: 进入茉莉花插件的设置,打开 [Unofficial Translator Repository] 选项卡,先点击 [刷新/Refresh] 按钮,然后点击 [Update All] 按钮。
- ‼️ 重要步骤 ‼️ 按照这个视频中的教程,更新 每一个浏览器中 Zotero Connector 插件里的 translator: -> [Bilibili] 如何在浏览器中更新转换器/翻译器/translator 注 1: 如果你是按照本文的方法操作的, 只需要观看视频 04:00 之后的部分 并完成里面的操作。视频前半段的工作已经借助茉莉花插件完成了。 注 2: Safari 用户可以在网页空白处点一下鼠标右键,然后点 [Zotero Preferences] 即可进入设置。其他浏览器的设置位置略有差异但都和视频里的位置大同小异,可以自己找找。
- 至此,你应该能解决绝大多数数据抓取/附件下载的问题了。
- 注:translator 的更新可能会十分频繁。如果这次更新 translator 未能解决你的问题,你也可以过一阵再重做以上所有步骤,再次检查是否有更新。
有哪些页面可用来抓取
不是所有页面都可以用 Zotero Connector 进行抓取。即便是在同一个网站,也有部分页面是无法抓取的。这里作如下提醒:
- 尽量不要在搜索结果页(批量)抓取,尤其是在谷歌学术和知网的时候更要避免。 批量抓取时 Zotero 会以极快的速度连续访问该网站,很可能触发该网站的风险控制,给未来带来无尽的麻烦。轻则弹一个验证码验证一下你是否是机器人,重了的话也可能会直接封禁你的 IP(对于学校买了数据库正版版权的那些网站,被封了 IP 可能会被学校请去喝一杯茶)。此外,知网在搜索结果页抓取的时候基本上是完全无法自动下载附件的,所以也不建议这么干。
- 不要在在线阅读界面或者下载了 PDF 后的阅读界面抓取。 这些页面都是无法识别,无法抓取的。你应该 在论文详情页面抓取项目 ,也就是在搜索结果中点击 论文标题 进去的那个页面。
- 不要在 Sci-hub 中抓取文献信息。 Sci-hub 中的文献信息很可能不全,而且大概率会抓取失败。Sci-hub 只适合用来下载文件附件,其他任何事情都不适合。建议你复制页面上的 doi 号,然后打开下面这一网址,在右侧粘贴 doi 号并解析,即可访问文献官方详情页:
-> [DOI 官网] 解析 doi 号
你也可以使用 DOI 号借助 Zotero 中的这一功能快速创建条目并获取文献信息:
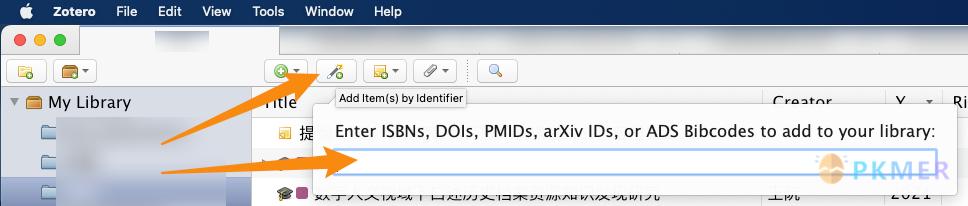 如果通过这一方法得到的条目信息不全,你可以手动补充,或者还是回前面提到的文献详情页抓。
如果通过这一方法得到的条目信息不全,你可以手动补充,或者还是回前面提到的文献详情页抓。 - 不要在任何的镜像站以及学校的网页版校外访问中抓取。 具体原因和解决方案见下文的详细解释。
镜像站及校外访问的问题
- 几乎所有的镜像站都是抓不了的 。Zotero Connector 需要依靠网址来确定调用哪个 translator 来解析网页上的数据。所有的镜像站、图书馆的镜像站会改变原有的网址(改为镜像站自己的网址,或者带上了学校的域名)。 只要网址不是原网站本来的样子,统统都抓不了。 【注意】 切勿在谷歌学术等网站的镜像站直接抓取文献信息,这样的抓取一定会失败。 你可以点击搜索结果进入论文详情页,确认网址是期刊官网后再在详情页抓取。如果详情页的网址也不正确,你也可以复制该文献的 doi 号,然后打开下面这一网址,在右侧粘贴 doi 号并解析,即可访问文献官方详情页: -> [DOI 官网] 解析 doi 号 当然,如果你能直接访问谷歌学术官网(而不是任何镜像站)也就不会有这个问题了。
- 如果你希望在校外抓取 知网 的文献,建议试试 知网官方的校外访问 : -> 中国知网校外访问系统 (这个校外访问系统可以直接抓文献信息,并几乎像是在学校一样可以正常抓取/下载 PDF 附件。但并不是所有学校都能用这个系统,如果你的学校不支持的话,请继续看下一种方法。
- 如果你在用 学校图书馆的镜像站 ,很可能会导致抓取失效。请尽量使用学校提供的 带有客户端的校外访问工具 ,带有客户端的一般不会改变网址,不影响条目抓取。目前,知网的第三方 translator 已经支持了部分学校的网页版校外访问(WebVPN)。请先按照前面的步骤使用茉莉花更新所有的翻译器/translator,然后再尝试抓取。如果依然不行,请继续看下一种方法。
- 还有一种结合使用官网和镜像站的妥协方法,这理论上适合包括知网在内的各种网站。 你可以直接访问期刊官方网站(不走学校的校外访问)仅抓取条目信息 ,然后借助学校的校外访问另外手动下载附件,最终手动在 Zotero 条目中添加这一附件(右击条目,点击 [添加附件] -> [添加文件的副本],然后选择你手动下载的附件)。)
抓取附件及信息处理
- 如果你还想进一步抓取硕博论文的 PDF 附件,你还可以试试 知网国际站 : -> 可下载硕博论文 PDF 附件的知网国际站 (如果你在校外,可以先在前面提到的 知网官方的校外访问 登录进去,然后再来这里下载/抓取)
- 如果你想在抓知网内容的时候 合并中文作者的姓名 ,又或者希望 指定在知网抓取时优先获取 CAJ 格式的附件还是 PDF 格式的附件 ,可以看这个仓库的说明: -> [Gitee] Zotero translators 中文维护小组 重点关注后面的 [ 如何在 Zotero Connector 中添加中文姓名处理以及保留知网 CAJ 格式文件的设置 ] 部分。
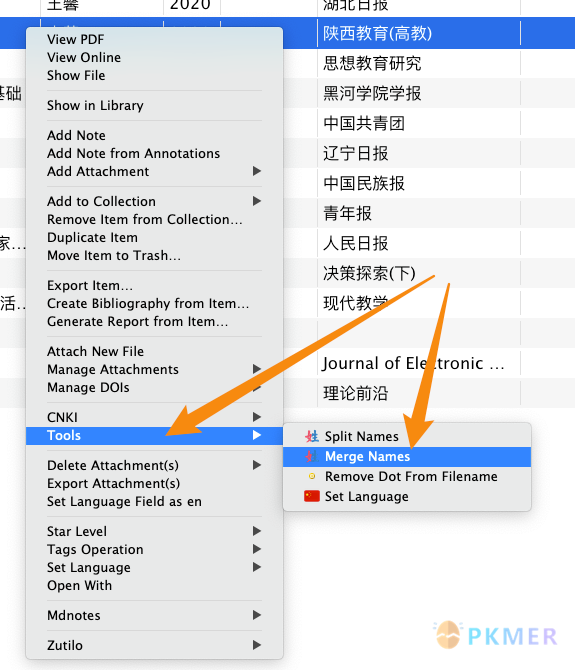
- 如果你已经抓取了一些中文文献,文献库里现存姓名分开的条目,可以多选需要合并姓名的条目,借助 [茉莉花/Jasminum] 插件中的功能进行(批量)合并:
一些和特定站点相关的提醒
- 知网:强烈不建议在搜索结果页面批量抓取文献 ,在这里抓也很可能不能顺带着自动下载附件。其他网站也不建议批量抓取,过高频率的访问(批量抓取的时候访问频率很高)可能会导致你被该网站封禁。知网如果抓取附件失败有很多种可能的原因。请先 确保网站上直接下载附件时不会要求你输入验证码 ,然后再尝试能否成功抓取附件。如果不要求输入验证码了还不能抓,建议按照前面说的更新 translator。如果还不能,建议放弃。
- ** 谷歌学术:** 基于与上一点同样的原因, 不建议在谷歌学术的检索结果页面批量抓取文献 。过多的批量抓取可能导致你的 IP 被封。
- 万方 最近似乎在抽风,可能也是网页有调整 translator 不好使了。万方的 translator 最近已经有更新了,你也可以更新之后再尝试。更新后目前已知万方的搜索结果页上的抓取还是会失败的,但是文献信息详情页的抓取应该已经基本正常了。
- Pubmed 遇到问题的人也很多,如果你也遇到问题了多担待着点。
- 豆瓣 上抓取的信息目前会混入很多乱七八糟的代码,这恐怕是 translator 的问题。除非 translator 的作者更新新版本解决这一问题,或者你自己会开发 translator 帮忙解决这一问题,否则靠自己解决不了。对于图书类的信息抓取,可以改用: -> 国家图书馆文津搜索
- 维普 好像是彻底不行了,换别的网站看看。
其他方法
- 重启电脑
- 换一个文献网站,如期刊官方主页上的论文详情页
- 参见 抓取导入-导入PDF并自动生成条目
- 参见 抓取导入-导入通用格式的引用信息
讨论
若阁下有独到的见解或新颖的想法,诚邀您在文章下方留言,与大家共同探讨。

