
Obsidian 插件:【Readme】AI Research Assistant
插件名片
概述
一个用于生成式 AI 模型(如 OpenAI 的 ChatGPT)的快速工程研究实用程序,可用于存档和搜索对话,并实时编辑对话的上下文/记忆。
原文出处
下面自述文件的来源于 Readme
Readme(翻译)
下面是 ai-research-assistant 插件的自述翻译
Obsidian AI 研究助手

使用 ChatGPT API 进行 Prompt 工程的高级研究工具,构建更好的提示和 AI 集成。
注意:此插件仍在开发中,尚未被认为是完全稳定的。这是 Beta 版软件,可能包含错误和意外行为。请报告您发现的 问题,并鼓励您 贡献 给该项目。
目录:
安装
这个插件还没有在 Obsidian 社区插件目录中可用,所以你需要 手动安装 或者 通过Beta Reviewer’s Auto-update Tool (BRAT)安装。
BRAT 安装
- 安装 BRAT
- 在 BRAT 的设置中点击
添加Beta插件按钮 - 输入此存储库的 URL:
https://github.com/InterwebAlchemy/obsidian-ai-research-assistant - 在 Obsidian 的社区插件设置中启用插件
- 在 Obsidian 的设置中配置
AI Research Assistant插件
手动安装
- 下载最新的 发布版本
- 将发布版本解压到 Obsidian 存储库的
plugins文件夹中 - 在 Obsidian 的 Community Plugins 设置中启用插件
- 在 Obsidian 的设置中配置
AI Research Assistant
目前支持的模型
- OpenAI GPT-3
gpt-3.5-turbo
即将支持的模型
- OpenAI GPT-4
gpt-4
- OpenAI Legacy Completions API
gpt-3.5-turbo-instruct- 注意:此插件最初是在仅有完成 API 可用时构建的,并且是为了支持
text-davinci-003模型而构建的,但随着 OpenAI API 的最新更改,现在建议改用gpt-3.5-turbo模型,而text-daivinci-003正在被弃用,因此该功能在此插件中已被暂时禁用。
概述
该插件将 Prompt Engineering 和研究 AI 工具以及语言模型(如 OpenAI 的 ChatGPT)集成到 Obsidian 中。

它允许您手动或自动保存与 AI 模型的对话,然后使用 Obsidian 强大的搜索和标记功能来组织和分析它们。

嵌入式内存管理器允许您编辑包含在对话上下文中的消息。

它允许您在 Obsidian 中查看、搜索、标记和链接对话,并查看对话详细信息及其原始输入和输出的摘要。



特点
- 将与 AI 模型的对话自动或手动保存到 Obsidian 笔记中
- 在 Obsidian 中,对话可以进行搜索、标记和链接
- 实时编辑每个提示的上下文中使用的先前消息
- 将消息标记为核心记忆,以确保它始终在上下文中
- 将消息标记为遗忘,以确保它永远不在上下文中
- 将消息标记为记住,以优先考虑将其包含在上下文中
- 默认情况下,最近的消息更有可能被记住,而较旧的消息在接近内存和令牌限制时被遗忘
- 实时编辑用于每个对话的导言
- 实时编辑用于每个对话的提示
- 查看每个响应的原始 JSON 数据
- 查看发送给 API 的提示和上下文的每个请求
路线图
- Token-aware Memories: 在所需的令牌数量内构建记忆
- 可配置的响应令牌缓冲区: 确保 API 有足够的令牌来响应您的提示
- 模型和 API: 更多模型
- 恢复对话: 从 Obsidian 笔记中加载对话,以便从上次离开的地方继续
- 注释对话: 在保存时逐步更新笔记(而不是在每次保存时覆盖整个笔记)
- 标题生成器: 根据对话自动生成标题(如 ChatGPT)
- 移动设备支持: 在移动设备上使用 AI 研究助手
- 对话预设: 保存和加载预设配置,包括前缀、模型、导言、上下文等,以便更容易地探索不同的研究主题
- LangChain 支持: 通过 langchan.js 与 LangChain 集成
- 您想要的功能: 请求功能
命名约定
该插件使用以下命名约定来指代对话的不同部分,并确保始终清楚所指的内容:
注意:该插件区分“提示”和“前言”,因为它可以用于为没有前言的模型生成提示,在这种情况下,当单击“编辑提示”按钮时,很难区分您可能正在编辑的内容。
- 对话:这是人类和 AI 之间的持续交流。
- 前言:这是语言模型接收到的初始指令。通常是对话主题的简短描述,用于提供模型应该如何行为、模型了解什么以及如何回应的上下文。
- 值得注意的示例:
- 提示:提示是要求模型回答的问题。通常是一个句子或一个简短的段落。
- 值得注意的示例:
- 上下文:上下文是模型用于生成其回应的记忆。通常包括前言和一些先前的消息(或对其进行总结),随着对话的进行和令牌变得更加有限,较旧的消息最终会被较新的消息替换。
- 前缀:前缀被添加到提示之前,通常用于包含一个标识提示开始的起始词和一个标识发言者的句柄。
- 后缀:后缀被添加到提示之后,通常用于包含一个标识提示结束的停止词。
- 句柄:句柄是用于区分上下文中发言者的短标识符。默认情况下,该插件使用“You:”表示人类,使用“AI:”表示 AI 模型。您可以在 AI 研究助手设置中更改这些前缀。
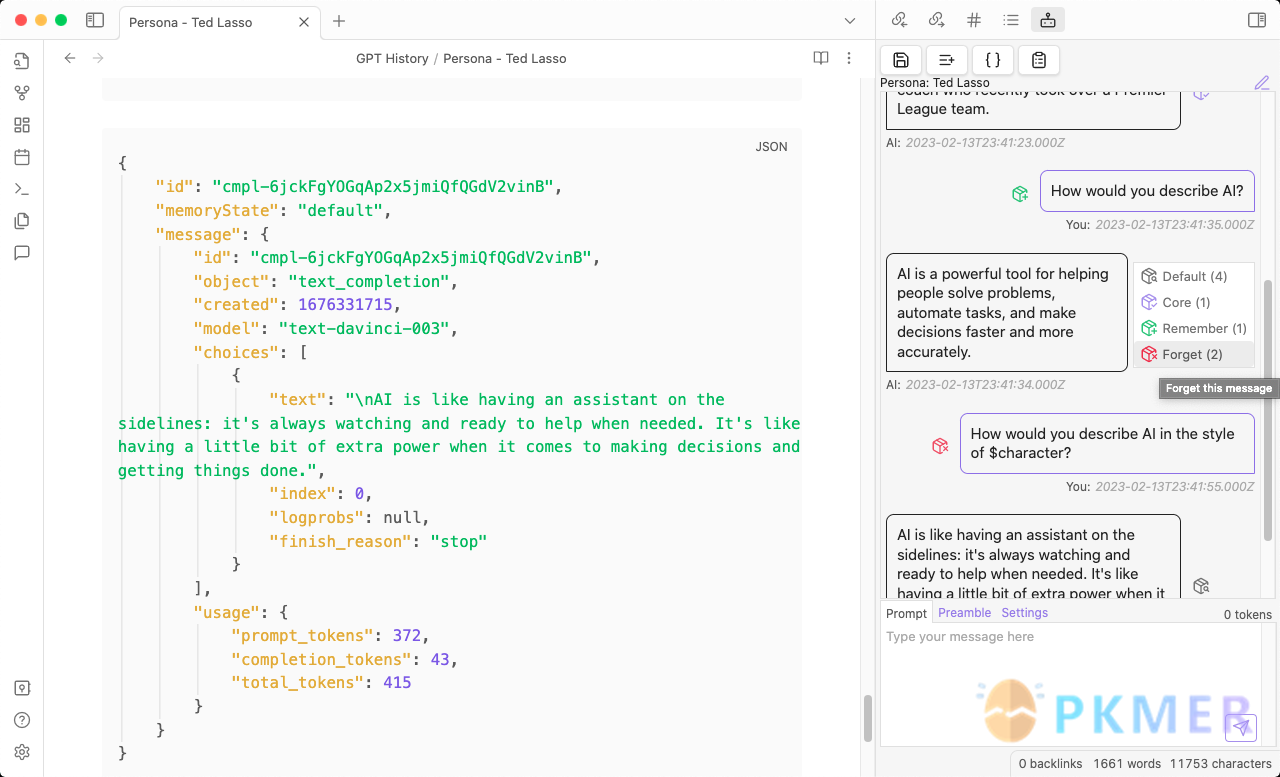
- 记忆:当启用 记忆 时,上下文是从前言和一定数量的先前消息生成的。如果启用了实验性的记忆管理器,您可以为每个提示定义先前消息的记忆状态,实时编辑上下文。 回忆
回忆给对话提供了上下文,并允许语言模型利用已经说过的内容来影响未来的回复。
有四种不同的 记忆状态,每个消息可以有其中之一:
您可以通过单击每个消息气泡旁边的记忆状态按钮,并选择一个新的状态来实时管理对话的回忆。
内存状态
- 默认: 默认情况下,消息有时会被记住(按照时间倒序),最近的记忆最有可能被记住,而较旧的记忆首先被从对话的上下文中排除。这些记忆遵循基本的先进先出(FIFO)队列。
- 核心记忆: 核心记忆始终包含在对话的上下文中。它们通常是对话中最重要的消息,并用于为模型提供一致的上下文。它们不计入插件设置中对话的最大记忆数。
- 已记住: 已记住的记忆通常包含在对话的上下文中,直到对话达到插件设置中配置的最大记忆数。它们通常是更重要的消息,但不如核心记忆重要。它们计入最大记忆数,并按照时间倒序访问。如果达到最大记忆数,最旧的已记住的记忆将不会包含在上下文中。
- 已遗忘: 已遗忘的记忆永远不会包含在对话的上下文中。您可以在对话过程中随时忘记一个记忆,并将已遗忘的记忆恢复到另一个记忆状态中。

