obsidian社区插件
Latex OCR

插件ID:latex-ocr
latex-ocr
latex ocr:识别剪切板中的图片中的数学公式并且转换为 latex
Latex OCR for Obsidian是一个插件,可以从你的vault或剪贴板中的图像生成LaTeX方程。用户可以直接将LaTeX方程粘贴到笔记中,使用剪贴板中的图像,并通过上下文菜单中的"生成LaTeX"选项将vault中的图像转换为LaTeX方程。可以使用HuggingFace推断API或在本地运行。用户可以手动安装插件,也可以使用BRAT自动安装。此外,插件还介绍了如何使用推断API和如何在本地运行模型。插件还提供了GPU支持,并感谢NormXU为训练和发布模型所做的贡献。插件解决了从图像中生成LaTeX方程的问题,适用于需要在Obsidian笔记中使用LaTeX方程的用户。
Latex OCR
插件名片
- 插件名称:Latex OCR
- 插件版本:0.6.5
- 插件作者:Lucas Van Mol
- 插件描述:识别剪切板中的图片中的数学公式并且转换为 latex
- 插件项目地址:点我跳转
- 体验下来速度比 ocrlatex 慢了许多(十来秒),但是它可以本地配置模型,无需联网使用
- 可以日常联网时用 orclatex,无网时用 Latex OCR
- 插件在选用本地模型之后无法切换回使用在线模型,可能是 BUG,重装插件恢复即可
使用方法
需要配置完成后才可以使用,配置方法在下一节中给出,这里先给出详细的使用方法
- 插件是识别剪切板中的图片,因此需要先复制一张想要识别有公式的图片
- 光标放到笔记中想要插入公式的地方,打开命令面板(快捷键 ctrl+p)
- 搜索命令 Latex OCR: Paste Latex from clipboard image
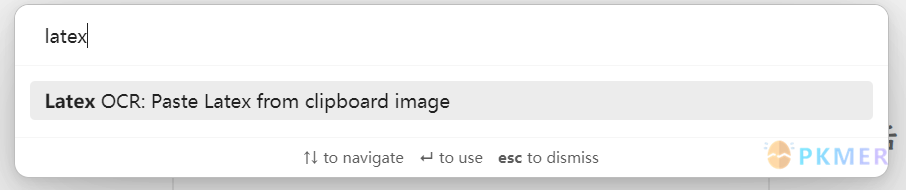
使用该命令,正文中出现以下内容代表正在 ocr

等待一会(第一次使用需要一点时间预配会久一点,十来秒左右,后续会快一些)

配置
插件有两种使用方法,二选一即可
- 使用 HuggingFace 的 API,需要联网使用
- 使用本地 python 模型识别,无需联网
Hugging Face API
在 https://huggingface.co 创建一个个人账号,在个人资料设置中创建 token(或者点击 Hugging Face profile settings 直达)
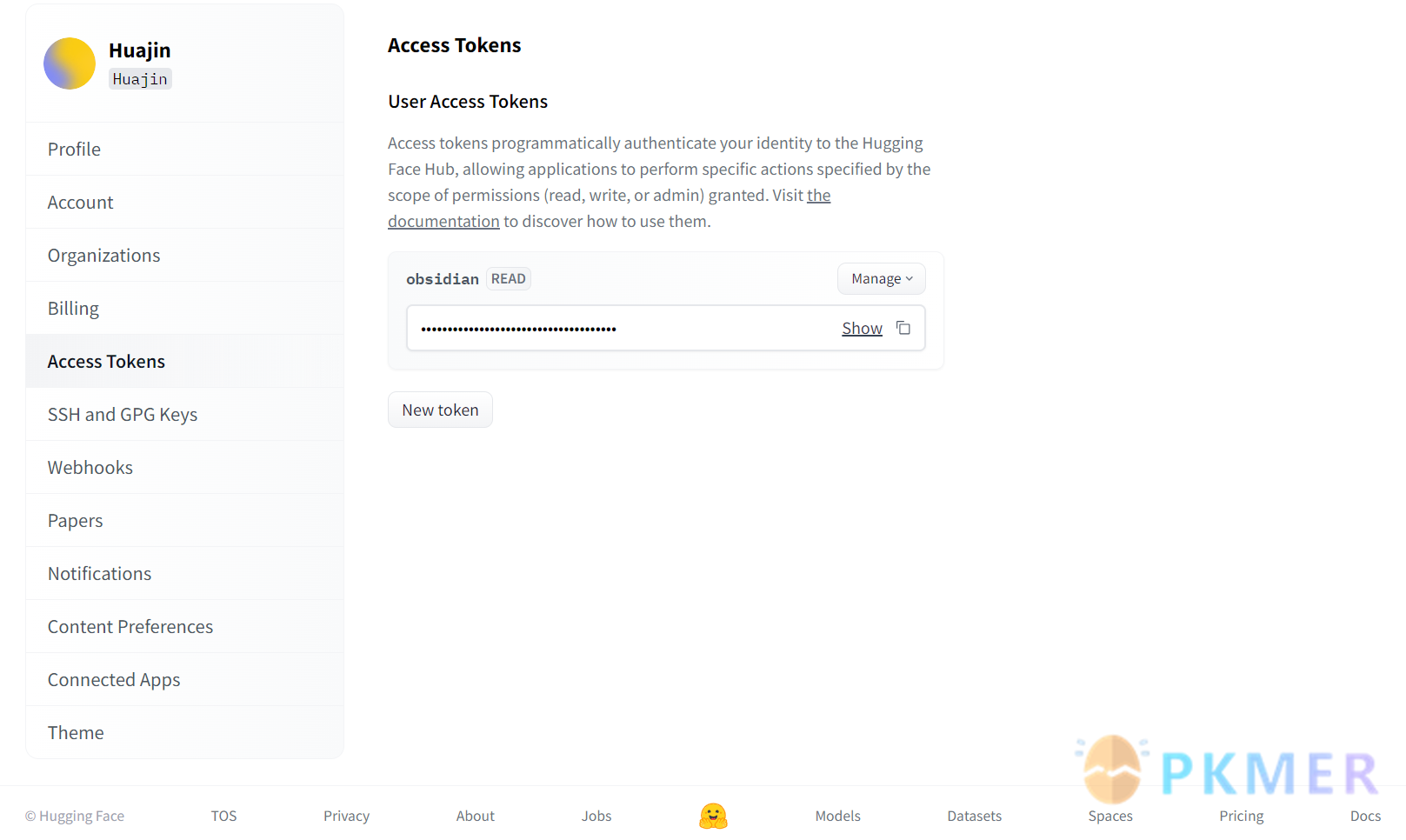
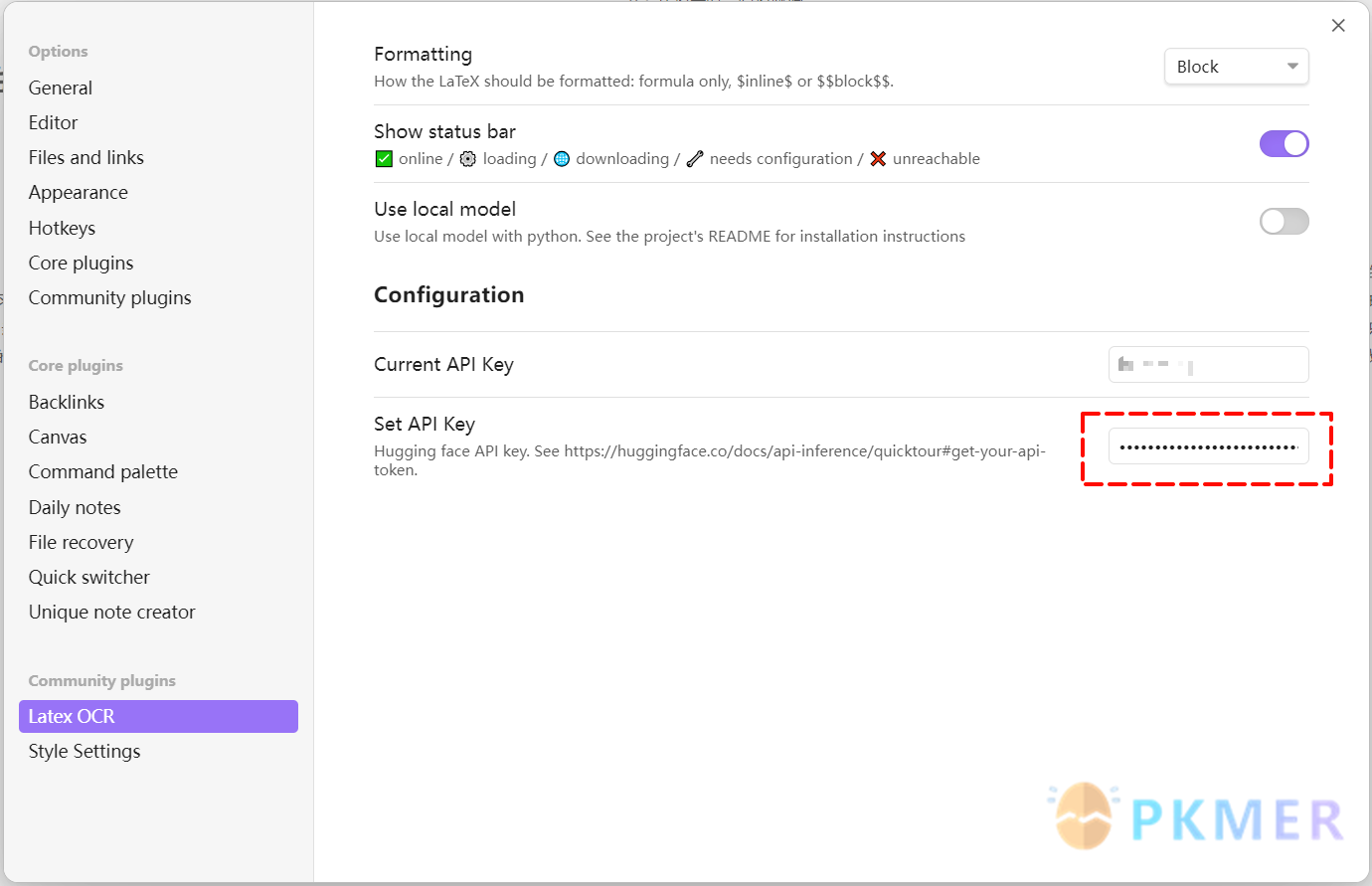
复制 token 到插件设置的 Set API KEY 选项后配置完成
Python 配置
如果你不想要联网使用,可以用本地模型,需要事先按照 python 包(不了解 mac,下面给出在 win 中的操作方法)
在 cmd 中输入
pip install https://github.com/lucasvanmol/latex-ocr-server/releases/download/0.1.0/latex_ocr_server-0.1.0-py3-none-any.whl可以用下面的命令检验是否安装成功
python -m latex_ocr_server --version可以用以下命令卸载该包
pip uninstall latex_ocr_server安装完 python 包后,进行插件的配置
- 第一步:打开 Use local model 设置
- 第二步:填入 python 的安装路径(path to python.exe)
注意
在第一次执行第二步的时候会从 hugging face 下载模型,此时需要确保联网。模型大小约 1.4 GB,由 NormXU/nougat-latex-oc 训练
下载的模型会保存在你的库的插件文件夹中。如果不想让库变得很大,可以在插件设置的选项 Cache dir 中改变模型保存的路径,记得改变路径后删除库中的模型(如果你下载了)
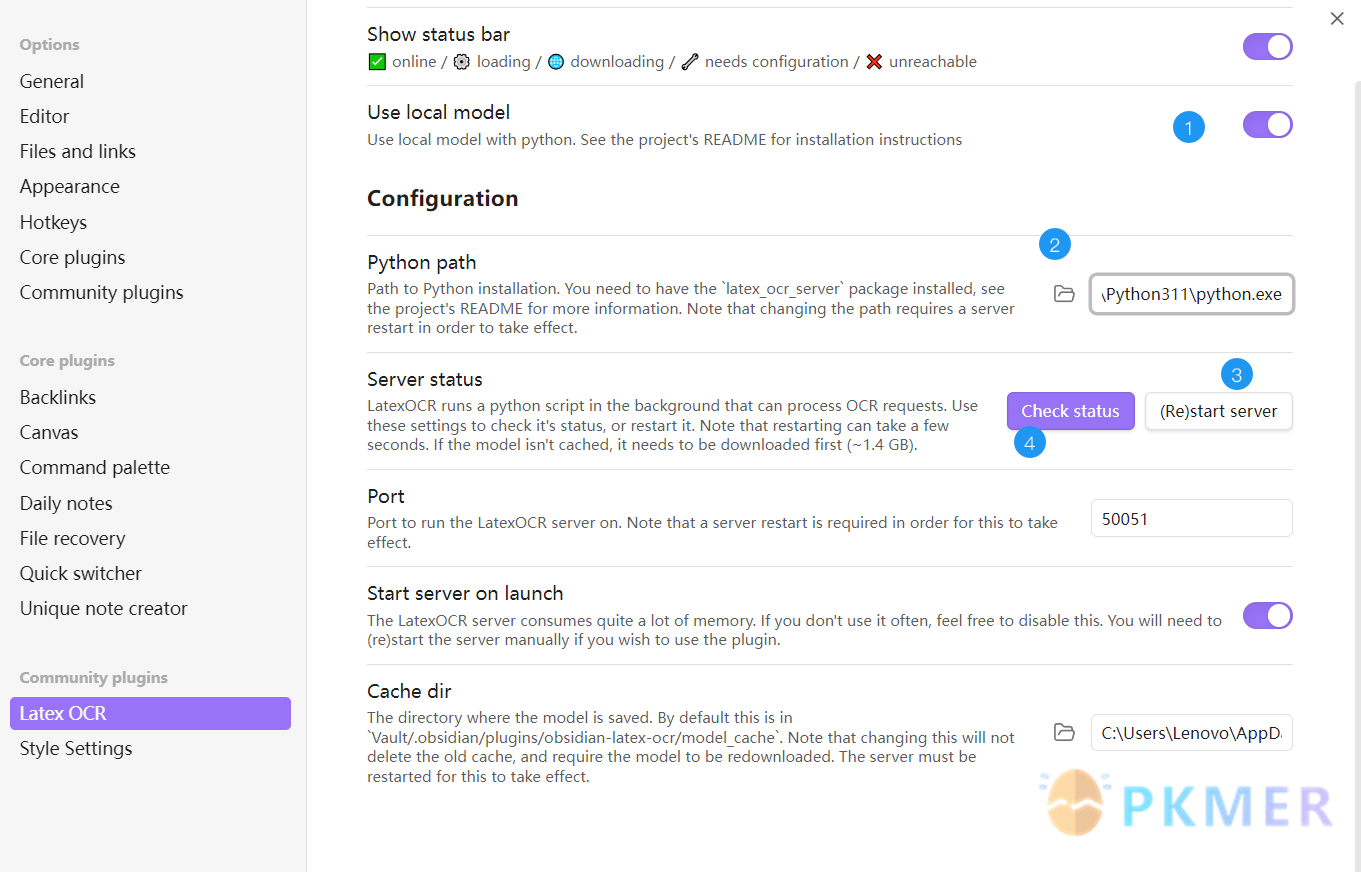
- 第三步:点击下一项 (Re)start server(每次更新 python 路径都需要点击重启服务)
- 第四步:可以点击 Check status 检查是否成功
可以从底部状态栏查看当前服务器状态
| Status 状态 | Meaning 意义 | 中文 |
|---|---|---|
| LatexOCR ✅ | server online | 服务器在线 |
| LatexOCR ⚙️ | server loading | 服务器加载 |
| LatexOCR 🌐 | downloading model | 下载模型 |
| LatexOCR ❌ | server unreachable | 服务器无法访问 |
可以使用 GPU 加速模型识别公式,用以下命令检查 GPU 是否正常工作
python -m latex_ocr_server info --gpu-available如果你没有安装 GPU,可以按照 CUDA 按照 pytorch 的 说明 进行操作,网上也有许多按照 GPU 的教程。注意,你可能需要先卸载 torch,插件不需要使用 torchvision 和 torchaudio
讨论
若阁下有独到的见解或新颖的想法,诚邀您在文章下方留言,与大家共同探讨。

