
Obsidian 插件:Text Extractor
插件名片
概述
一个(伴侣)插件,用于帮助从图像(OCR)和 PDF 中提取文本。
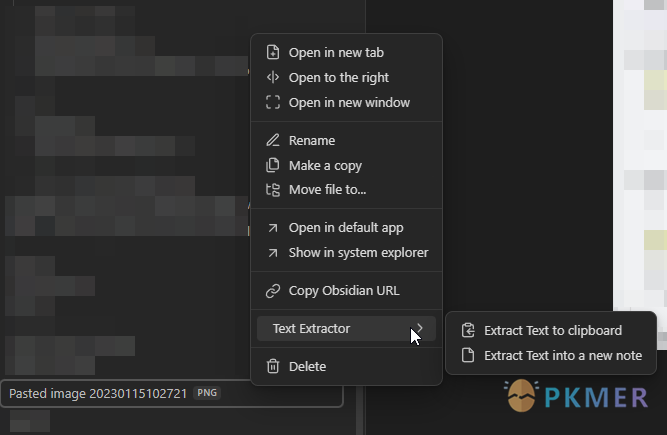
原文出处
下面自述文件的来源于 Readme
Readme(翻译)
下面是 text-extractor 插件的自述翻译
Obsidian 文本提取器




⭐ 寻找贡献者 ⭐
很不幸,我不能再为 Text Extractor 投入太多时间了,但仍有许多工作需要完成:提取 Excel 和 Word 文件、改进 PDF、提供更好的功能等等。
欢迎您提交 PR,我将乐意提供帮助和指导 :)
注意:**Text Extractor 并未被放弃!**该项目为 Omnisearch 提供了重要功能,我将继续通过修复错误、更新依赖项以及可能的快速小功能来支持它。
Text Extractor是一个“伴侣”插件。它主要在与其他插件(如 Omnisearch)一起使用时非常有用,但您也可以使用它快速从图像和 PDF中提取文本。
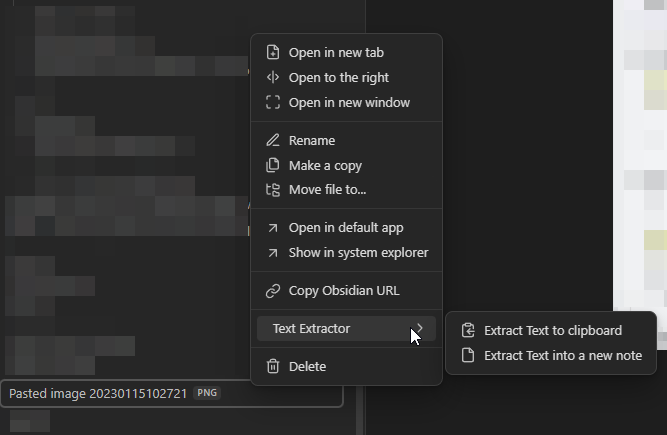
支持的文件类型:
- 图像(
.png,.jpg,.jpeg) - PDF(
.pdf)
限制
- 该插件目前使用 Tesseract.js 和 pdf-extract 来从图像和 PDF 中提取文本。这些库并不完美,可能无法在某些文件上工作。
- 🟥 PDF 文件通常无法提取其文本 🟥。请参阅 #7 和 #21
- 🟥 文本提取在移动设备上不起作用 🟥。请阅读下一节获取更多详细信息。
- 文本提取器需要互联网连接才能工作。所有处理都在本地完成,但底层 OCR 库(Tesseract)所需的语言文件是按需下载的。
缓存和同步
该插件将提取的文本缓存为本地的小型 .json 文件,存储在插件目录中。这些文件可以在您的设备之间进行同步。由于在移动设备上无法进行文本提取,如果可用,插件将使用同步的缓存文本。如果没有可用的缓存文本,将返回空字符串。
安装
Text Extractor 可在 Obsidian 社区插件仓库 上找到。您也可以通过从 发布页面 下载最新版本进行手动安装,或者使用 BRAT 插件管理器 进行安装。
为什么?
文本提取是一个有用的功能,但实现起来并不容易,并且消耗大量资源。
**通过这个插件,我希望提供一种统一的方式来从图像和 PDF 中提取文本,并使其可用于其他插件。**这样,其他插件可以在不必担心实现细节的情况下使用它,并且不必不必要地消耗资源。
⚠️ 正在进行中
我正在使用 Omnisearch 来测试这个插件。API 函数可能不会改变,但这仍然是一个测试版。
将 Text Extractor 作为插件的依赖项使用
暴露的 API:
// 在你的代码中添加这个类型
export type TextExtractorApi = {
extractText: (file: TFile) => Promise<string>
canFileBeExtracted: (filePath: string) => boolean
isInCache: (file: TFile) => Promise<boolean>
}
// 然后,你可以使用这个函数来获取API
export function getTextExtractor(): TextExtractorApi | undefined {
return (app as any).plugins?.plugins?.['text-extractor']?.api
}
// 使用方法如下
const text = await getTextExtractor()?.extractText(file)请注意,Text Extractor 仅在需要时提取文本,当你在文件上调用 extractText() 时,以避免不必要的资源消耗。后续对 extractText() 的调用将返回缓存的文本。
开发
虽然这个插件最初是为 Omnisearch 开发的,但它是完全不可知的,我希望它能成为一个社区的努力。如果您希望提交 PR,请先打开一个问题,以便我们讨论该功能。
该插件分为两个部分:
- 文本提取库,负责实际工作
- 插件本身,它是库的包装器,并向用户公开一些有用的选项
每个项目都有自己的文件夹,并且有自己的 package.json 和 node_modules。该库使用 Rollup(更容易与 Wasm 和 Web Workers 一起设置),而插件使用 esbuild。

