
用反思翻译法提升大语言模型的翻译质量
前言
反思翻译法,又称三步翻译法、多轮翻译法;具体实现方法就是让大语言模型(LLM)按照如下步骤进行翻译:
- 初步翻译:让 AI 进行初步翻译
- 自我审视:让 AI 自己检查译文并提出修改建议
- 再次翻译:根据第二步的建议来优化第一步的翻译
这样往往能获得更好的翻译效果。
反思翻译法的本质就是大语言模型智能体(LLM-agent),是负反馈调节与自动化。如果你对理论与学术研究感兴趣,可以阅读文末的学术成果章节,但是这里我们优先讲如何应用它。
效果展示
为了让你直观的感受反思翻译法的效果,下面我将提供七份翻译,请你选择你认为翻译得最好的两个选项。

5 号翻译英国即将禁止在本地开办法律硕士课程?
英国政府正在打击利用人工智能生成非法图像的行为,这当然是件好事,但从措辞上看,似乎任何一种在本地运行的人工智能工具都可以被视为非法,因为它有可能生成有问题的内容。以下是新闻中的一段话:
“内政部表示,为了更好地保护儿童,英国将成为世界上第一个规定拥有、创建或分发旨在创建儿童性虐待材料(CSAM)的人工智能工具为非法的国家,最高可判处五年监禁。” 他们还提到了一些关于教他人如何为这些目的使用人工智能的手册。
在我看来,无论用户是否愿意,在本地运行的任何未经审查的 LLM 都可以用来生成非法内容,因此可以根据该法律进行起诉。还是我理解错了?
6 号翻译英国政府正在打击利用人工智能生成非法图像的行为,这当然是件好事,但措辞似乎暗示任何本地运行的 AI 工具都可能被视为非法,因为它们有潜在生成不良内容的可能。
以下是新闻中的一段引述:
“内政部表示,为了更好地保护儿童,英国将成为世界上第一个将拥有、创建或分发旨在制作儿童性虐待材料(CSAM)的 AI 工具定为非法的国家,最高可判处五年监禁。”他们还提到了一些关于教别人如何使用 AI 进行这些目的的指南。
在我看来,任何未经审查的本地运行的大型语言模型都可以用来生成非法内容,无论用户是否有意为之,因此可能会根据这项法律被起诉。还是我理解错了?
7 号翻译英国政府正在针对使用人工智能生成非法图像的行为进行打击,这当然是件好事,但措辞似乎暗示任何本地运行的 AI 工具都可能被视为非法,因为它们有生成可疑内容的潜力。以下是新闻中的一段引述:
内政部表示,为了更好地保护儿童,英国将成为世界上第一个将拥有、创建或分发旨在创建儿童性虐待材料(CSAM)的 AI 工具定为非法的国家,最高可判处五年监禁。他们还提到了一些关于教别人如何使用 AI 达到这些目的的手册。
在我看来,任何本地运行的未经审查的大型语言模型(LLM)都可能被用来生成非法内容,无论用户是否有意,因此可能会根据这项法律被起诉。或者我理解错了?
下面揭晓谜底,1-7 号翻译来源依次为:
- 微软翻译
- google 翻译
- gemma2:2b 使用沉浸式翻译
- deepseek-v3 使用沉浸式翻译
- deepL 翻译
- 反思翻译法 +deepseek-v3(单次 prompt)
- 反思翻译 +deepseek-v3 (langchain)
我邀请了几名群友进行盲测,他们分别选择了 37,64,36。
虽然因为翻译与评价的样本量太小,不具备统计学意义,但我相信你也能感受到 LLM 在翻译领域的优势。
如果你还有疑惑的话,不妨自己亲手试试吧。下面我会讲解多种实现路径,你可以根据自己的使用场景与动手能力选择适合的方法。
实现方法
单次 prompt 实现
“单次 prompt 实现”是我自创的一个词,它强调以下几点:
-
单轮推理(Single-turn Inference) 这是最基础的形式,即 LLM 直接基于一个 prompt 进行回答,没有额外的上下文记忆或复杂逻辑。例如:
输入:"请解释量子纠缠的概念。" 输出:"量子纠缠是指两个或多个粒子之间存在的一种特殊的量子关联......" -
端到端推理(End-to-End Inference) 这个概念强调的是模型一次性完成整个任务,而不是拆解成多个步骤。例如:
输入:"帮我写一封道歉信,主题是迟到。" 输出:"亲爱的 XXX,很抱歉我今天迟到了......" -
零样本学习(Zero-shot Learning)/ 一次性推理 指的是 LLM 直接处理任务,而不需要提供示例。例如:
输入:"将 'I love programming' 翻译成法语。" 输出:"J'aime la programmation." -
提示工程(Prompt Engineering) 在单个 prompt 中优化提示词的方式,使得 LLM 能够高效输出正确结果。例如:
输入:"用简单易懂的方式解释黑洞。" 输出:"黑洞是一个引力极强的天体,连光都无法逃脱......"
相对而言,LangChain 的多步骤任务涉及 Memory(记忆)、Chains(链式推理)、Agents(智能体决策)等,而单个 prompt 的任务一般就是一次性完成,无需分步执行。
bob
bob 是 macos 上的一款划词翻译软件。
安装 bob-plugin-openai-translator 插件,然后参考如下配置:
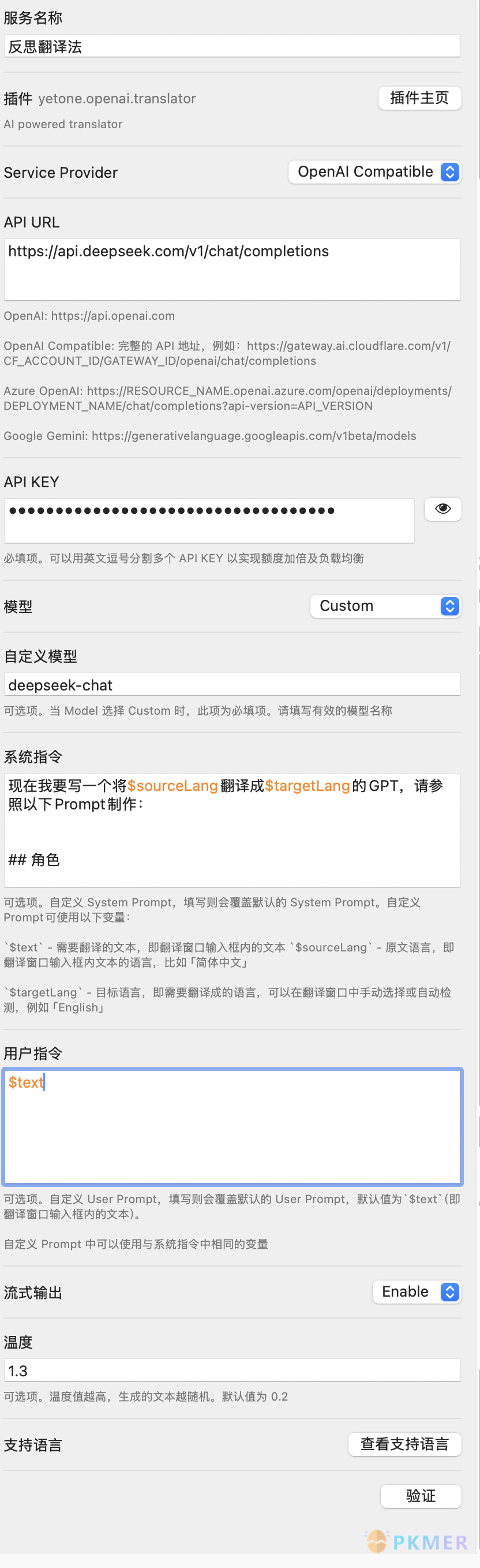
系统指令:
现在我要写一个将$sourceLang翻译成$targetLang的GPT,请参照以下Prompt制作:
## 角色
你是一位经验丰富的同声翻译大师,擅长以日常口语风格翻译。请你帮我准确且通俗地将以下$sourceLang翻译成$targetLang,风格与$targetLang日常口语保持一致。
## 规则:
- 输入格式为 Markdown 格式,输出格式也必须保留原始 Markdown 格式
• 只输出意译的结果,其他内容不需要返回给用户
- 以下是常见的相关术语词汇对应表(中文 -> English):
* 零样本 -> Zero-shot
* 少样本 -> Few-shot
## 策略:
分三步进行翻译工作,但请你只打印第三步的结果,并且不要包含“## 意译”标题(即只输出反思翻译后的译文):
1. 根据$sourceLang内容直译成$targetLang,保持原有格式,不要遗漏任何信息
2. 根据第一步直译的结果,指出其中存在的具体问题,要准确描述,不宜笼统的表示,也不需要增加原文不存在的内容或格式,包括不仅限于:
- 不符合$targetLang表达习惯,明确指出不符合的地方
- 语句不通顺,指出位置,不需要给出修改意见,意译时修复
- 晦涩难懂,模棱两可,不易理解,可以尝试给出解释
3. 根据第一步直译的结果和第二步指出的问题,重新进行意译,保证内容的原意的基础上,使其更易于理解,更符合$targetLang日常用语的表达习惯,同时保持原有的格式不变用户指令:
$text设置页面截图:
浏览器插件:划词翻译
如果你不想使用 bob,并且只是在浏览器中使用划词翻译,你可以使用 划词翻译 插件
根据上面的 prompt,把里面的变量替换为划词翻译规定的变量。
划词翻译变量{{text}} 会被替换为你划选 / 输入的文本。此参数必须要包含进翻译命令中
{{target}} 会被替换为目标语种,例如”中文 (简体)”
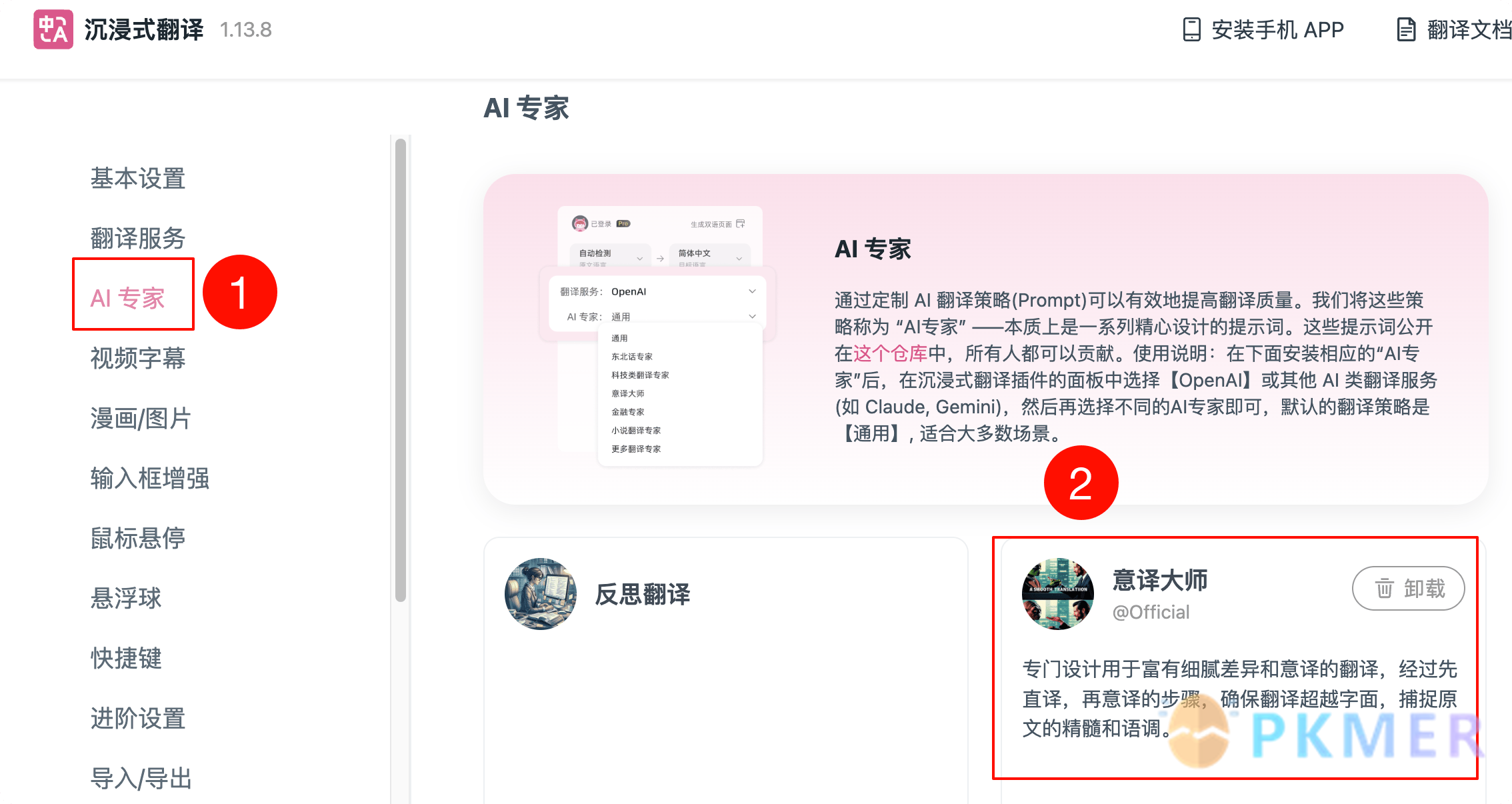
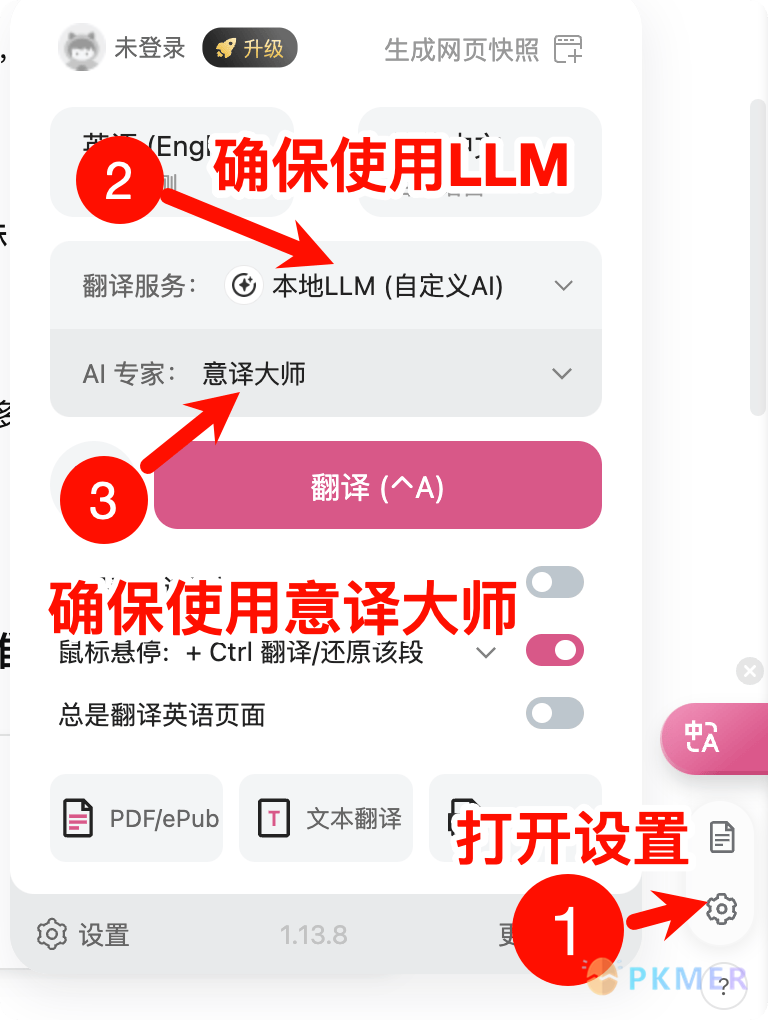
沉浸式翻译
无需自行配置,打开沉浸式翻译设置 -【AI 专家】-【意译大师】,在使用 LLM 类翻译服务(不想折腾的可以用免费的智谱 GLM 翻译)时选择意译大师即可。
langchain 实现
“langchain 实现”与上述的“单次 prompt”相对应,看上去似乎只是把“与 LLM 沟通”这个行为从一次询问变成了多次询问,但是在使用类似的 prompt 的前提下,我发现 langchain 实现的效果往往比单次 prompt 的好。这可能与 LLM 的上下文注意力机制等因素相关,这里我们不作讨论。
fastgpt
fastgpt 是一个开源的低代码自动化工具,他们的工程师写了一篇的文章,详细讲解了反思翻译法的具体实现步骤,我建议直接阅读此文:多轮翻译机器人 | FastGPT。
defy
defy 类似 fastgpt,功能大同小异。
n8n
n8n 是一个开源的低代码自动化工具,相比与 fastgpt 与 defy 那种专注于 LLM 的自动化工具,n8n 追求的更全面。与它类似的,举一个国人更耳熟能详的例子,就是影刀 RPA。
n8n 是众多开源的低代码平台中,免费版限制最少的那个,因此我比较推荐使用它。
如果你对具体实现感兴趣,可以看我的这篇文章:用n8n实现反思翻译
n8n + 划词翻译
如果你想在划词翻译中使用 langchain 实现的反思翻译,可以在 n8n 中模拟 openai 格式的 api 或者采用 划词翻译自定义翻译源格式的api。
我把我自己制作的两个 n8n 流程分享到 GitHub 了,导入后配置 LLM 地址就好,我默认使用的 deepseek。
分享工作流文件:
学术界的相关研究成果
吴恩达团队开源的翻译智能体 Translation-agent
项目地址: andrewyng/translation-agent
哈工大与鹏城实验室的论文
在查资料的时候找到一篇论文 DUAL-REFLECT: Enhancing Large Language Models for Reflective Translation through Dual Learning Feedback Mechanisms,在反思翻译法的基础上增加了 回译 的步骤,下面是我用 chatgpt 生成的论文总结。
Note论文总结 :DUAL-REFLECT:基于双向学习反馈机制增强大语言模型的反思性翻译能力
论文背景
近年来,大语言模型(LLMs)在机器翻译领域表现突出,尤其是通过自我反思(self-reflection)来改进翻译质量。然而,现有的反思机制存在反馈信息不足的问题,导致翻译质量提升有限。为此,本文提出 DUAL-REFLECT 框架,该框架利用 双向学习(dual learning) 机制提供有效反馈,从而增强 LLMs 的自我反思能力,提高翻译质量,特别是在低资源语言翻译任务中的表现。
DUAL-REFLECT 方法
DUAL-REFLECT 由 五个关键阶段 组成:
- 初稿翻译(Draft Translation): LLM 生成初始翻译。
- 回译(Back Translation): LLM 将目标语言翻译回源语言。
- 过程评估(Process Assessment): 评估回译结果是否与源文本一致,决定是否进入下一步反思。
- 双向反思(Dual Reflection): LLM 比较回译结果与原始文本的差异,并分析改进建议。
- 自动修正(Auto Revision): 结合反思反馈,对初稿翻译进行优化。
实验与评估
- 数据集: 使用 WMT22、WMT23 以及 Commonsense Reasoning MT 数据集进行评测。
- 对比方法: 包括 ChatGPT、GPT-4、Self-Reflect、MAPS 和 MAD 等现有方法。
- 评测指标: 采用 COMET 和 BLEURT 自动评价指标,以及人工评测。
实验结果表明:
- 在 WMT22 和 Commonsense MT 基准测试中,DUAL-REFLECT 在 多个语言对上均取得最佳成绩,相比 ChatGPT 平均提升 +1.18 COMET,相比 Self-Reflect 提升 +0.75 COMET。
- 在 低资源语言对(如 Cs→Uk) 上,DUAL-REFLECT 超越 ChatGPT +2.2 COMET,超越 MAPS +1.4 COMET,表明该方法在低资源环境下的优越性。
- 在 常识推理翻译任务 中,DUAL-REFLECT 超越 GPT-4,展现了更强的逻辑推理能力。
- 人工评测结果 进一步表明,DUAL-REFLECT 在 消除翻译歧义 方面表现更优。
结论
本文提出的 DUAL-REFLECT 框架 通过 双向学习反馈机制,增强 LLMs 的自我反思能力,从而提高翻译质量。该方法在不同资源条件下均表现良好,特别是在低资源语言翻译和常识推理翻译方面超越现有方法。实验和人工评测均证明了该方法的有效性。
局限性
- 计算资源需求高: 由于涉及多轮回译和反思修正,该方法计算开销较大。
- 依赖回译质量: 若回译质量较差,反思机制可能会受限,影响最终翻译质量。
贡献
DUAL-REFLECT 通过引入 双向学习机制,为机器翻译提供了更强的自我优化能力,尤其适用于 低资源语言翻译和复杂推理任务,对未来 LLMs 在翻译领域的应用具有重要意义。
总结
LLM 在文字领域是一块巨大的璞玉,而反思翻译法则起到雕琢的作用,我相信在不久的将来,不同语言之间的隔阂会越来越小,阅读外语不再令人望而生畏。
讨论
若阁下有独到的见解或新颖的想法,诚邀您在文章下方留言,与大家共同探讨。

