
Obsidian 插件:【Readme】Quadro
插件名片
概述
定性数据分析(QDA)适用于社会科学家。这是 MAXQDA 和 atlas.ti 的开放替代方案,使用 Markdown 来存储数据和研究代码。
原文出处
下面自述文件的来源于 Readme
Readme(翻译)
下面是 quadro 插件的自述翻译
【机翻】
Quadro- 在 Obsidian 中实现的定性数据分析


Obsidian 插件,用于社会科学定性数据分析(QDA)。是 MAXQDA 和 atlas.ti 的开放替代方案,使用 Markdown 来存储数据和研究代码。
Quadro支持Grounded Theory风格的编码和Qualitative Content Analysis风格的提取。
目录
介绍
对于不熟悉 Obsidian 的学者
这个插件利用了 Obsidian 的丰富文本处理功能,为定性数据分析提供了一个轻量级的应用程序。
所有数据都存储为 Markdown 文件。
Markdown 是一种人类可读、非专有且常用的开放标准,用于纯文本文件。这意味着:
- 没有锁定/依赖于特定软件,数据可以在支持 Markdown 的任何应用程序中进行分析。(实际上,数据存储在纯文本中,因此甚至可以使用
Notepad.exe或TextEdit.app打开和阅读) - 研究数据因此具有未来性,满足了定性数据的长期存档要求。可以保证数据即使在 50 年后仍然可以阅读,这是专有研究软件(如
MAXQDA或atlas.ti)所不具备的保证。 - 数据与其他应用程序具有互操作性,这意味着它可以轻松地与其他文本分析工具(如 AntConc)或浏览器扩展(如 MarkDownload)结合使用,以获取网站内容。
- Markdown 文件默认存储在离线状态,满足了研究伦理和研究数据保护的关键要求。
作为 Obsidian 插件,定性数据分析嵌入在 Obsidian 的广泛功能和插件生态系统中:
- 数据分析可以利用 Obsidian 的功能集,该功能集已经专注于链接文件。例如,图形视图 可用于创建代码的可视化网络,而 Outgoing Links 提供了代码分配给的所有数据文件的概述。
- 定性分析可以轻松扩展到一个 超过1000个插件的全面生态系统,例如用于高级数据聚合的 DataLoom 或用于自动获取 YouTube 视频转录的 YTranscript。
- 所有这些都允许研究人员根据其研究的特定需求定制分析。研究方法的案例特定调整是定性研究的一个关键需求(在使用标准化的专有研究软件时,这个需求严格来说并没有真正得到满足)。
- Obsidian 和 Quadro 都 支持移动设备(Android 和 iOS)。
- 使用 Obsidian 可以采用以键盘为驱动的工作流程,最小化鼠标的使用。
如果研究团队中有更懂技术的研究人员,Quadro 的优势甚至更大:
- 作为开源软件,这个插件可以被修改和定制以满足他们的需求。(它是用 TypeScript / JavaScript 编写的,这是一种特别易于访问和常用的编程语言。)
- 通过将数据存储在 markdown 文件中,所有研究数据都可以通过
git进行完全版本控制。
Obsidian 是 免费供学术用途使用的,Quadro 也是免费使用的。特别是对于撰写论文的学生,这可以节省许多不必要的许可证麻烦。
对于不熟悉 QDA 的 Obsidian 用户
在定性数据分析中,“编码”是对文本段进行细粒度标记的一种形式,“提取”是将散文文本转化为结构化数据。
编码是通过在数据文件和代码文件之间插入 wikilinks 来实现的,这种“双向”链接。 (Obsidian 本身确实有反向链接,但这些是单向链接,因为隐式的反向链接仅被推断而不存储在任何地方的 markdown 文件中。)。
它利用 Obsidian 的 note-embedding 功能来跟踪编码的文本段。
- 代码是以
[[wikilinks]]的形式实现的,而不是#tags,因为前者允许更灵活,比如每个代码一个单独的文件。 - 这个插件的独特特点是,它的命令总是同时编辑两个文件(数据文件和代码文件),这对于充分处理 QDA 中常见的编码工作流程是必要的。
提取是通过为每个提取创建单独的提取文件来实现的,使用 YAML frontmatter 来以结构化形式存储数据。 Quadro 使用简单的模板机制来支持这些提取文件的创建。
与其他 QDA 软件的简要方法论比较
优势
- 互操作性:可以自由与其他 QDA 软件结合使用。
- 灵活性:您可以使用代码、提取或自由组合两者。
- 可定制性:QDA 软件的隐含假设,比如代码选择模态中代码呈现的初始顺序,可以定制以处理不同类型的编码者偏见。
- 可扩展性:Quadro可以通过 Obsidian 插件生态系统轻松扩展。与其他研究软件不同,在大多数情况下扩展功能不需要技术专业知识编码经验。
劣势
- 编码单位仅限于段落,到一定程度上也包括段落的片段。不支持对单个单词进行编码。
- 由于 Markdown 标记的特性,无法将多个代码分配给部分重叠的段落片段。这个限制仅适用于部分重叠,当然可以将多个代码分配给同一段落或段落片段。
用法
开始使用
示例保险库
有一个 预先配置的示例保险库 可用于Quadro。除了一些预安装的 QDA 插件外,它还包括一些带有示例代码和提取的模拟数据,并展示了提取功能,以展示Quadro的功能。
- 下载保险库。
- 将目录
quadro-example-vault作为 Obsidian 保险库打开。(如果您是Obsidian的新手,请参阅Obsidian文档以了解如何进行操作。)
有经验的黑曜石用户
如果您对黑曜石很有经验,您也可以 直接安装插件,不过查看示例保险库仍然是有帮助的,以便更好地了解Quadro的功能。
使用单独的保险库
建议为数据分析创建一个单独的保险库,并在那里安装插件,原因如下:
- QDA 不遵循“笔记常规逻辑”,因此通常需要与常规保险库不同的插件和设置。
- 单独的保险库意味着建议(例如属性)也是分开的。
- 为了使 Obsidian 更易于用于定性研究,Quadro还对 Obsidian 的核心布局进行了一些(轻微的)修改,例如更宽的属性键。
- 出于档案目的,研究数据已经分开。
- 对于研究团队中的协作工作,数据与个人笔记分开存储。 很遗憾,这是不支持的。主要原因是商业 QDA 软件使用专有格式,这也是研究人员应该一开始就使用开放格式的研究软件的确切原因。
如果您的研究数据保存在 Markdown中,Obsidian可以导入它们。同时,也支持从 各种其他笔记应用程序,如Notion、Evernote、OneNote、Google Keep、Apple Notes、Bear或Roam 导入。
然而,可以将使用Quadro完成的结果导出,以便与其他研究人员合作。您可以将单个文件导出为 PDF,或者 将聚合结果导出为CSV。
编码
在 Quadro 中编码的工作原理
分析中有两种基本类型的文件,数据文件和代码文件,它们都以 Markdown文件 的形式存储。
数据文件
作为文本文件的经验材料。它们可以存储在保险库中的任何位置,以 .md 文件的形式存储。(建议单独创建一个名为 Data 的子文件夹。)由于Quadro将代码分配给整个段落,因此这些数据文件应该被分割成更小的段落。
当分配代码时,会在段落末尾附加指向相应代码文件和唯一 ID 的链接:
文件名: ./Data/Interview 1.md
Lorem ipsum dolor sit amet, qui minim labore adipisicing minim sint cillum sint
consectetur cupidatat. [[MyCode]] ^id42代码文件
文件夹 {vault-root}/Codes 中的所有 Markdown 文件都被视为代码文件。
当分配代码时,会在代码文件中附加指向数据文件中原始位置的链接。
文件路径: ./Codes/MyCode.md
![[Interview 1#^id42]]由于该链接是所谓的 嵌入链接,Obsidian 会在代码文件中呈现数据文件的相应段落:

用于编码的基础文件夹结构如下(颜色代表代码):
.
├── 📂 Data
│ ├── 📄 Interview 1.md
│ ├── 📄 Field Notes 1.md
│ └── …
└── 📂 Coding
├── 📄 blue.md
├── 📄 red.md
└── 📂 Group 1
├── 📄 white.md
├── 📄 black.md
└── …Note这种方法的主要缺点是代码的分配主要限制在段落级别。仅将代码分配给段落的部分限于向相应部分添加高亮显示。不支持将代码分配给单个单词和具有重叠的编码段。
编码能力
| 操作 | 描述 | 侧边栏按钮 | 默认快捷键 | 能力提供者 |
|---|---|---|---|---|
| 分配代码 | 为当前段落分配一个代码,任何选定的文本都会被突出显示。(不支持重叠的突出显示)。 选择 创建新代码 或按 shift ⏎ 创建一个新的代码文件并将其分配给段落。 |  | mod+shift+a | Quadro |
| 重命名代码 | 所有对代码文件的引用都会自动更新。(您也可以右键单击文件或链接并选择“重命名”来重命名。) |  | mod+shift+r | Obsidian 内置 |
| 从段落中删除代码 | 从数据文件或代码文件的当前段落中删除代码。相应的其他文件中的引用也会被删除。 |  | mod+shift+d | Quadro |
| 删除代码文件及其所有引用 | 将代码文件移动到垃圾箱,并删除所有对它的引用。 |  | — | Quadro |
| 批量创建新代码 | 一次创建多个新代码(而不将它们分配给段落)。 |  | — | Quadro |
| 代码分组 | 可以通过文件资源管理器中的拖放来将代码排列在子文件夹中。 | — | — | Obsidian 内置 |
| 代码关系可视化 | 在图形视图中,使用类似 path:Codes OR path:Data 的查询,并将数据和代码分配给不同的组。更多文档 |  | mod+g | Obsidian 核心插件: 图形视图 |
| 轴向编码 | 使用 Canvas 插件,您可以在面板上自由排列实体,并通过线条和箭头连接它们,适用于轴向编码。 更多文档 |  | — | Obsidian 核心插件: Canvas |
| 代码共现的调查 | 在 Obsidian 搜索中,使用查询如 line:([[MyCodeOne]] [[MyCodeTwo]])。更多文档 | — | mod+shift+f | Obsidian 核心插件: 搜索 |
mod在 Windows 上指ctrl,在 macOS 上指cmd。每个快捷键都可以通过在 Obsidian 快捷键设置中搜索相应操作的名称来自定义。- 尚不支持拆分和合并代码文件。使用任何其他方法(如插件)进行此操作可能会导致引用损坏。
- ⚠️ 重命名或移动代码/数据文件应该在 Obsidian 内部完成。使用 Windows 资源管理器或 macOS 的 Finder 不会触发引用的自动更新,意味着信息丢失。
提取
Quadro 中的提取工作原理
提取的实现方式与编码类似,使用两种基本文件类型,数据文件和提取文件。
数据文件
实证材料以文本文件形式存在。它们可以存储在保险库中的任何位置,以 .md 文件的形式。
在进行提取时,会像编码一样,在段落末尾附加指向相应提取文件和唯一 ID 的链接:
文件名: ./Data/Interview 2.md
Lorem ipsum dolor sit amet, qui minim labore adipisicing minim sint cillum sint
consectetur cupidatat. [[Career Visions/1]] ^id-481516提取文件
提取是通过 Markdown 元数据(YAML frontmatter)实现的,
通过 Obsidian Properties 支持。
在进行提取时,您可以选择提取类型。选择后,将在分组提取的文件夹中创建一个新文件,即 {vault-root}/Extractions/{Extraction Group}/。
因此,每个文件对应一个单独的提取,其父文件夹指示其是何种类型的提取。
然后,您可以填写新创建文件的字段。
extraction source 键包含一个链接,返回到您发起提取的数据文件中的位置。
在渲染视图中,文件包含一个方便填写的 Properties 头部:
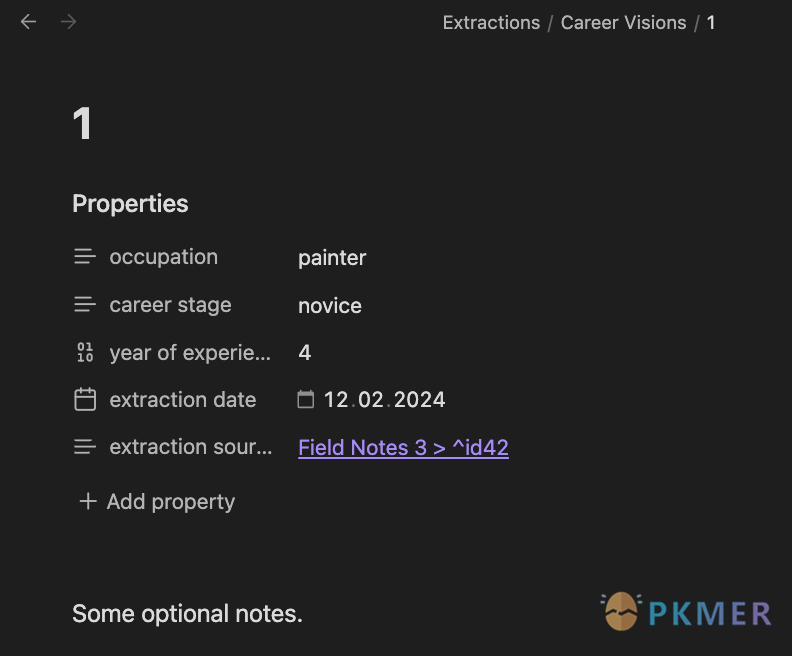
文件的底层纯文本视图如下所示:
文件路径: ./Extractions/Career Visions/Career Visions 1.md
---
occupation: "painter"
career stage: "novice"
year of experience: 4
extraction date: 2024-02-12
extraction source: "[[Field Notes 3]]"
---
**提取自段落:** ![[Field Notes 3#^id-42]]提取模板(提取类型)
可用的提取类型由 {vault-root}/Extractions/ 的子文件夹确定。
用于填写信息的字段由该子文件夹中的 Template.md 文件确定。
对于上述示例,提取模板如下所示:
相应提取类型的模板位于同一文件夹中,但文件名为 Template.md。
文件路径: ./Extractions/Career Visions/Template.md
---
occupation:
career stage:
year of experience:
---总的来说,提取的底层文件夹结构如下所示:
.
├── 📂 Data
│ ├── 📄 Interview 1.md
│ ├── 📄 Field Notes 1.md
│ └── …
└── 📂 Extractions
├── 📂 Career Obstacles
│ ├── 📄 Template.md
│ ├── 📄 Career Obstacles 1.md
│ ├── 📄 Career Obstacles 2.md
│ └── …
└── 📂 Career Visions
├── 📄 Template.md
├── 📄 Career Visions 1.md
└── …聚合提取
使用 Aggregate extractions 命令创建一个可以排序、过滤、搜索和修改的表格:
https://github.com/chrisgrieser/obsidian-quadro/assets/73286100/6242a113-b17e-42e3-9398-806cdbec3b2d
提取功能
| 操作 | 描述 | 侧边栏按钮 | 默认快捷键 | 提供功能的插件 |
|---|---|---|---|---|
| 从段落中提取 | 从提取模板创建一个提取文件。 |  | mod+shift+e | Quadro |
| 创建新的提取类型 | 创建一个新的提取类型(在“提取”中创建一个新的子文件夹,以及一个新的提取模板)。 |  | — | Quadro |
| 聚合提取 | 创建一个汇总提取文件的表格。该表格可以进行排序、筛选、搜索和修改。 更多文档 |  | — | 社区插件: Data Loom |
| 共同提取维度 | 通过在 Obsidian 搜索中使用类似 ["问题原因": 碎片化] ["兼容性类型": 向后] 的查询,找到两个维度具有特定值的提取。更多文档 | — | mod+shift+f | Obsidian 核心插件: 搜索 |
| 全局重命名维度 | 在文件中重命名属性字段仅影响该文件的属性。要全局重命名属性,请使用命令面板(mod+p),并搜索 Properties View: Show all Properties。侧边栏中会弹出一个属性列表,您可以通过右键单击重命名属性。 | — | — | Obsidian 核心插件: 属性视图 |
将所有提取导出为 .csv | 将所有提取类型的所有提取导出为以 , 分隔的 .csv 文件。 | — | Quadro |
mod在 Windows 上指ctrl,在 macOS 上指cmd。每个快捷键都可以通过在 Obsidian 快捷键设置中搜索相应操作的名称来自定义。- 对于聚合和
.csv导出,包含的属性由模板文件(Template.md)的属性决定。 - ⚠️ 重命名或移动提取/数据文件应该在 Obsidian 内部完成。使用 Windows 资源管理器或 macOS 的 Finder 不会触发自动更新引用,意味着信息丢失。
技术
要求
Quadro 需要至少 Obsidian 版本 1.5.8。
Aggregate Extractions 命令需要 DataLoom 插件。
安装
手动安装
- 下载最新版本。
- 将
.zip文件解压到文件夹{your-vault-path}/.obsidian/plugins/quadro中。(请注意,在 macOS 上,.obsidian是一个隐藏文件夹。您可以通过在 Finder 中按下cmd+shift+.来使隐藏文件夹可见。) - 在 Obsidian 中,转到
设置→社区插件。点击刷新按钮。 - 在插件列表中查找新条目
Quadro。通过勾选框启用插件。
BRAT(Beta Reviewers Auto-update Tester)
或者,如果您已经熟悉 Obsidian 生态系统,您也可以通过 BRAT 安装插件。
Obsidian 社区插件商店
一旦在 Obsidian 社区插件商店中发布,Quadro 将可以通过 Obsidian 的插件浏览器访问:设置→社区插件→浏览→搜索 “Quadro”
更新
手动
- 关闭 Obsidian。
- 从 最新版本 下载
.zip文件。 - 将
.zip文件解压到{your-vault-path}/.obsidian/plugins/quadro,替换该文件夹中的现有文件。 - 再次启动 Obsidian。
BRAT
如果您通过BRAT添加了插件,它会在每次启动 Obsidian 时自动检查新的更新,并在有新版本可用时自动更新Quadro。
Obsidian 社区插件商店
一旦在 Obsidian 社区插件商店中发布,您可以通过以下方式更新Quadro(以及您安装的所有其他插件):设置 → 社区插件 → 检查更新 → 全部更新。
Bug Reports & Feature Requests
- 对于 bug 报告或功能请求,请使用 GitHub问题跟踪器。
- 对于关于Quadro的问题和一般讨论,请使用 GitHub讨论论坛。
开发
git clone "git@github.com:chrisgrieser/obsidian-quadro.git"
make initmake format # 运行所有格式化程序
make build # 构建插件
make check-all # 运行预提交钩子(不提交)Note该存储库使用预提交钩子,防止未通过所有检查的提交。
鸣谢
致谢
- Ryan Murphy 给了我这个项目的创意,他在他的 博客文章 中提到了这个想法。
- Grit Laudel 提供了样本访谈数据。
该项目的推荐引用
请按照以下 APA 格式引用此软件项目:
Grieser, C. (2024). Quadro – Qualitative Data Analysis Realized in Obsidian [Computer software].
https://github.com/chrisgrieser/obsidian-qualitative-data-analysis对于其他引用样式,请使用以下元数据:
关于开发者
我是一名社会学家,研究数字经济背后的社会机制。在我的博士项目中,我调查了应用经济的治理以及软件生态系统如何管理创新和兼容性之间的紧张关系。如果您对这个主题感兴趣,请随时与我联系。
如有错误报告和功能请求,请使用 GitHub问题跟踪器。

