
自定义 Excalidraw 脚本 - 实现 Excalidraw 与 BookxNote 的联动
背景
继 Quicker动作之BookxNote和Obsidian联动 后,我发布了一篇 自定义Excalidraw脚本-实现Zotero与Excalidraw的拖拽联动 的文章和视频,是通过 Excalidraw 的脚本实现 Zotero 和 Obsidian 的 Excalidraw 的拖拽无缝连接,效果还不错。不过对于书籍类的长文 PDF,Zotero 还是有点不方便,最后还是选择用 BookxnotePro 来进行阅读,所以针对 Bookxnote 也写了一个对应的 BookxnoteToExcalidraw 脚本。
效果

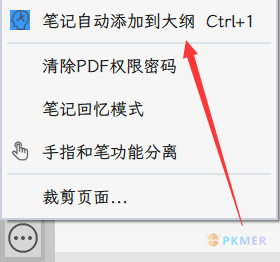
Caution该脚本只能提取 BookxNote 笔记大纲里面的信息,如果显示
未匹配到标注信息,则该笔记信息不在笔记大纲内,可以设置笔记自动添加到大纲:
脚本的制作思路
按理说 BookxnotePro 也可以直接通过 Excalidraw 脚本来实现,但一直拖着没去实现,主要 Bookxnote 的数据存储有一点绕,比如这是一个 BookxnotePro 的外部链接:
bookxnotepro://opennote/?nb={ede53699-7b48-4be3-b42c-4aa08bd30ce1}&book=5bde5735bd629aef922f076220efd624&page=49&x=198&y=551&id=181&uuid=0b87d2be8c8b85663d2fd23264e4c866- nb:
{ede53699-7b48-4be3-b42c-4aa08bd30ce1} - book:
5bde5735bd629aef922f076220efd624 - uuid:
0b87d2be8c8b85663d2fd23264e4c866
包含了 nb、book、uuid 的 3 个信息 ID,让我们简单看看这 3 个信息 ID 分别对应什么。
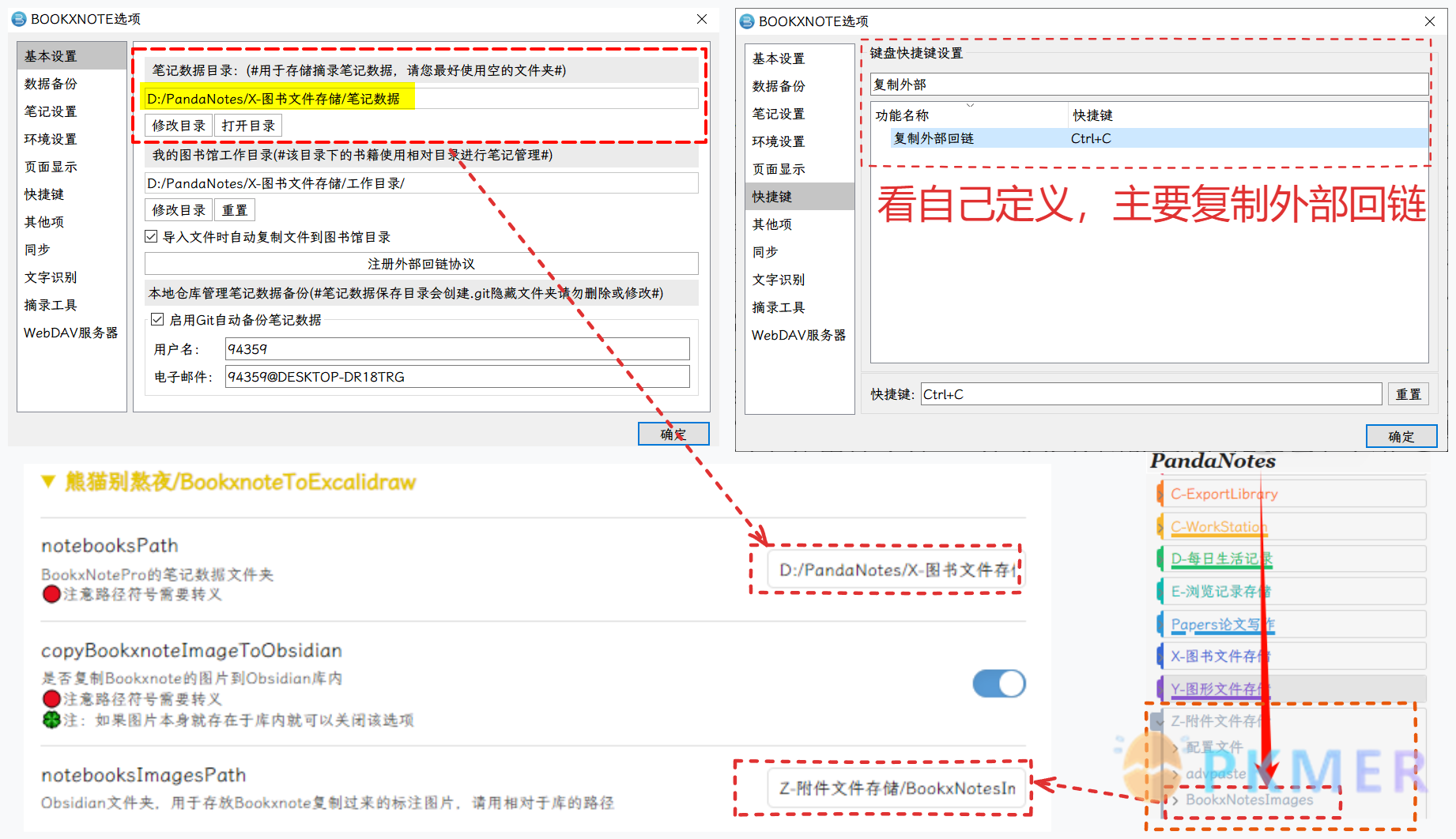
首先找到 Bookxnote 的笔记数据目录所在的文件夹,在 Bookxnote 选项的基本设置里面:
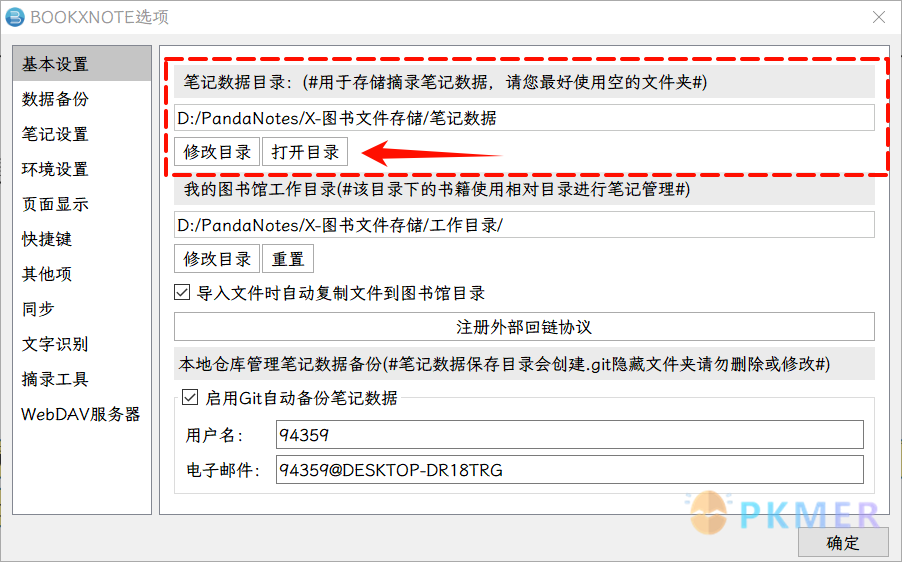
打开可以发现里面有几个数据文件,都是用来存储 Bookxnote 软件设置的文件,有最近阅读记录 recentnotes.json 和用户设置 user_config.json。
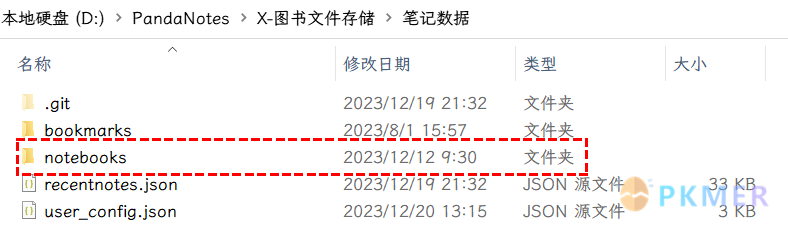
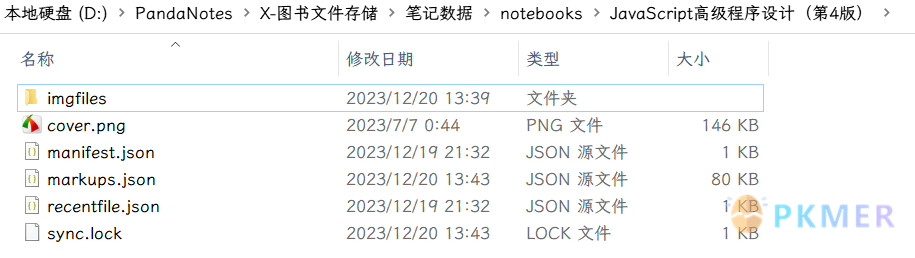
其中 notebooks 文件夹才是我们这次主要关注的对象,也是所有书本笔记数据存储位置,里面有许多的 PDF 对应的文件夹,还有 3 个 JSON 数据文件,manifest.json 里面就存储着所有数据的基本信息:
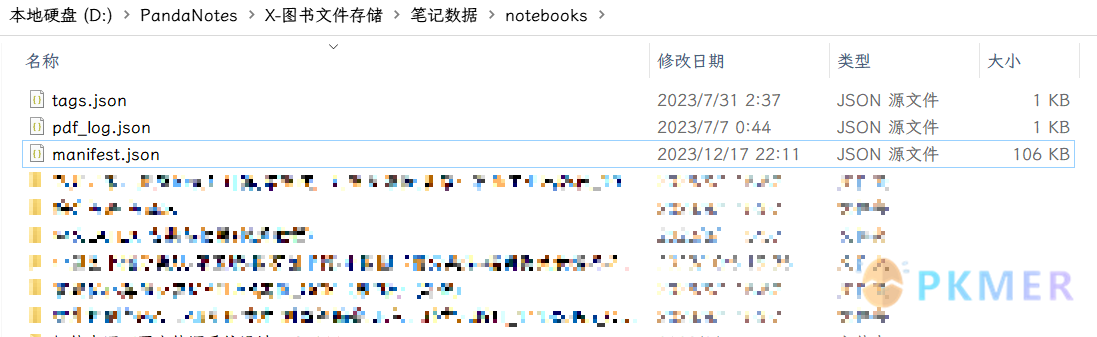
在里面我们就可以找到我们 nb 对应的 ID 值:
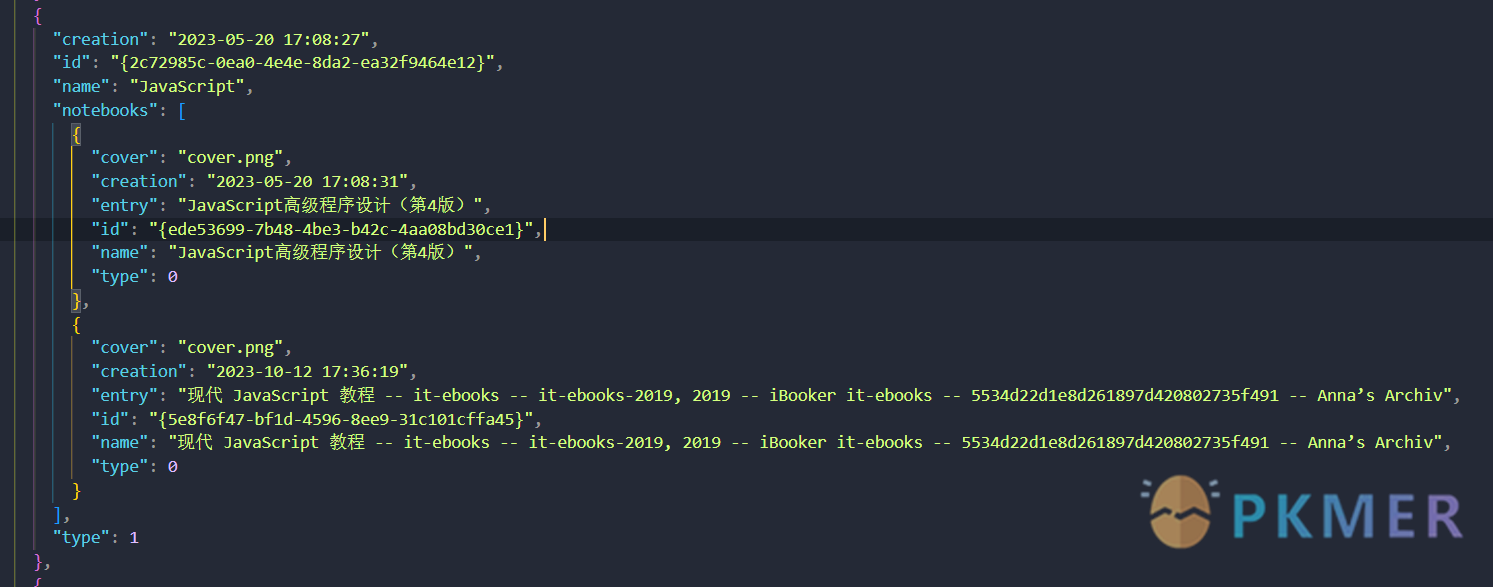
有 nb 的 ID 值我们可以找到 entry 就是 notebook 文件下方对应书籍的文件夹名称,即我们可以从 Bookxnote 的笔记目录数据通过 nb 查找到 PDF 对应的文件夹名称从而推出对应的笔记数据文件夹。
这里面 markups.json 文件就存储所有在 PDF 标注的信息,可以通过 uuid 来找到对应的值:
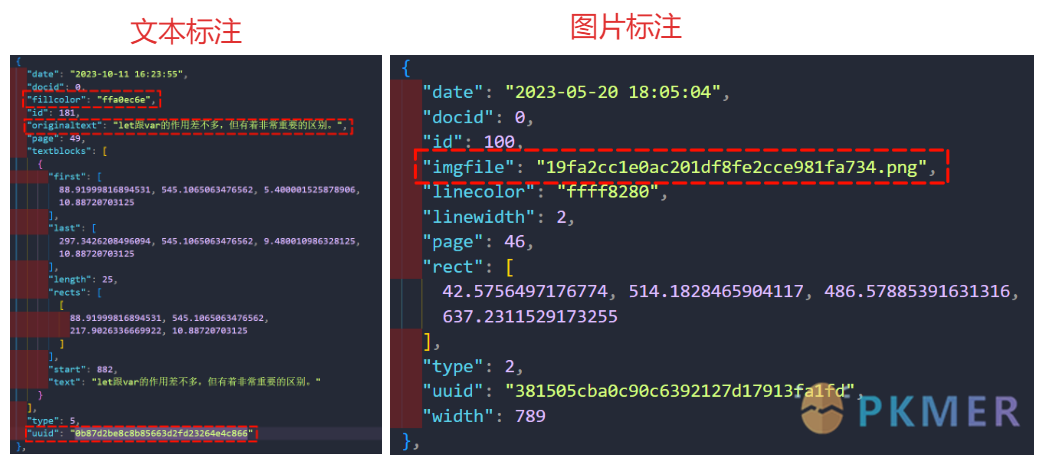
可以发现图片标注和文字标注的结构是不一样的,主要区别就是 imgfile
和 originaltext 的信息的不同,可以通过是否存在 imgfile 来判断标注信息类型,fillcolor 信息可以用来给复制过来的文本添加背景颜色。
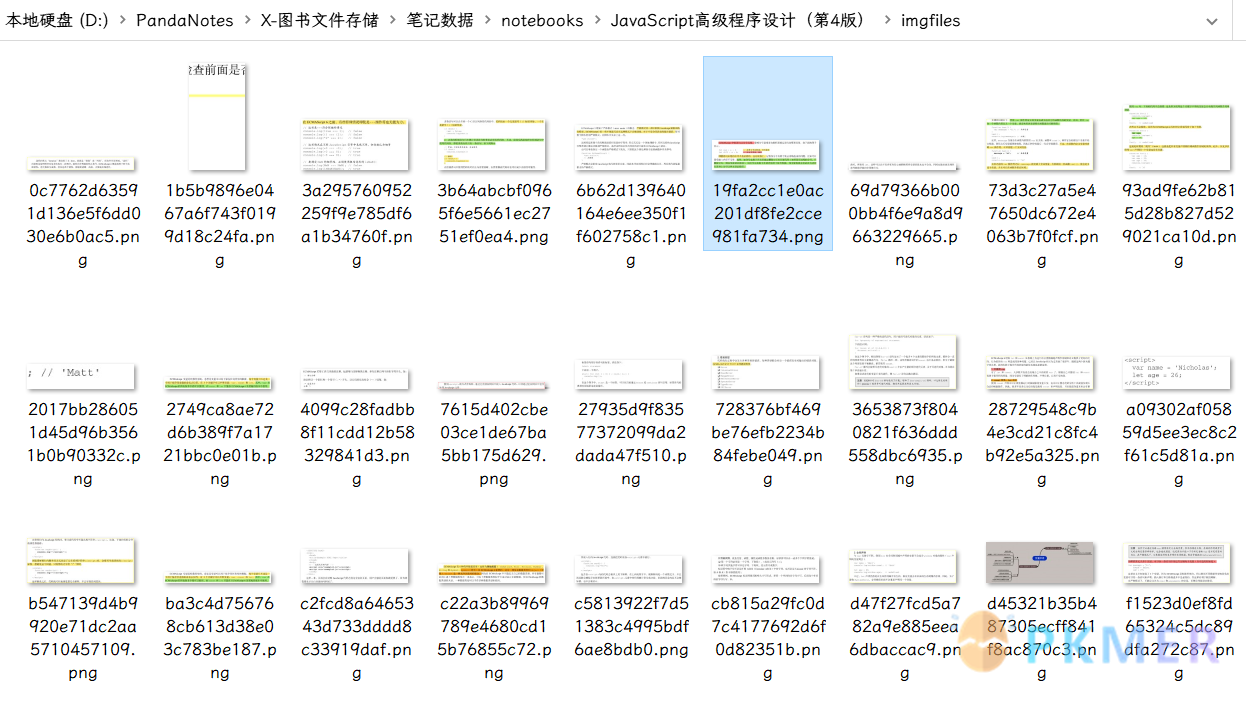
originaltext 则是标注的原文的文本信息,imgfile 对应的值就是图片信息,也就是在笔记数据文件夹下的 imgfiles文件夹里面存储的图片对应的图片名:
整理思路 + 代码实现
根据 BookxnotePro 的外部回链获取 nb, book, uuid 值,通过读取笔记数据目录的 notebooks 文件夹的 manifest.json 匹配 nb 的 id 值定位 PDF 的文件夹名,再读取 PDF 文件夹名的 markups.json 文件通过 uuid 定位获取标注信息。
通过正则正则匹配来匹配外部回链的 nb, book, uuid 值
function matchBookxnoteProRegex(backlink) {
const regex = /nb=({[0-9a-z\-]+})&book=([0-9a-z\-]+).*&uuid=([0-9a-z\-]+)/;
const matches = backlink.match(regex);
if (matches) {
const nb = matches[1];
const book = matches[2];
const uuid = matches[3];
return { nb, book, uuid };
} else {
return null;
}
}
通过 nb 查找对应的 book 信息
const fs = require('fs');
const path = require('path');
function findNotebooksById(obj, id) {
if (obj.notebooks && obj.notebooks.length > 0) {
for (let i = 0; i < obj.notebooks.length; i++) {
if (obj.notebooks[i].id === id) {
return obj.notebooks[i];
} else {
const result = findNotebooksById(obj.notebooks[i], id);
if (result) {
return result;
}
}
}
}
return null;
}
// 示例用法
const notebooksData = "D:/PandaNotes/X-图书文件存储/笔记数据/notebooks/manifest.json";
const notebooksJson = JSON.parse(fs.readFileSync(notebooksData, 'utf8'));
const targetId = "{ede53699-7b48-4be3-b42c-4aa08bd30ce1}";
const notebooks = findNotebooksById(notebooksJson, targetId);
console.log(notebooks);
通过 uuid 匹配到标注信息
const fs = require('fs');
const path = require('path');
function findMarkupsByUuid(obj, uuid) {
if (Array.isArray(obj.markups)) {
for (let i = 0; i < obj.markups.length; i++) {
if (obj.markups[i].uuid === uuid) {
return obj.markups[i];
}
const markupData = findMarkupsByUuid(obj.markups[i], uuid);
if (markupData) {
return markupData;
}
}
}
return null;
}
// 示例用法
const pdfBooknoteData = "D:/PandaNotes/X-图书文件存储/笔记数据/notebooks/JavaScript高级程序设计(第4版)/markups.json";
const markupJson = JSON.parse(fs.readFileSync(pdfBooknoteData, 'utf8'));
const targetUuid = "0b87d2be8c8b85663d2fd23264e4c866";
const markupData = findMarkupsByUuid(markupJson, targetUuid);
console.log(markupData);Excalidraw 脚本设置
实现由外部回链,通过 Ctrl + V 粘贴动作获取标注信息到 Excalidraw,附带返回的链接。
脚本安装
脚本安装可以根据源码来安装,也可以通过 Excalidraw 插件提供的脚本安装代码块来安装
- 代码块链接方法:
- 优点:一键安装脚本和图标,操作方便,后续脚本更新可以检测
- 缺点:国内需要可访问 GitHub 的网络
- 源码拷贝方式:
- 优点:不需要特殊网络
- 缺点:需要手动复制源码,这个过程很容易出问题,没有图标,脚本更新无法检测…
PS:之后我的脚本更新或者 BUG 修复,可能不会更新到网站,而是直接更新到 GitHub,因为这样对我来说比较方便点而且快速点。
代码块链接方法
```excalidraw-script-install
https://raw.githubusercontent.com/PandaNocturne/ExcalidrawScripts/master/PandaScripts/BookxnoteToExcalidraw.md
```将上述代码块放到一个 md 文件,阅读模式下该代码块会显示为 安装脚本的按钮,点击安装之后,更新为脚本已是最新 - 点击重新安装,即当前脚本已经安装,在 Excalidraw 画布界面的侧边Obsidian 工具面板中可以查看。
源码拷贝方式
/*
```javascript
*/
const eaApi = ExcalidrawAutomate;
let settings = ea.getScriptSettings();
if (!settings["notebooksPath"]) settings["notebooksPath"] = { value: false };
if (!settings["notebooksPath"].value) {
new Notice("🔴请配置相关设置!", 2000);
settings = {
"notebooksPath": {
value: "",
description: "BookxNotePro的笔记数据目录<br>🔴注意路径符号需要转义"
},
"copyBookxnoteImageToObsidian": {
value: true,
description: "是否复制Bookxnote的图片到Obsidian库内<br>🔴注意路径符号需要转义<br>🍀注:如果图片本身就存在于库内就可以关闭该选项"
},
"notebooksImagesPath": {
value: "BookxNotesImages",
description: "Obsidian文件夹,用于存放Bookxnote复制过来的标注图片,请用相对于库的路径"
},
};
ea.setScriptSettings(settings);
} else {
new Notice("✅BookxnoteproToExcalidraw脚本已启动!");
}
// let api = ea.getExcalidrawAPI();
const fs = require('fs');
// const path = require('path');
// 获取bookxnotePro的笔记数据文件夹
const notebookFolder = `${settings["notebooksPath"].value}/notebooks`;
// 获取notebooksImages的存储路径
const basePath = (app.vault.adapter).getBasePath();
const notebooksImagesPath = `${basePath}/${settings["notebooksImagesPath"].value}`;
// 读取manifest.json数据
const notebooksData = `${notebookFolder}/manifest.json`;
const notebooksJson = JSON.parse(fs.readFileSync(notebooksData, 'utf8'));
// console.log(notebooksJson)
// 添加选择是否匹配颜色
let InsertStyle;
const fillStyles = ["文字", "背景"];
InsertStyle = await utils.suggester(fillStyles, fillStyles, "选择插入卡片颜色的形式,ESC则为白底黑字)");
eaApi.onPasteHook = async function ({ ea,
payload,
event,
excalidrawFile,
view,
pointerPosition
}) {
console.log("onPaste");
event.preventDefault();
const backlink = payload.text;
console.log(payload.text);
if (payload?.text?.startsWith('bookxnotepro://opennote')) {
console.log("匹配成功");
// 清空原本投入的文本
event.stopPropagation();
payload.text = "";
ea.clear();
ea.style.fillStyle = 'solid';
ea.style.roughness = 0;
// ea.style.roundness = { type: 3 }; // 圆角
ea.style.strokeWidth = 2;
ea.style.fontFamily = 4;
ea.style.fontSize = 20;
// 匹配外部回链对应的信息
const { nb, book, page, uuid } = matchBookxnoteProRegex(backlink);
console.log({ nb, book, page, uuid });
// 通过nb找到对应的书本信息
const notebooks = findNotebooksById(notebooksJson, nb);
console.log(notebooks);
// 获取当前书籍的markups.json文件:
const booknoteMarkupsPath = `${notebookFolder}/${notebooks.entry}/markups.json`;
console.log(booknoteMarkupsPath);
const markupsJson = JSON.parse(fs.readFileSync(booknoteMarkupsPath, 'utf8'));
// console.log(markupsJson)
// 获取连接的标注信息
const markupData = findMarkupsByUuid(markupsJson, uuid);
// console.log(markupData?.originaltext);
if (markupData?.imgfile) {
console.log("图片标注");
const imgfilePath = `${notebookFolder}/${notebooks.entry}/imgfiles/${markupData.imgfile}`;
let imgName;
// 复制图片到Obsidian的笔记库
if (settings["copyBookxnoteImageToObsidian"].value) {
imgName = `bxn_${markupData.imgfile}`;
// 检查文件夹是否存在
if (!fs.existsSync(notebooksImagesPath)) {
// 创建文件夹
fs.mkdirSync(notebooksImagesPath);
new Notice(`图片文件不存在,已创建文件夹:<br>${notebooksImagesPath}`, 3000);
} else {
console.log('文件夹已存在');
}
fs.copyFileSync(imgfilePath, `${notebooksImagesPath}/${imgName}`);
await new Promise((resolve) => setTimeout(resolve, 200)); // 暂停0.2秒,等待复制文件的过程
} else {
imgName = `${markupData.imgfile}`;
}
let id = await ea.addImage(0, 0, imgName);
let el = ea.getElement(id);
el.link = `[${notebooks.entry}(P${page})](${backlink})`;
ea.setView("active");
await ea.addElementsToView(true, false, false);
} else if (markupData?.originaltext) {
console.log("文字标注");
const fillcolor = `#${markupData.fillcolor.slice(2)}`;
if (InsertStyle == "背景") {
ea.style.backgroundColor = fillcolor;
ea.style.strokeColor = "#1e1e1e";
} else if (InsertStyle == "文字") {
ea.style.backgroundColor = "#ffffff";
ea.style.strokeColor = fillcolor;
} else {
ea.style.backgroundColor = "transparent";
ea.style.strokeColor = "#1e1e1e";
}
const markupText = processText(markupData.originaltext);
const content = markupData.content ? `\n${markupData.content}`: "";
console.log(markupText);
const totalText = `${markupText}`;
let width = totalText.length > 30 ? 600 : totalText.length * 20;
let id = await ea.addText(0, 0, `${markupText} ([P${page}](${backlink}))${content}`, { width: width, box: true, wrapAt: 99, textAlign: "left", textVerticalAlign: "middle", box: "box" });
let el = ea.getElement(id);
// el.link = backlink;
ea.setView("active");
await ea.addElementsToView(true, false, false);
} else {
new Notice("未匹配到标注信息,请重新标注或者手动插入");
}
return false;
}
// return true;
};
function matchBookxnoteProRegex(backlink) {
const regex = /nb=({[0-9a-z\-]+})&book=([0-9a-z\-]+).*&page=([0-9]+).*&uuid=([0-9a-z\-]+)/;
const matches = backlink.match(regex);
if (matches) {
const nb = matches[1];
const book = matches[2];
const page = matches[3];
const uuid = matches[4];
return { nb, book, page, uuid };
} else {
return null;
}
}
function findNotebooksById(obj, id) {
if (obj.notebooks && obj.notebooks.length > 0) {
for (let i = 0; i < obj.notebooks.length; i++) {
if (obj.notebooks[i].id === id) {
return obj.notebooks[i];
} else {
const result = findNotebooksById(obj.notebooks[i], id);
if (result) {
return result;
}
}
}
}
return null;
}
function findMarkupsByUuid(obj, uuid) {
if (Array.isArray(obj.markups)) {
for (let i = 0; i < obj.markups.length; i++) {
if (obj.markups[i].uuid === uuid) {
return obj.markups[i];
}
const markupData = findMarkupsByUuid(obj.markups[i], uuid);
if (markupData) {
return markupData;
}
}
}
return null;
}
function processText(text) {
// 替换特殊空格为普通空格
text = text.replace(/[\ue5d2\u00a0\u2007\u202F\u3000\u314F\u316D\ue5cf]/g, ' ');
// 将全角字符转换为半角字符
text = text.replace(/[\uFF01-\uFF5E]/g, function (match) { return String.fromCharCode(match.charCodeAt(0) - 65248); });
// 替换英文之间的多个空格为一个空格
text = text.replace(/([a-zA-Z])([\u4e00-\u9fa5])/g, '$1 $2');
// 删除中文之间的空格
text = text.replace(/([0-9\.\u4e00-\u9fa5])\s+([0-9\.\u4e00-\u9fa5])/g, '$1$2');
text = text.replace(/([0-9\.\u4e00-\u9fa5])\s+([0-9\.\u4e00-\u9fa5])/g, '$1$2');
text = text.replace(/([\u4e00-\u9fa5])\s+/g, '$1');
text = text.replace(/\s+([\u4e00-\u9fa5])/g, '$1');
// // 在中英文之间添加空格
// text = text.replace(/([\u4e00-\u9fa5])([a-zA-Z])/g, '$1 $2');
// text = text.replace(/([a-zA-Z])([\u4e00-\u9fa5])/g, '$1 $2');
return text;
}讨论
若阁下有独到的见解或新颖的想法,诚邀您在文章下方留言,与大家共同探讨。

