
Obsidian Clipper 中文翻译 (非官方)
Warning请注意,Obsidian Web Clipper 目前处于测试阶段,且至少需要 Obsidian 版本 1.7.2 才能使用。
特点
- 自定义模板:支持创建模板,自动从网页中提取并整理元数据。
- 智能触发:设置规则,根据剪辑的网站自动应用正确的模板。
- 良好的兼容性:所有剪藏都以简洁、耐用、便携的 Markdown 格式保存——无专有格式,无锁定,可脱机使用。
开始
请从您浏览器的官方扩展商店下载并安装此扩展:
- Chrome Web Store 适用于 Chrome、Brave、Edge、Arc、Orion 和其他基于 Chromium 的浏览器。
- Firefox 附加组件,用于 Firefox 和 Firefox Mobile。
- Safari扩展,用于 macOS、iOS 和 iPadOS。
如果要手动安装扩展,请访问 releases 并下载最新版本。
- Firefox:进入
about:debugging#/runtime/this-firefox,点击 Load Temporary Add-on ,然后选择.zip文件。 - Chrome:将
.zip文件拖放到chrome://extensions/中。 - Edge:将 Chrome 浏览器版本的
.zip拖放到chrome://extensions/中 - Brave:将 Chrome 浏览器版本
.zip拖放到brave://extensions/中。
在 Linux 上,确保已注册 Obsidian URI。请参阅 Obsidian 帮助文档
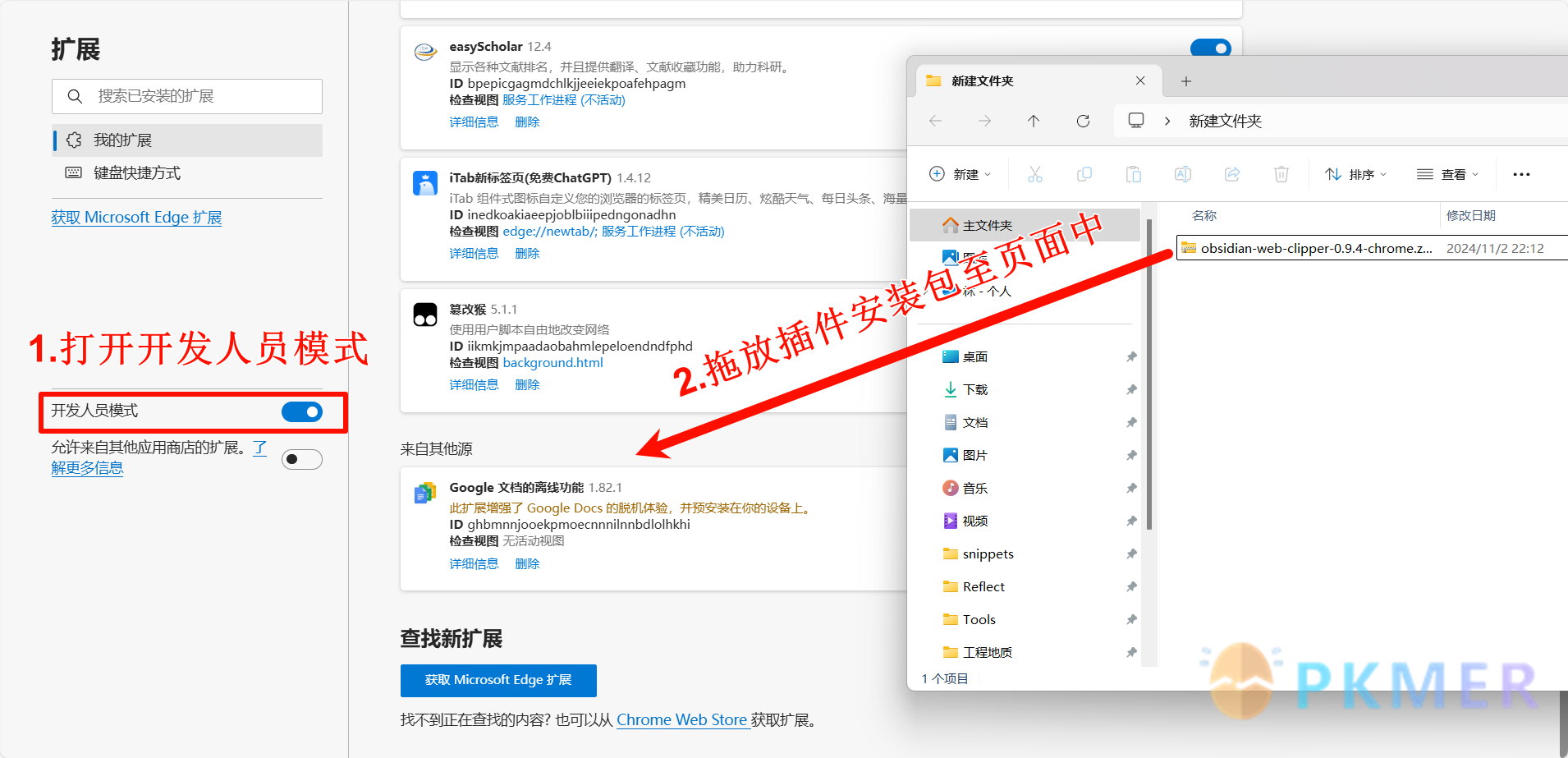
- Edge 浏览器中的简单安装步骤
模板
官方 Github 仓库中上提供了一些可用的模板。 clipper-templates repo.
以下是译者自己编写的 bilibili 视频剪藏模板,功能有限,敬请指正:
{
"schemaVersion": "0.1.0",
"name": "bilibili",
"behavior": "create",
"noteContentFormat": "---\ncreated: {{time|date:\"YYYY-MM-DD HH:mm:ss\"}}\nurl: {{url | split:\"?\" | first}}\ntitle: {{title}}\nauthor:\n - {{meta:name:author}}\ntags:\n{{selector:div.tag.not-btn-tag | list | replace:\"- \":\" - \" }}\npublished: {{selector:div.pubdate-ip-text | first}}\nduration:\nwatched: Yes/No\n---\n## Description\n\n剪藏时间:{{time|date:\"YYYY-MM-DD HH:mm:ss\"}}\n\ntype: #type/video/bilibili/new\n\ntags:\n{{selector:div.tag.not-btn-tag | list}}\n\n👉 [点击跳转视频]({{url | split:\"?\" | first}})\n\n简介:{{selector:span.desc-info-text| replace:\" \":\"\"}}\n\n| 播放量 | 弹幕量 | 点赞数 | 投硬币枚数 | 收藏人数 | 转发人数 |\n| :---: | :---: | :---: | :-----: | :----: | :----: |\n| {{selector:div.view-text | first}} | {{selector:div.dm-text | first}} | {{selector:span.video-like-info.video-toolbar-item-text | first}} | {{selector:span.video-coin-info.video-toolbar-item-text | first}} | {{selector:span.video-fav-info.video-toolbar-item-text | first}} | {{selector:span.video-share-info-text | first}} |\n\n<iframe src=\"{{url | split:'?' | first}}\" style=\"width: 100%; height: 500px;\"></iframe>\n\n## Notes\n\n",
"properties": [],
"triggers": [
"https://www.bilibili.com/"
],
"noteNameFormat": "{{title}}",
"path": "Clippings"
}效果展示:

以源码模式展示剪藏效果如下:

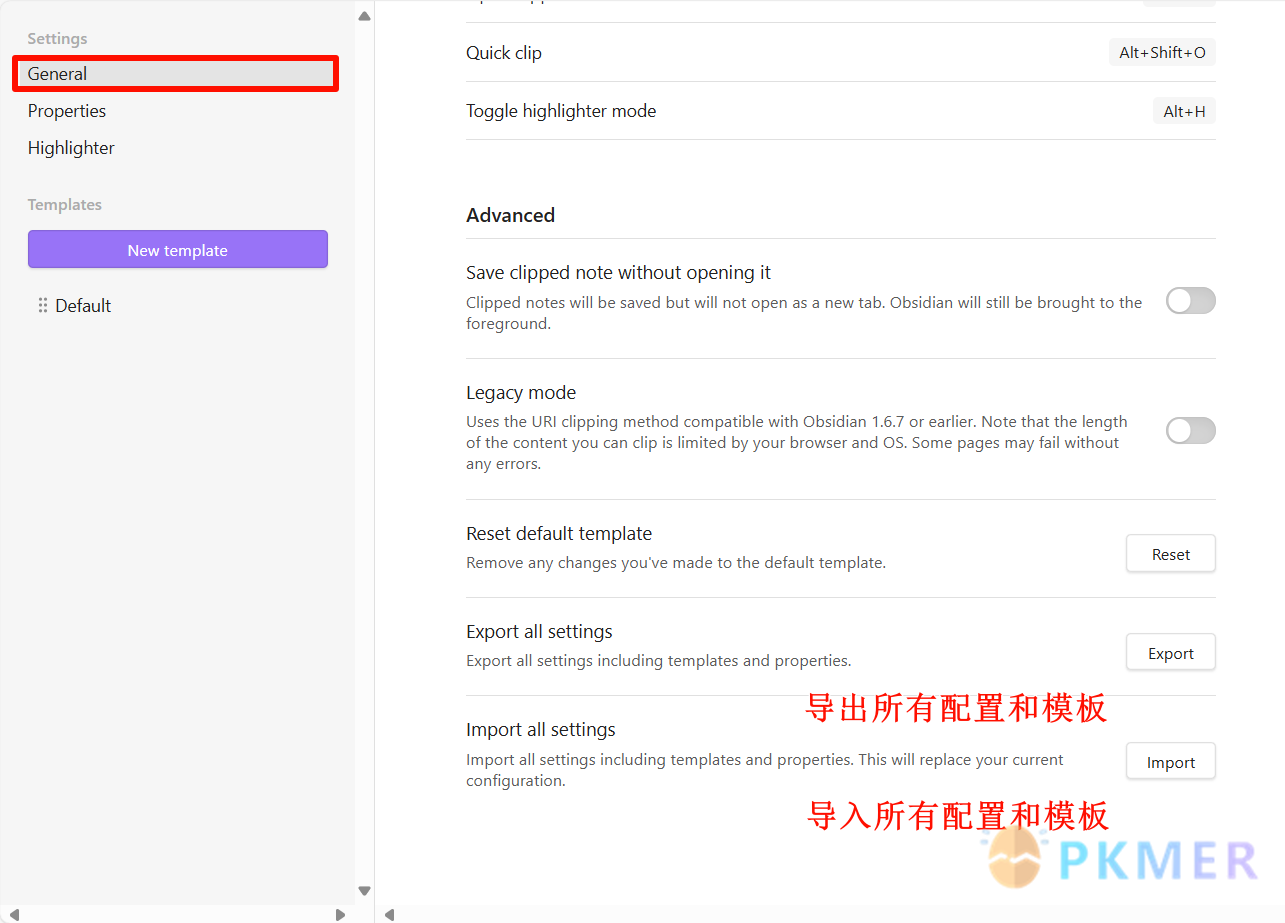
导入和导出模板
导入模板
- 打开插件,然后单击 Settings 齿轮图标。
- 转到列表中的任意模板。
- 点击右上角的 Import ,或将您的
.json模板文件拖放到模板区域的任意位置。
要导出模板,请单击右上角的 Export 。这将下载模板 .json 文件。
- 导入/导出所有配置
- 导入/导出单个模板
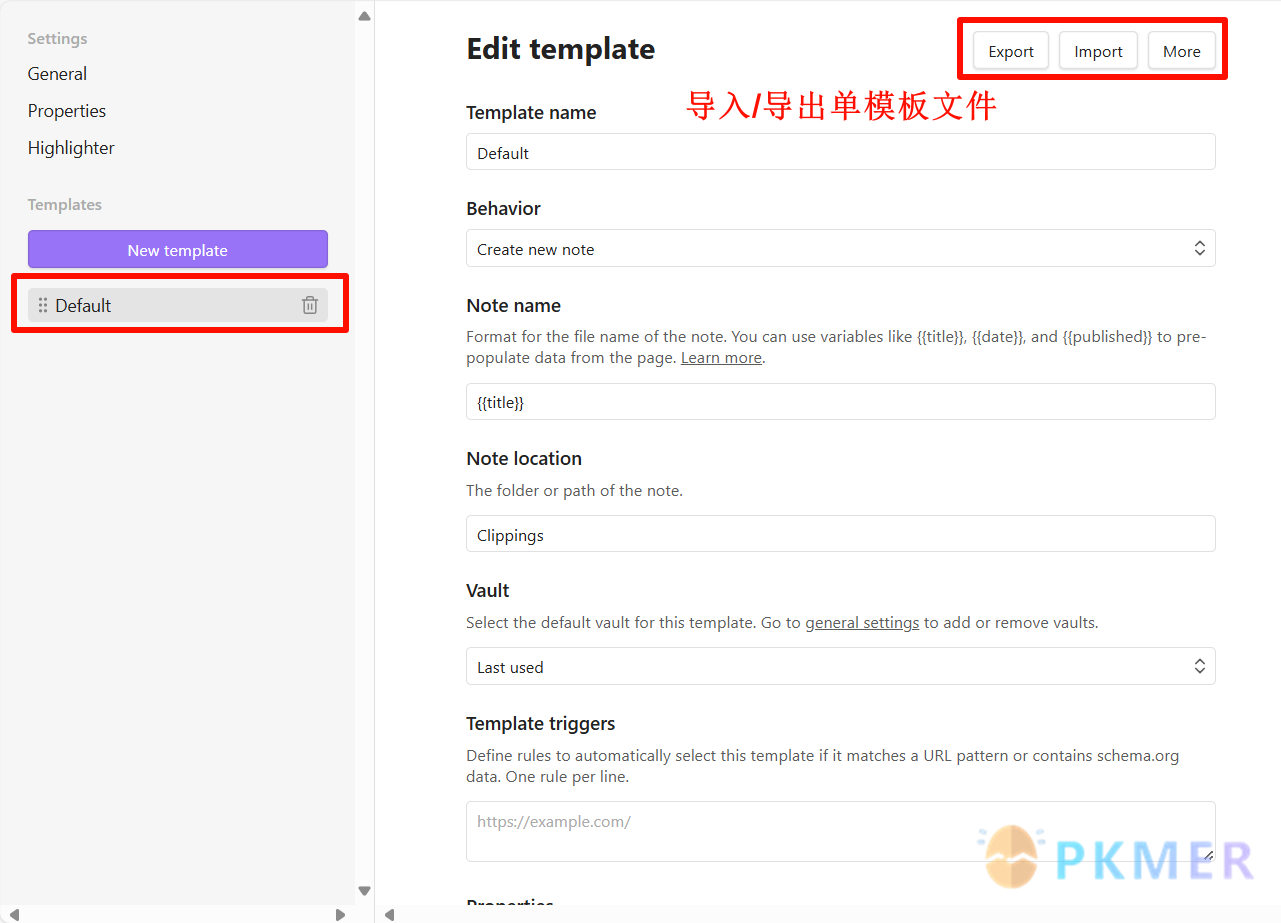
模板触发器
模板触发器允许您根据当前页面的 URL 或 schema. org 数据自动应用合适的模板。您可以为每个模板定义多个规则。
简单 URL 匹配
如果当前页面 URL 以给定模式开头,则简单匹配会触发模板。例如以下 URL:
https://obsidian.md将匹配任何以此文本开头的 URL。
正则匹配
您可以使用正则表达式根据更复杂的 URL 模式触发模板。用正斜杠 (/) 将 regex 模式括起来。记得用反斜线 (\) 转义 regex 模式中的特殊字符(如 . 和 /)。例如
/^https:\/\/www\.imdb\.com\/title\/tt\d+\/reference\/?$/将匹配任何 IMDB 参考页面。
Schema. org 匹配
您可以根据页面上的 schema. org 数据触发模板。使用 schema: 前缀,后跟要匹配的模式关键字。您可以选择指定值。例如
schema:@Recipe将匹配模式类型为 “Recipe ”的页面。schema:@Recipe.name将匹配包含@Recipe.name的页面。schema:@Recipe.name=Cookie将匹配@Recipe.name的值为 ”Cookie ” 的页面。
你可以为单个模板(template)定义多种匹配模式(patterns)。当访问一个 URL 时,会检查这个 URL 是否匹配任何一个预定义的模式。如果匹配,就会使用相应的模板来生成页面内容。
预定义变量
预定义变量会根据您访问的页面内容自动生成,这些变量适用于大多数网站。这些变量几乎适用于所有网站。主要内容变量为 {{content}},其中包含文章内容、高亮内容或选中内容(如果页面上有选中文本)。请注意,{{content}} 会尝试提取页面的主要内容,但这并不一定是你想要的样式。在这种情况下,可以使用其他预定义变量或选择器变量来提取所需的内容。
| 变量 | 说明 |
|---|---|
{{author}} | 页面作者 |
{{content}} | Markdown 格式的文章内容、高亮内容或选中内容 |
{{contentHtml}} | HTML 格式的文章内容、高亮内容或选中内容 |
{{date}} | 当前日期 |
{{description}} | 说明或摘录 |
{{domain}} | 域名 |
{{fullHtml}} | HTML 源码格式的全文内容 |
{{highlights}} | 含文字和时间戳的高亮内容 |
{{image}} | 网络图片 |
{{published}} | 发布日期 |
{{site}} | 站名或发布者 |
{{title}} | 页面标题 |
{{time}} | 当前日期和时间 |
{{url}} | 当前 URL 链接 |
元变量
元变量可让您从页面中的元标签中提取数据,包括用于社交分享预览的 Open Graph 数据。
{{meta:name}}返回指定名称的元标签的内容,例如{{meta:name:description}}返回名称为description的内容。{{meta:property}}返回指定元属性标签的内容,例如,{{meta:property:og:title}}返回属性为og:title的内容。
选择器变量
使用 {{selector:cssSelector?attribute}} 语法,选择器变量可以从页面元素中提取文本内容,其中 ?attribute 为可选语法。如果没有指定属性,则返回元素的文本内容。也可以使用 {selectorHtml:cssSelector}} 获取元素的 HTML 内容。选择器变量用于指定网站或具有一致 HTML 结构的网站上效果最好。
{{selector:h1}}返回页面中第一个h1元素的文本内容。{{selector:.author}}返回页面中第一个.author元素的文本内容。{{selector:img.hero?src}}返回第一张hero类图片的src属性。{{selector:a.main-link?href}}返回第一个类别为main-link的锚标签的href属性。{{selectorHtml:body|markdown}}返回被转换为 Markdown 格式的整个body元素的 HTML 内容。- 支持嵌套 CSS 选择器和组合器。
- 如果多个元素与选择器匹配,则会返回一个数组,可以使用
join或map等过滤器对其进行处理。
Schema. org 变量
通过 Schema 变量,可以在页面上从 schema.org JSON-LD 中提取数据。
{{schema:@Type:key}}从 schema 中返回键值。{{schema:@Type:parent.child}}返回嵌套属性的值。{{schema:@Type:arrayKey}}返回数组中的第一项。{{schema:@Type:arrayKey[index].property}}返回数组中指定索引处的值。{{schema:@Type:arrayKey[*].property}}返回数组中所有项的特定属性。
您也可以使用速记符号,而不指定 schema 模式类型:
{{schema:author}}将匹配在任何 schema 类型中的第一个author属性。{{schema:name}}将匹配任何 schema 模式类型中的第一个name属性。
如果不知道或不关心具体的 schema 类型,但知道要查找的属性名称,这种速记方法就特别有用。
嵌套属性和数组访问在指定或不指定 @Type 的情况下同样有效:
{{schema:author.name}}会找到第一个author属性,然后访问其name子属性。{{schema:author[0].name}}将返回第一个作者的name。{{schema:author[*].name}}将返回包含所有作者姓名的数组。
过滤器
过滤器允许您修改模板中的变量。使用语法 {{variable|filter}} 将过滤器应用于变量。
- 过滤器适用于任何类型的变量,包括使用
selector或schema前缀的变量。 - 过滤器可以是链式的,例如
{{variable|filter1|filter2}}会按照顺序逐步应用。
支持的过滤器语法
blockquote:为输入的每一行添加 Markdown 引用前缀 (>)。callout:创建一个 callout,参数可选:{{variable|callout:("type", "title", foldState)}}-type:callout 的类型,默认为“info”。 -title:callout 的标题,默认为空。 -foldState:布尔值,用于设置折叠状态(true 表示折叠,false 表示展开,null 表示不可折叠)。capitalize:将值的第一个字符大写,其余字符小写,例如,"hELLO wORLD"|capitalize返回"Hello world"。camel:将文本转换为“camelCase”。date:将日期转换为指定格式,见参考资料。date: "YYYY-MM-DD":将日期转换为“YYYY-MM-DD”格式。- 使用
date: ("outputFormat", "inputFormat")指定输入格式,例如,"12/01/2024"|date: ("YYYY-MM-DD", "MM/DD/YYYY")会解析“12/01/2024”并返回"2024-12-01"。
date_modify:用于修改日期值,通过增加或减去指定的时间量来实现。见参考资料。"2024-12-01"|date_modify: "+1 year"返回"2025-12-01"。"2024-12-01"|date_modify: "- 2 months"返回"2024-10-01"。
first:以字符串形式返回数组的第一个元素。["a", "b", "c"]|first返回"a"。- 如果输入不是数组,则返回内容不变的字符串。
footnote:将数组或对象转换为 Markdown 脚注列表。- 对于数组
["first item","second item"]|footnote返回:[^1]: first item等。 - 对于对象
{"First Note": "Content 1", "Second Note": "Content 2"}|footnote返回:[^first-note]: Content 1等。
- 对于数组
fragment_link:将字符串和数组转换为 文本片段 链接。默认链接文本为“link”。highlights|fragment返回Highlight content [link](text-fragment-url)。highlights|fragment: "custom title"返回Highlight content [custom title](text-fragment-url)。
image:将字符串、数组或对象转换为 Markdown 图像语法。- 对于字符串
"image. jpg"|image: "alt text"返回. - 对于数组
["image 1. jpg","image 2. jpg"]|image: "alt text"返回所有图像具有相同 alt 文本的 Markdown 图像字符串数组。 - 对于对象:
{"image 1. jpg": "Alt 1", "image 2. jpg": "Alt 2"}|image从对象键返回带有 alt 文本的 Markdown 图像字符串。
- 对于字符串
join:将数组元素合并为字符串。["a", "b", "c"]|join返回"a, b, c"。- 可以自定义分隔符:
["a", "b", "c"]|join: " "返回"a b c"。 - 它可以用在
split或slice之后:"a, b, c, d"|split: ","|slice: 1,3|join: ""返回"b c"。
kebab:将文本转换为“kebab-case”格式。last:以字符串形式返回数组的最后一个元素。["a", "b", "c"]|last返回"c"。- 如果输入不是数组,则原样返回数据。
link:将字符串、数组或对象转换为 Markdown 链接语法(不要与 wiki 链接混淆)。- 对于字符串
"url"|link: "author"返回[author](url)。 - 对于数组
["url 1", "url 2"]|link: "author"返回所有链接中包含指定文本的 Markdown 格式链接数组。 - 对于对象
{"url 1": "Author 1", "url 2": "Author 2"}|link返回文本与指定关键字匹配的 Markdown 格式链接。
- 对于字符串
list:将数组转换为列表。- 使用
list:task将数组转换为任务列表。 - 使用
list:numbered转换为有序列表。 - 使用
list: numbered-task转换为有序的任务列表。
- 使用
lower:将字符串转换为小写。map:对数组的每个元素进行转换。- 语法:
map: item => item. property或map: item => item. nested. property用于嵌套属性。- 例如:
[{gem: "obsidian", color: "black"}, {gem: "amethyst", color: "purple"}]|map: item => item. gem返回["obsidian", "amethyst"]。
- 例如:
- 对象字面量和复杂表达式需要使用括号:
map: item => ({key: value})。- 例如:
[{gem: "obsidian", color: "black"}, {gem: "amethyst", color: "purple"}]|map: item => ({name: item. gem, color: item. color})返回[{name: "obsidian", color: "black"}, {name: "amethyst", color: "purple"}]。
- 例如:
- 支持字符串字面量,并自动封装在具有
str属性的对象中:- 例如:
["rock", "pop"]|map: item => "genres/${item}"返回[{str: "genres/rock"}, {str: "genres/pop"}]。 str属性可用于存储字符串字面转换的结果。
- 例如:
- 可与
template过滤器结合使用,例如map: item => ({name: ${item. gem}, color: item. color})|template: "- ${name} is ${color}\n"。
- 语法:
markdown:将字符串转换为 Obsidian Flavored Markdown 格式化字符串。- 与返回 HTML 的变量(如
{{contentHtml}}、{{fullHtml}})和选择器变量(如{{selectorHtml:cssSelector}})结合使用时非常有用。
- 与返回 HTML 的变量(如
object:操作对象数据:object:array:将对象转换为键值对数组。object:keys:返回对象键值的数组。object:values:返回对象值的数组。- 例如:
{"a": 1, "b": 2}|object:array返回[["a", 1], ["b", 2]]。
pascal:将文本转换为“PascalCase”格式。remove_html:从字符串中删除指定的 HTML 元素及其内容。- 支持标签名称、类或 id,例如
{{content|remove_html:("img,.class-name,#element-id")}}。 - 只删除 HTML 标记或属性而不删除内容,使用
strip_tags或strip_attr过滤器。
- 支持标签名称、类或 id,例如
replace:替换指定字符串:- 简单替换:
"hello!"|replace: ",": ""移除所有逗号。 - 多重替换:
"hello world"|replace: ("e": "a", "o": "0")返回“hall 0 w 0 rld”。 - 将按照指定的顺序逐次替换。
- 要替换为空字符串,请使用
""作为替换值。 - 特殊字符包括
: | { } ( ) ' "在使用时应使用反斜杠转义,例如,\:来匹配冒号。
- 简单替换:
round:将数字四舍五入到最接近的整数或指定的小数位数。- 不带参数:
3.7|round返回4。 - 如果指定了小数位数:
3.14159|round:2返回3.14。
- 不带参数:
safe_name:会对文件名”消毒“,即清理字符串,确保其不包含任何可能使文件名无效或引起冲突的字符。- 默认情况下,
safe_name采用最保守的消毒规则。 - 特定操作系统的用法:
safe_name:os其中os可以是windows、mac或linux以仅应用该操作系统的规则。
- 默认情况下,
slice:对字符串或数组切片。- 对于字符串
"hello"|slice: 1,4返回"ell"。 - 对于数组
["a", "b", "c", "d"]|slice: 1,3返回["b", "c"]。 - 如果只提供一个参数,则从该索引开始切到末尾:
"hello"|slice:2返回"lo"。 - 负数索引从末尾开始计数:
"hello"|slice:-3返回"lo"。 - 第二个参数是排他的:
"hello"|slice: 1,4包括索引 1、2 和 3 的字符。 - 使用负数的第二个参数会排除末尾的元素:
"hello"|slice: 0,-2返回"hel"。
- 对于字符串
snake:将文本转换为snake_case格式。split:将字符串分割成子串数组。"a, b, c"|split: ","返回["a", "b", "c"]。"hello world"|split: " "返回["hello", "world"]。- 如果没有提供分隔符,则会对每个字符进行分割:
"hello"|split返回["h", "e", "l", "l", "o"]。 - 正则表达式可用作分隔符:
"a 1 b 2 c 3"|split:[0-9]返回["a", "b", "c"]。
strip_attr:删除字符串中的所有 HTML 属性。- 使用
strip_attr: ("class, id")可保留特定属性。 - 例如:
"<div class="test" id="example">Content</div>"|strip_attr: ("class")返回<div id="example">Content</div>。
- 使用
strip_md:移除所有 Markdown 格式化并返回纯文本字符串,例如将**text**变成text。- 转化为无格式化的纯文本,包括粗体、斜体、高亮、标题、代码、引号、表格、任务列表和 wiki 链接。
- 完全删除表格、脚注、图像和 HTML 元素。
strip_tags:删除字符串中的所有 HTML 标记。与remove_html不同,它不会删除标签中的内容。- 使用
strip_tags: ("p, strong, em")可以保留特定的标记。 - 例如:
"<p>Hello <b>world</b>!</p>"|strip_tags: ("b")返回Hello <b>world</b>!。
- 使用
table:将数组或对象数组转换为 Markdown 表格:- 对于对象数组,它会使用对象键作为标题。
- 对于数组,它会创建一个以每个嵌套数组为一行的表格。
- 对于简单数组,它会创建一个以 “值” 为标题的单列表格。
template:将模板字符串应用于对象或对象数组。- 语法:
object|template: "Template with ${variable}"。 - 访问嵌套属性:
{"gem":{"name": "Obsidian"}}|template: "${gem. name}"返回"Obsidian"。 - 对于对象:
{"gem": "obsidian","hardness": 5}|template: "${gem} has a hardness of ${hardness}"返回"obsidian has a hardness of 5"。 - 对于数组
[{"gem": "obsidian", "hardness": 5},{"gem": "amethyst", "hardness": 7}]|template:“- ${gem} has a hardness of ${hardness}\n”返回格式化后的列表。 - 通过访问
str属性,可以处理map中的字符串字面量:- 例如:
["rock", "pop"]|map: item => "genres/${item}"|template: "${str}"返回"genres/rock\ngenres/pop"。 - 将
template应用于由map创建的以字符串为字面形式的对象时,会自动使用str属性。
- 例如:
- 语法:
title:将返回值标题化,例如,“hello world”|title返回“Hello World”。trim:会删除字符串两端的空白。" hello world"|trim返回"hello world"。
uncamel:将 camelCase 或 PascalCase 转换为空格分隔的单词,可以使用其他筛选器(如title或capitalize)进一步格式化这些单词。"camelCase"|uncamel返回"camel case"。"PascalCase"|uncamel返回"pascal case"。
upper:转换为大写,例如,“hello world”|upper返回“HELLO WORLD”。wikilink:将字符串、数组或对象转换成 Obsidian wiki 链接。- 对于字符串
page"|wikilink返回[[page]]。 - 对于带别名的字符串:
"page"|wikilink: "alias"返回[[page|alias]]。 - 对于数组:
["page 1", "page 2"]|wikilink返回不带别名的维基链接数组。 - 对于有别名的数组:
["page 1", "page 2"]|wikilink: “alias”返回一个包含维基链接(wikilinks)的数组,并且这些链接都使用了相同的别名(alias)。 - 对于对象:
{"page 1": "alias 1", "page 2": "alias 2"}|wikilink返回键为页面名称、值为别名的维基链接。
- 对于字符串
构建插件
npm run build执行此命令后,将生成三个目录,分别用于不同浏览器版本的插件:
dist/用于 Chromium 版本dist_firefox/用于 Firefox 版本dist_safari/用于 Safari 版本
在 Chrome、Brave、Edge 和 Arc 中安装
- 打开你的浏览器,导航到
chrome://extensions - 启用 开发者模式
- 点击 加载已解压的 并选择
dist目录
在 Firefox 中安装
- 打开 Firefox 并导航到
about: debugging #/runtime/this-firefox - 点击 Load Temporary Add-on
- 导航到
dist_firefox目录并选择manifest. json文件
第三方库
- webextension-polyfill 感谢 Mozilla 提供此库,它确保了我们的插件能够在不同的浏览器上保持兼容性。
- readability 感谢 Mozilla 开发的 readability 库,它帮助我们从网页中提取有价值的内容。
- turndown 感谢 mixmark-io 为我们提供了 turndown 库,它使得 HTML 到 Markdown 的转换变得简单快捷。
- dayjs 感谢 iamkun 开发的 dayjs 库,它让我们能够轻松地解析和格式化日期。
- lz-string 感谢 pieroxy 为我们提供了 lz-string 库,它通过压缩模板帮助我们节省了存储空间。
- lucide 感谢 lucide-icons 团队提供的精美图标库,它让我们的插件界面更加直观和吸引人。
- mathml-to-latex 感谢 asnunes 开发的 mathml-to-latex 库,它使得 MathML 到 LaTeX 的转换变得轻松,为科学和数学内容的转换提供了强大支持。
讨论
若阁下有独到的见解或新颖的想法,诚邀您在文章下方留言,与大家共同探讨。

