obsidian社区插件
Obsidian 插件:Text Extractor

插件ID:text-extractor
text-extractor
text extractor:一个(伴侣)插件,用于帮助从图像(OCR)和PDF中提取文本。
Obsidian Text Extractor是一个用于从图像(OCR)和PDF中提取文本的插件。它可以与其他插件一起使用,也可以单独用于快速提取文本。支持的文件类型包括图片(.png,.jpg,.jpeg)和PDF(.pdf)。插件使用Tesseract.js和pdfextract库来提取文本,但这些库并不完美,可能无法处理某些文件。插件需要互联网连接才能工作,但所有处理都在本地完成。插件还具有缓存功能,可以将提取的文本作为本地的小型.json文件缓存,以便在多台设备间同步使用。插件提供了API,可以作为其他插件的依赖使用。
Obsidian 插件:Text Extractor
插件名片
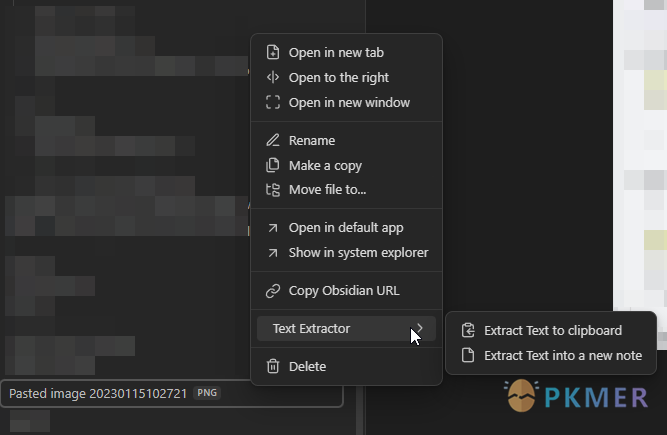
概述
Obsidian Text Extractor 是一个用于从图像(OCR)和 PDF 中提取文本的插件。它可以与其他插件一起使用,也可以单独用于快速提取文本。支持的文件类型包括图片(.png,.jpg,.jpeg)和 PDF(.pdf)。插件使用 Tesseract.js 和 pdf-extract 库来提取文本,但这些库并不完美,可能无法处理某些文件。插件需要互联网连接才能工作,但所有处理都在本地完成。插件还具有缓存功能,可以将提取的文本作为本地的小型.json 文件缓存,以便在多台设备间同步使用。插件提供了 API,可以作为其他插件的依赖使用。
Help这篇插件文章还没有人贡献,欢迎占坑!
如果您有好的想法欢迎提交 PR 或者文末留言。
讨论
若阁下有独到的见解或新颖的想法,诚邀您在文章下方留言,与大家共同探讨。

