
Dataview 语法实战:GROUP BY 操作符进阶示例
1. 当文件匹配多个组时
这个问题我们在 FLATTEN 操作符进阶示例 里面站在 FLATTEN 的角度详细讲过了,这里就站在 GROUP BY 的角度再讲一次。
拿上面那些书本来举例,书的主题属性是数组。考虑这么一个情形:书 A 的主题属性有 a, b 两个值,书 B 的属性只有 a 这个值。那么对书的主题这个属性作 GROUP BY 会有什么结果呢。答案是他们会各自为一组。因为 GROUP BY 成组的条件是必须严格相等,也就是数组中的每个元素都要相等。
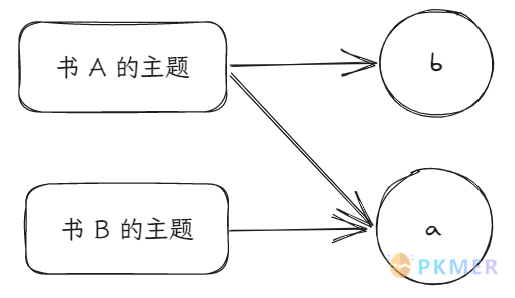
那么我们要怎么做才能让结果变成以 a 和 b 来分组呢
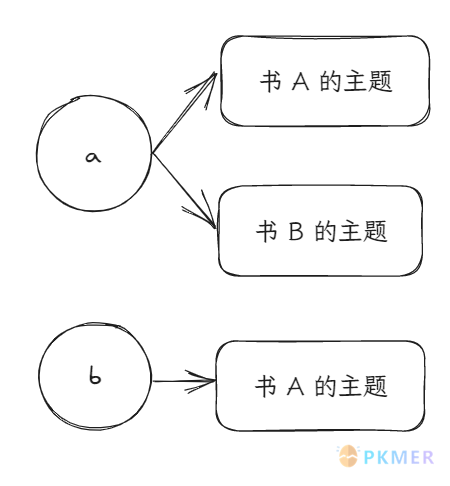
答案是用 FLATTEN 操作符,把 a 和 b 给拆开,再加上 GROUP BY 重新成组即可。
```dataview
TABLE rows.file.link
FROM "10 Example Data/books"
FLATTEN genres
GROUP BY genres
```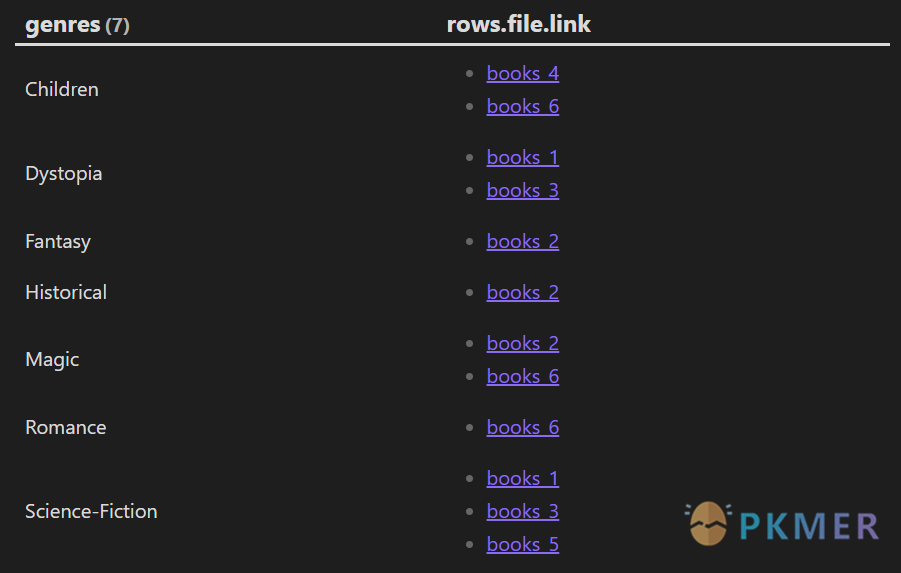
可以看到,books 1 虽然同时有 Dystopia 和 Science-Fiction 两个主题,但是他们被拆分为了两块,我们得到了以 genres 也就是以主题成组的结果。
2. 配合 choice 函数使用
在我的想象中,在以无序列表展示结果并且加上 GROUP BY 操作符时,我们的结果应该长这样

其实只需要配合上 choice(..) 函数即可
```dataview
LIST row.file.link
FROM "..."
GROUP BY choice(条件, 返回值1, 返回值2)当 choice 中的条件满足时,返回前一个返回值。不被满足时,返回第二个返回值。这个条件可以是一个表达式,比如我们可以用 GROUP BY choice(due < date(today), "逾期", "未逾期") 来得到以下的结果

3. 声明一个新的属性
我们选择的成组条件如果是文件中的数据时,会把原来的结果按照这个新的属性进行分组。比如看下面的这段代码
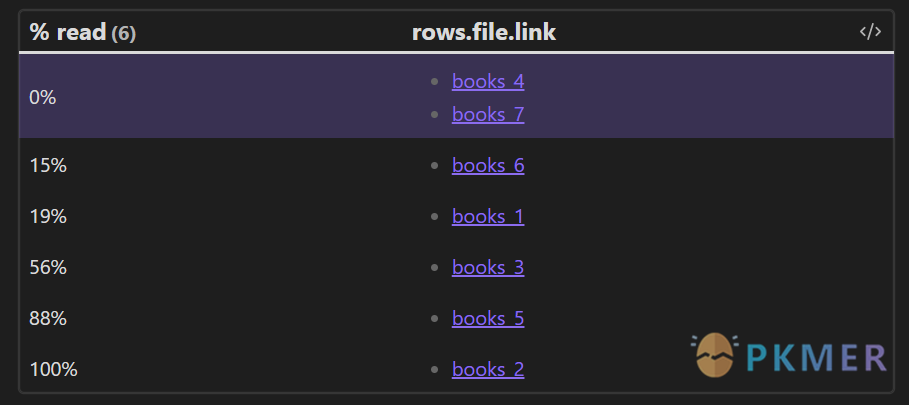
```dataview
TABLE WITHOUT ID progress + "%" AS "% read", rows.file.link
FROM "10 Example Data/books"
GROUP BY round((pagesRead/totalPages) * 100) as progress
```属性 pagesRead 和 totalPages 分别代表书本阅读页数和全书的页数。他们进行除法、乘法、以及运用函数组合后的结果 round((pagesRead/totalPages) * 100) 相当于每一本书的一个新的属性 progress,GROUP BY 会以这个新的属性作为成组条件。
4. 按字面量分组以将结果精简为一个结果
我们总是习惯把文件的属性或者属性的组合作为成组的条件,有没有想过如果成组条件是 字面量 时结果将会如何?
例如,如果你想计算数据的总和或平均值。以一个无关紧要的任意字面量作为成组条件,你的所有查询的文件就会被组合在一起,你就可以用 length(rows) 来得到我们的结果的总数。然后用 WITHOUT ID 就可以省略掉这个无关紧要的字面量。
当文字字面量作为成组条件时,该文本将会用作组名。因此这个无关紧要的文字也可以变成一个有意义的前缀。
```dataview
LIST length(rows)
FROM "10 Example Data/books"
GROUP BY "Total Books in Obsidian"
```比如这一段代码,查询的结果以无序列表的形式展示,以 “Total Books in Obsidian” 开头,随即跟着 “10 Example Data/books” 目录之下的文件的数目。

可以看到,这个目录下面有七本书。
讨论
若阁下有独到的见解或新颖的想法,诚邀您在文章下方留言,与大家共同探讨。

