
Dataview 语法实战:FLATTEN 操作符进阶示例
1. 多次使用 FLATTEN
如果有多个元数据是数组,你想把他们都拆开,可以重复利用 FLATTEN 操作符来实现,例如下面的 DQL 用了两次 FLATTEN 函数
```dataview
TABLE genres, booktopics
FROM "10 Example Data/books"
FLATTEN genres
FLATTEN booktopics
```2. 展开再合并
我们前面说过,FLATTEN 和 Group by 可以理解为反义词,那么如果对同一个属性加以 FLATTEN,随即跟上 Group by。他的结果会跟原来的结果一模一样吗?答案是不一定。因为我们展开的时候,是全部展开,而合并的时候,虽然是施加在同一个属性上,但是合并的方法从按文件合并转变为了按照这个属性合并。
这个操作的主要用途可能在 tags 上,还是拿上面的那批 books 举例,每一本书都可以划分一些类型 genres,比如 book1 有两种类型 Science-Fiction 和 Dystopia,而 book5 也具有类型 Science-Fiction。我们如果直接对 genres 属性加上 Group by 操作符,是无法按照类型吧 book1 和 book5 合并在一起的,原因在于,对 dataview 来说,[Science-Fiction, Dystopia] 和 [Science-Fiction] 是完全不一样的。所以我们需要先按照类型展开,然后再按照类型合并。
这有点像 FLATTEN 是在每个元素内部作了“笛卡尔积”,然后再按照新规则对不同元素之间进行了组合。
没有用 FLATTEN 直接用 Group by:
```dataview
TABLE rows.file.link
FROM "10 Example Data/books"
GROUP BY genres
```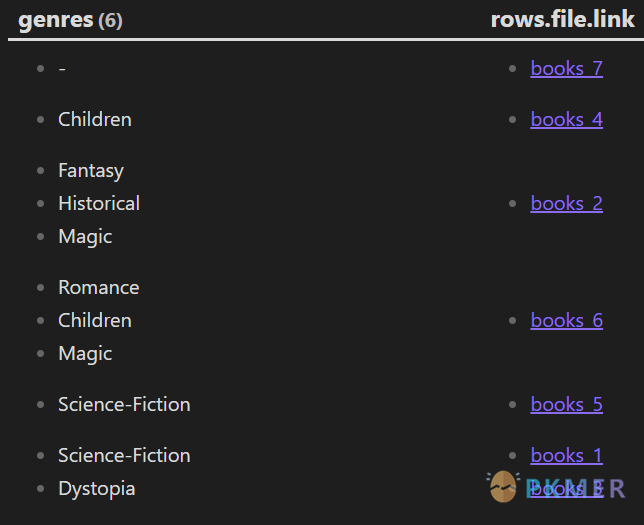
可以看到,只有 books 1 和 books 3 这两本类型完全一样的书籍被归为了一类,其他的书都是单独成行,这就是我们要先展开的目的
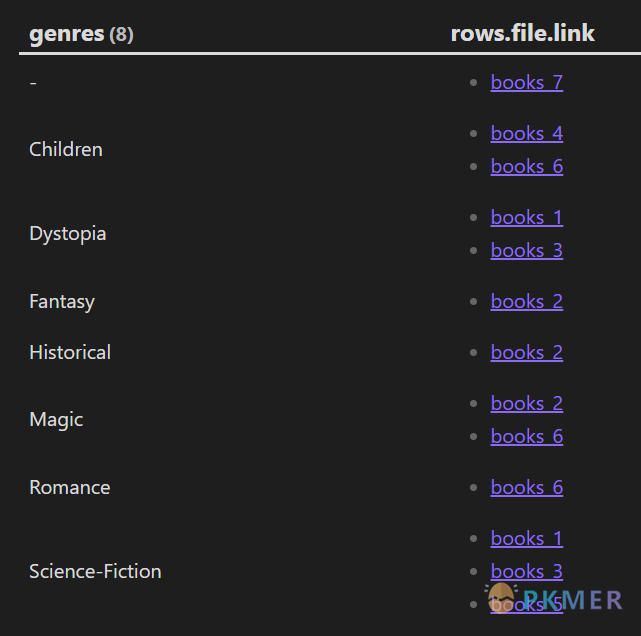
```dataview
TABLE rows.file.link
FROM "10 Example Data/books"
FLATTEN genres
GROUP BY genres
```
注意顺序
虽然 DQL 是可以重复使用操作符的,但是 dataview 执行 DQL 的顺序是自上而下,因此会先执行上面的代码。所以必须先写
FLATTEN再写Group by,另一个要注意这一点的还有排序操作符SORT和限制个数操作符LIMIT。
3. 配合函数使用
假如一个函数的输入值只能是单个值而不能是一个数组时,就需要用到 FLATTEN 函数把他们拆分开。
已知,我们有一篇笔记,假设其路径为 “10 Example Data/dailys/2022-07-22”。笔记中包含了一个一级标题和两个二级标题(“Research” 和 “Topics”),以及一些无序列表,内容如图

现在我们想要一条一条的把 “Research” 标题下的无序列表列出来,我们知道 file.lists.section 可以获取列表所在的标题的链接,使用 meta(..) 函数可以把链接转换成链接包含的元数据,然后取出这个元数据中的 subpath 属性,也就是标题,然后用 WHERE 操作符就能够区分出是在 “Research” 还是在 “Topics” 标题之下了:WHERE meta(file.lists.section).subpath = "Research"。(忘了的可以看 14 - 隐式字段 和 30 - Function 函数 看看各个值代表什么)
但是,还差那么一步,函数 meta(..) 需要的输入值是链接,而不能是一个列表,也就是 meta(file.lists.section) 是会报错的。此时就需要 FLATTEN 出场了,正确的写法应该是
```dataview
TABLE L.text
FROM "10 Example Data/dailys/2022-07-22"
FLATTEN file.lists AS L
WHERE meta(L.section).subpath = "Research"可以看到,对 file.lists 加以展开之后,得到的结果 L 就是一个个单值了,L.section 也就代表每一个列表上方的标题的链接,也就满足了 meta(link) 输入值为链接的要求了。
4. 声明一个新的属性
如果我们想对一些值进行字符串拼接或者对一些数值进行运算的时候,可以直接在 查询字段 中进行组合然后配合 AS 组成一个新的属性。但是这种写法很容易让查询字段变得很长,不美观。同时又因为,当展开的元素不是列表时,结果不会有任何变化,换句话说,就是对结果没什么污染。所以我们可以利用 FLATTEN 后面的区域来做拼接或者运算,再配合 AS 就能声明一个新的属性。
```dataview
TABLE pagesRead, totalPages, progress
FROM "10 Example Data/books"
FLATTEN round((pagesRead / totalPages) * 100) + "%" AS progress
```例如这段代码,在 FLATTEN 操作符后方声明了一个新的属性 progress,利用的是两个数值属性的四则运算和 round(..) 函数的取整以及字符串拼接。
pagesRead 代表书本的已读的页数,totalPages 代表书本的总页数,因此可以得出 progress 代表的就是我们的读书进度。
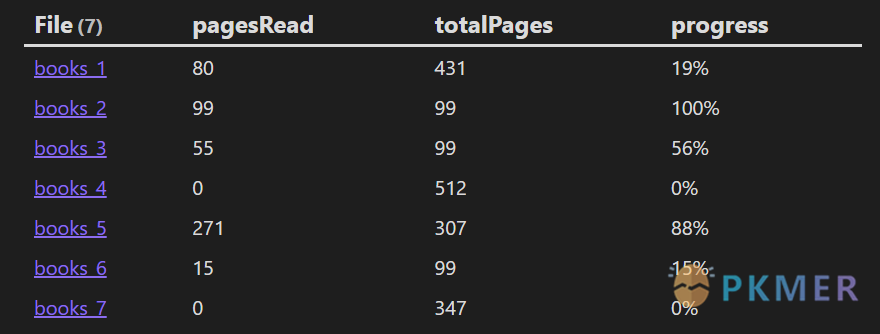
当然,在拼接上 ”%” 之前,progress 属性的数据类型还是数值类型,你完全可以对他做一些其他操作,最后再拼接 ”%” 变成字符串。这些操作可以是排序、筛选进度低于或高于某个值等。
```dataview
TABLE pagesRead, totalPages, Progress
FROM "10 Example Data/books"
FLATTEN round((pagesRead / totalPages) * 100) AS progress
WHERE progress <= 20
SORT progress desc
FLATTEN progress + "%" AS Progress
```
注意
最后,
FLATTEN只能拆数组,而且每用一次能拆一次。如果是数组中的数组,则需要多次用FLATTEN才能完全扁平化。另外,当一个属性的值是对象时,时无法用FLATTEN拆开的。
讨论
若阁下有独到的见解或新颖的想法,诚邀您在文章下方留言,与大家共同探讨。

