
通过 Python 脚本实现 Eagle 管理 Zotero 标注的图片
这篇文章介绍一种通过 Eagle 来管理 Zotero 的图片,同时给图片添加 Zotero 的外部回链,这样你就可以通过图片去定位文献以及图片存在的位置,其中会借助 Python 脚本来辅助完成一个批量过程,有兴趣的可以了解一下。
Eagle 软件介绍
Eagle 是一款图片素材管理软件,可帮助用户有效组织、管理和使用图片素材。它提供直观易用的界面,让用户能快速浏览和搜索图片素材库。此外,Eagle 还提供强大的标签和分类功能,让用户按需整理和归类图片素材,创建自己的图片素材库。
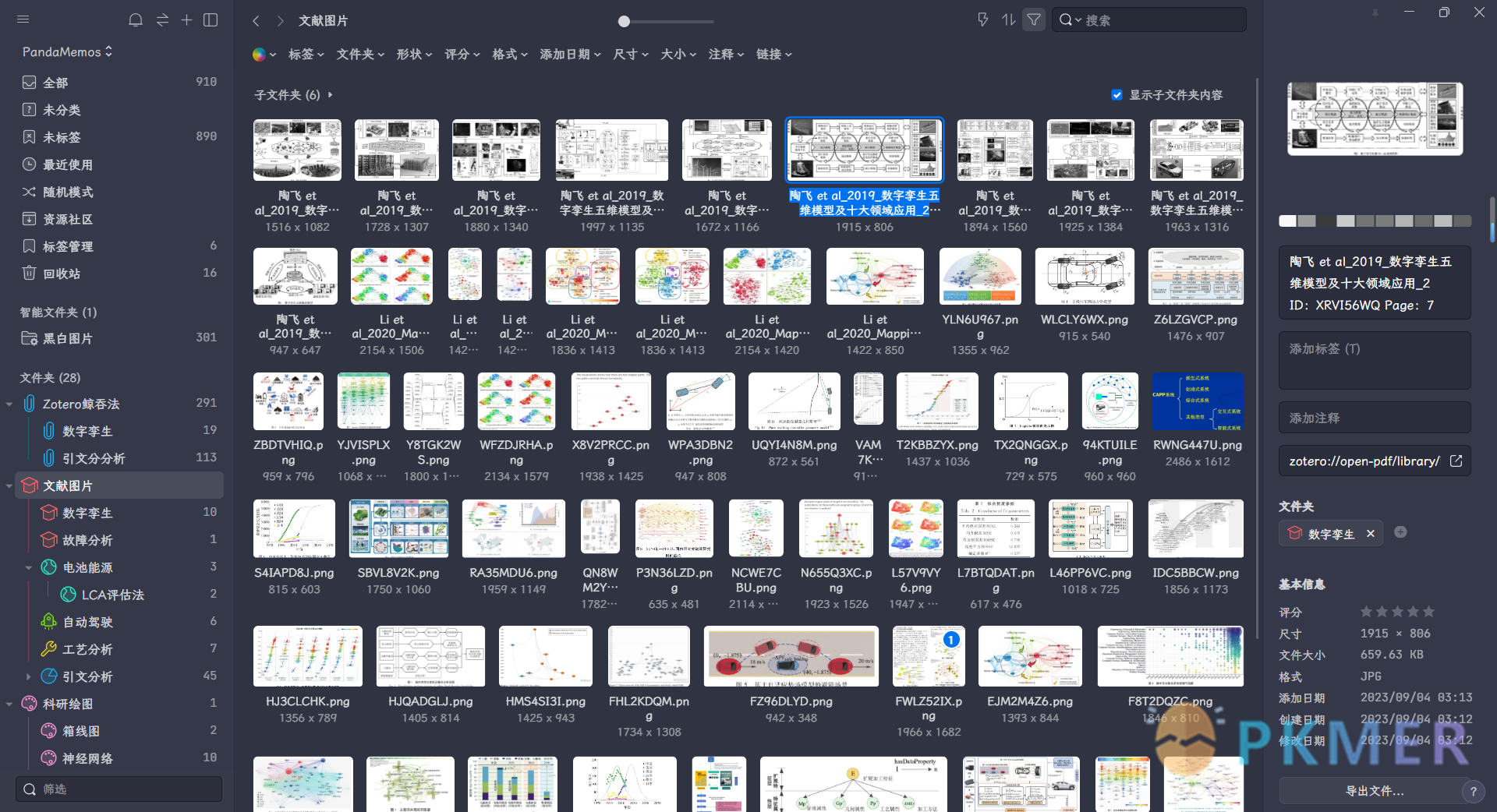
思路讲解
Zotero 标注的图片位置
Zotero 的标注图片一般在你定义的数据库的文件夹的cache->library下面:
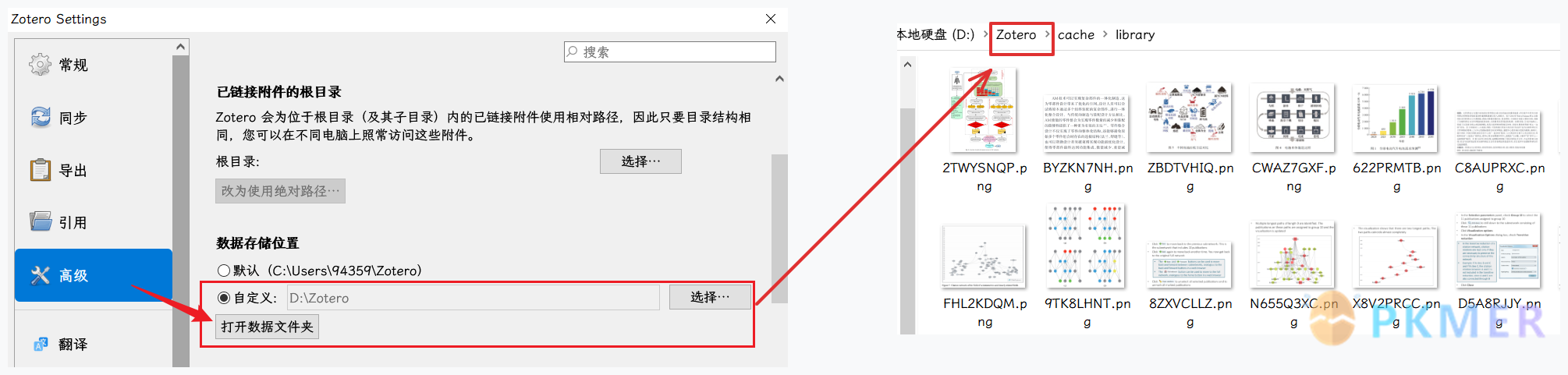
Zotero 回链的组成
- Zotero 的回链组成:PDF 文件夹、页码、注释号=图片名称 (自动命名的)
zotero://open-pdf/library/items/9P4STCK8?page=2&annotation=IDMC67ZS- 缺少注释号或者页码并不会打断跳转,只是缺少了精确定位;
- 其实对标注的信息还可以通过图片名进行精准定位:
zotero://open-pdf/library/items/图片名?annotation=图片名- eg:
zotero://open-pdf/library/items/ZZR39PI7?annotation=ZZR39PI7
- eg:
- PS: 由此就可以通过图片名称就可以知道 Zotero 的外部回链了。
如何批量导入 Eagle
由于 Eagle 对图片的管理形式并不是文件夹的管理方式,素材存储在 E:\PandaMemos.library\images 路径下,命名并不规则 (这一点和 Zotero 的 PDF 管理一样),如何批量导入图片也是一种问题:
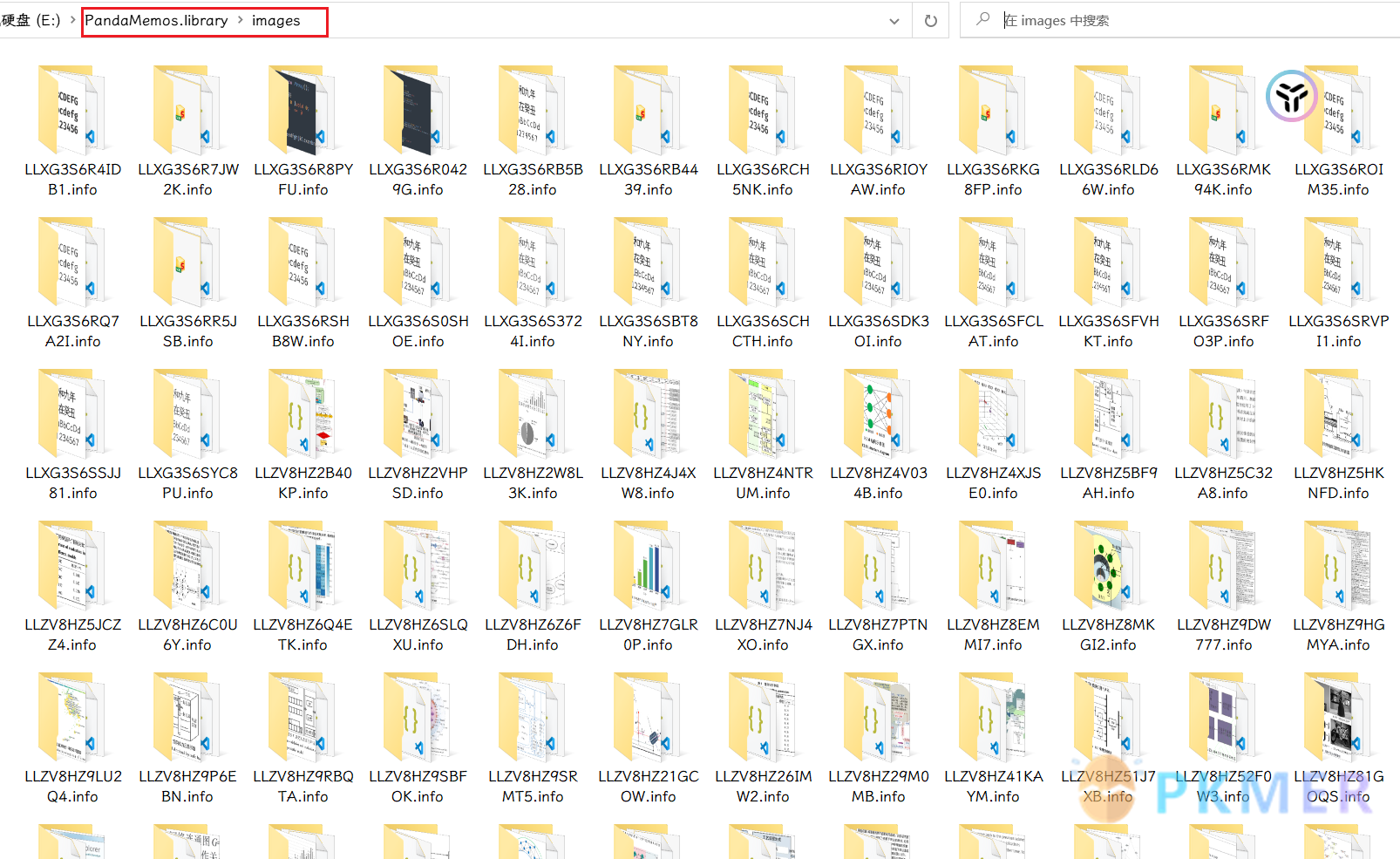
不过我发现在设置里面有一项自动的导入的选项:
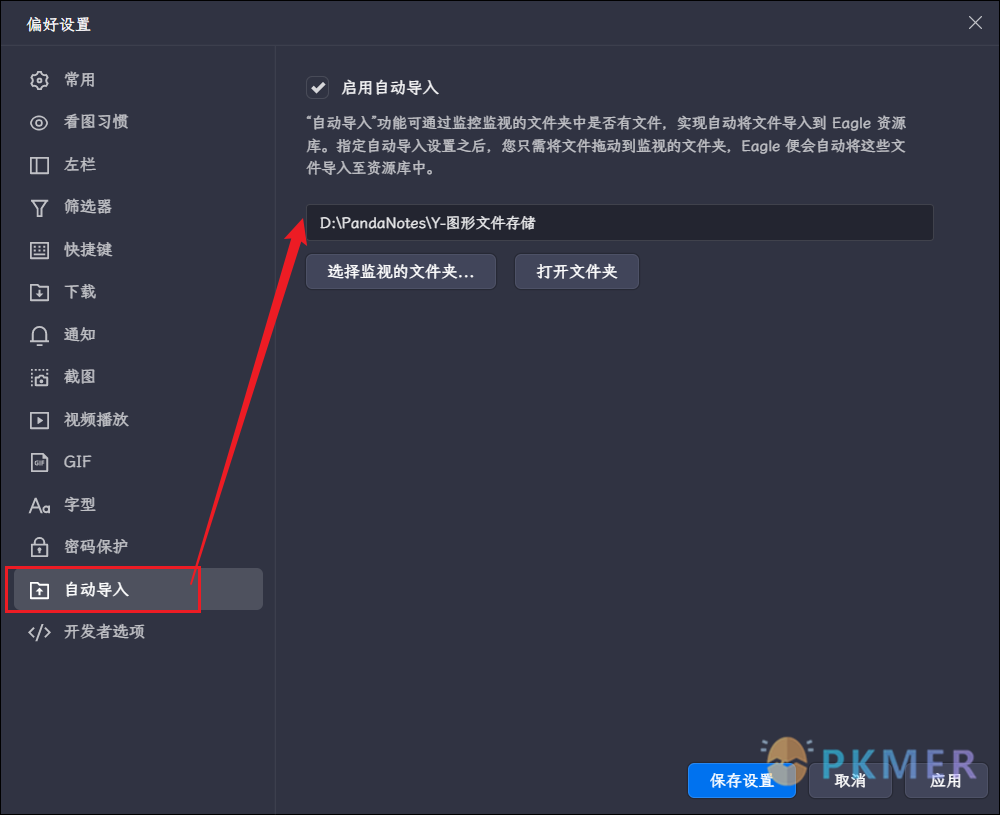
它会在该路径下生成一个文件夹为你的库名,比如我的库名为 PandaMemos,则在 D:\PandaNotes\Y-图形文件存储 路径下就会生成名为 PandaMemos 的文件夹,只要把图片放入该文件夹中,它就会自动移动图片到 Eagle 库中。
如何批量添加外部回链
Eagle 除了手动添加连接外,它图片的标签、注释、外部链接等信息一般在图片文件夹中的 metadata.json 中管理
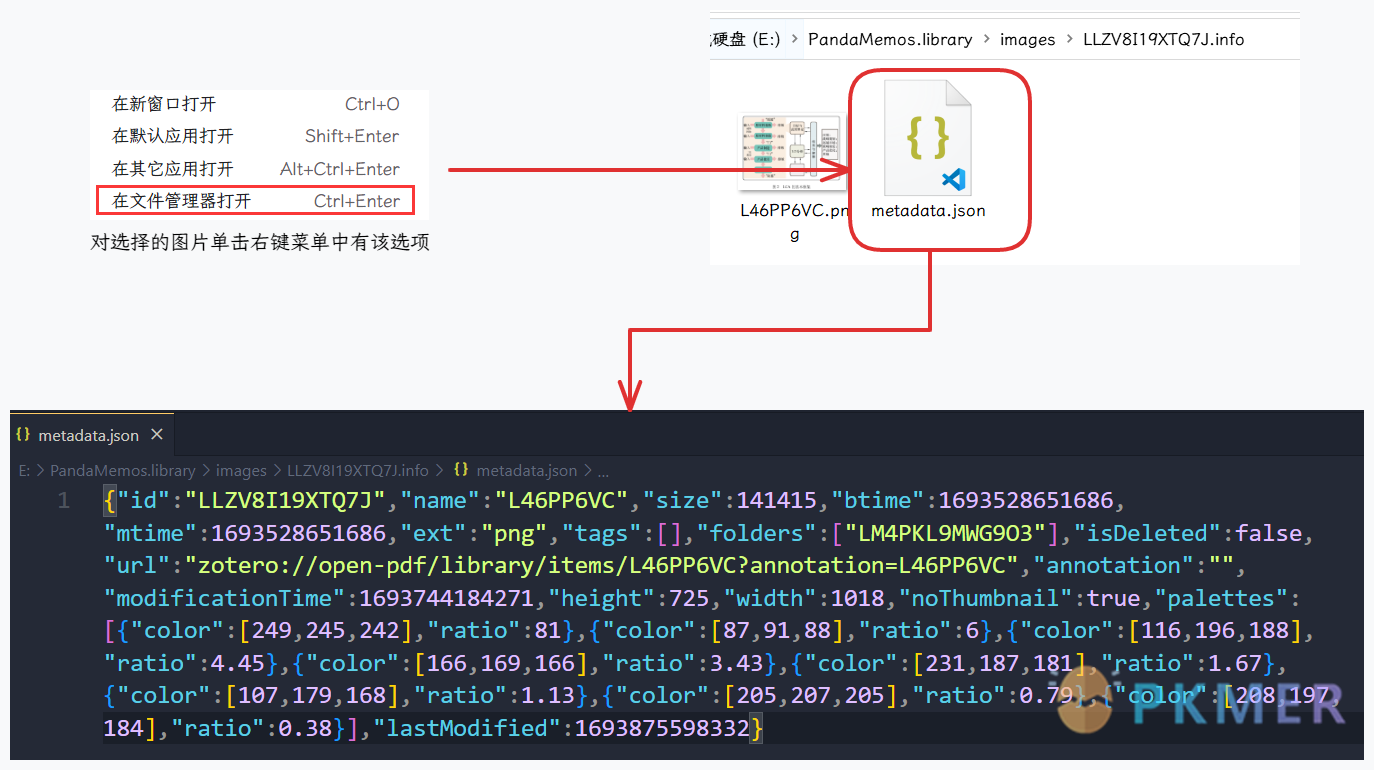
- 其中
"url":"zotero://open-pdf/library/items/L46PP6VC?annotation=L46PP6VC"就是外部回链- PS: 可以通过图片名称定位到文件夹,并在定位到图片路径后修改图片的基本信息,还可以添加外部链接。
Python 脚本的实现
综上所述,Zotero 图片的来源,以及导入 Eagle 和添加外部回链的流程就很清晰了,接下来就可以写对应的 Pytho 把 Zotero 的文献图片导入 Eagle,同时对重复的图片名选择不添加,之后等待 Eagle 导入全部的图片后,通过图片名定位到图片的文件夹路径,修改 metatable 文件,附上图链,完成任务。
第一步 检测重复图片后复制图片到 Eagle 的快速导入文件夹
# -*- coding: utf-8 -*-
"""
Created on Fri Sep 1 07:21:40 2023
@author: 熊猫别熬夜
"""
import os
import shutil
import time
import json
# 源文件夹路径
source_folder = r"D:\Zotero\cache\library"
# 目标文件夹路径
destination_folder = "D:/PandaNotes/Y-图形文件存储/PandaMemos"
# 目标文件夹路径2
eagle_folder = "E:\PandaMemos.library\images"
# 遍历source_folder文件夹,获取所有png图片的路径和文件名
zotero_pic_paths = []
zotero_pic_filenames = []
for root, dirs, files in os.walk(source_folder):
for filename in files:
if filename.endswith(".png"):
file_path = os.path.join(root, filename)
zotero_pic_paths.append(file_path)
zotero_pic_filenames.append(filename)
# 遍历eagle_folder文件夹及其子文件夹,获取所有png图片的文件名
eagle_pic_filenames = []
eagle_pic_paths= []
for root, dirs, files in os.walk(eagle_folder):
for filename in files:
if filename.endswith(".png"):
file_path = os.path.join(root, filename)
eagle_pic_paths.append(file_path)
eagle_pic_filenames.append(filename)
# 计数器变量
duplicate_count = 0
copy_count = 0
# 检查zotero_pic_filenames中的文件名是否存在于eagle_pic_filenames中,如果不存在则复制图片到destination_folder
destination_files=[]
new_copy_files=[]
for i in range(len(zotero_pic_filenames)):
if zotero_pic_filenames[i] not in eagle_pic_filenames:
source_file = zotero_pic_paths[i]
destination_file = os.path.join(destination_folder, zotero_pic_filenames[i])
new_copy_files.append(zotero_pic_filenames[i])
# print(destination_file)
shutil.copyfile(source_file, destination_file)
copy_count += 1
else:
duplicate_count += 1
# 输出重复的图片数量和复制的图片数量
print(f"重复的图片数量:{duplicate_count}")
print(f"复制的图片数量:{copy_count}")第二步 对 Zotero 和 Eagle 中具有相同名称的图片进行修改 meatdata 文件添加 Zotero 外部回链
避免有些图片没有命名上去,等你 Eagle 把图片全部导入后就可以运行这一步了。
# -*- coding: utf-8 -*-
"""
Created on Fri Sep 1 06:09:38 2023
@author: 熊猫别熬夜
"""
import os
import time
import json
# 源文件夹路径
source_folder = r"D:\Zotero\cache\library"
# 目标文件夹路径
destination_folder = "E:\PandaMemos.library\images"
# 遍历目标文件夹及其子文件夹
i=0
for root, dirs, files in os.walk(destination_folder):
for filename in files:
# 检查文件扩展名是否为PNG
if filename.endswith(".png"):
# 构建目标文件的完整路径
destination_file = os.path.join(root, filename)
# 检查源文件夹中是否存在相同名称的图片
source_file = os.path.join(source_folder, filename)
if os.path.exists(source_file):
# 输出/metadata.json文件路径
metadata_file = os.path.join(root, "metadata.json")
print(metadata_file)
i=i+1
# 读取metadata.json文件
with open(metadata_file, "r",encoding="utf-8") as file:
data = json.load(file)
# 修改"folders"的值为"LLZPQ91WQ8KFR"
pic_name=filename.split(".")[0]
zotero_url=f"zotero://open-pdf/library/items/{pic_name}?annotation={pic_name}"
data["url"] = zotero_url
# data["folders"] = ["LLZPQ91WQ8KFR"]
# 写入修改后的数据到metadata.json文件
with open(metadata_file, "w",encoding="utf-8") as file:
json.dump(data, file)
print(f"✅总计修改了{i}个metadata")个人小结
Eagle 提供了强大的标签和分类功能,让用户按需整理和归类图片素材,不过我推荐以文件夹为主,标签为辅的形式进行管理,如果检测到相同的图片,选择应用原来的图片就行了。
如果你想导入 Obsidian 进行管理的话,这里推荐 Obsidian 另一种附件管理神器 Billfish,把 Eagle 导出的素材包导入 Billfish 中时,图片回链保存。
我一开始尝试用 Billfish 来批量添加回链的,不过图片的信息不好批量添加,因此转向了 Eagle,用 Eagle 的定期的发送素材包到 Billfish 里面也算是一种方法了。
后续:2024-03-17_通过JS调用 Eagle API 来实现
这是JavaScript实现的,有Python版的,但没咋整理,就不放出来了。
const fs = require("fs");
const { it } = require("node:test");
const path = require("path");
// 获取已存在的ZoteroItems
var requestGetZoteroItems = {
method: 'GET',
redirect: 'follow',
};
const folderPath = "D:/Zotero/cache/library";
const EaglePath = "E:/PandaEagles/素材管理.library/images";
const folderId = "LMRSDNMGWH8MZ";
var requestOptions = {
method: 'POST',
redirect: 'follow'
};
fetch("http://localhost:41595/api/item/list?token=YOUR_API_TOKEN&ext=png&limit=1000", requestGetZoteroItems)
.then(response => response.json())
.then(result => {
const pngItems = Object.values(result.data.filter(data => data.ext === 'png'));
const names = pngItems.map(item => item.name);
var newItems = {
"items": [],
"folderId": folderId,
"token": requestGetZoteroItems.token,
};
var updateItems = {
"token": requestGetZoteroItems.token,
};
// 读取文件夹中的所有文件
fs.readdir(folderPath, (err, files) => {
if (err) {
console.error("无法读取文件夹:", err);
return;
}
// 遍历文件夹中的所有文件
files.forEach((file) => {
let item = {
"name": path.parse(file).name,
"website": `zotero://open-pdf/library/items/${path.parse(file).name}?annotation=${path.parse(file).name}`,
};
imagePath = path.join(folderPath, file);
if (!names.includes(item.name)) {
// 创建新的项目对象
item.path = imagePath;
newItems.items.push(item);
console.log(item.path);
} else if (names.includes(item.name)) {
oldItem = pngItems.filter(it => it.name === item.name);
item = oldItem[0];
itemPath = `${EaglePath}/${item.id}.info/${item.name}.${item.ext}`;
if (fs.statSync(imagePath).size === fs.statSync(itemPath).size) {
// console.log("文件大小相等,不进行复制");
return;
} else {
fs.copyFileSync(imagePath, itemPath);
console.log(itemPath);
updateItems.id = item.id;
requestOptions.body = JSON.stringify(updateItems);
fetch("http://localhost:41595/api/item/refreshThumbnail", requestOptions)
.then(response => response.json())
.then(result => console.log(result))
.catch(error => console.log('error', error));
}
}
});
// 如果data.items为空,则跳过添加
if (newItems.items.length !== 0) {
var requestOptions = {
method: 'POST',
body: JSON.stringify(newItems),
redirect: 'follow'
};
fetch("http://localhost:41595/api/item/addFromPaths", requestOptions)
.then(response => response.json())
.then(result => console.log(result))
.catch(error => console.log('error', error));
}
console.log("✅同步完成");
});
})讨论
若阁下有独到的见解或新颖的想法,诚邀您在文章下方留言,与大家共同探讨。

