
Obsidian 插件:Extract PDF Annotations
插件名片
概述
提取 PDF 注释(笔记和高亮)并按主题分类
原文出处
下面自述文件的来源于 Readme
Readme(翻译)
下面是 obsidian-extract-pdf-annotations 插件的自述翻译
Obsidian 提取 PDF 批注插件
这是一个为 Obsidian 设计的插件。它可以从 PDF 文件中提取批注。
用法
该插件访问给定目录中的所有 PDF 文件,并从 PDF 文件中提取注释和高亮显示。它将每个注释的第一行视为主题,以便对注释进行分组。
假设我们在我们的 Vault 中有一个包含 PDF 文件的文件夹,例如:
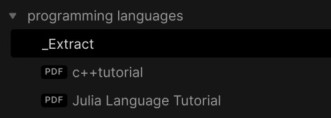
并且我们用一个名为 ‘Hello World’ 的注释突出显示了 Julia Hello World 程序:
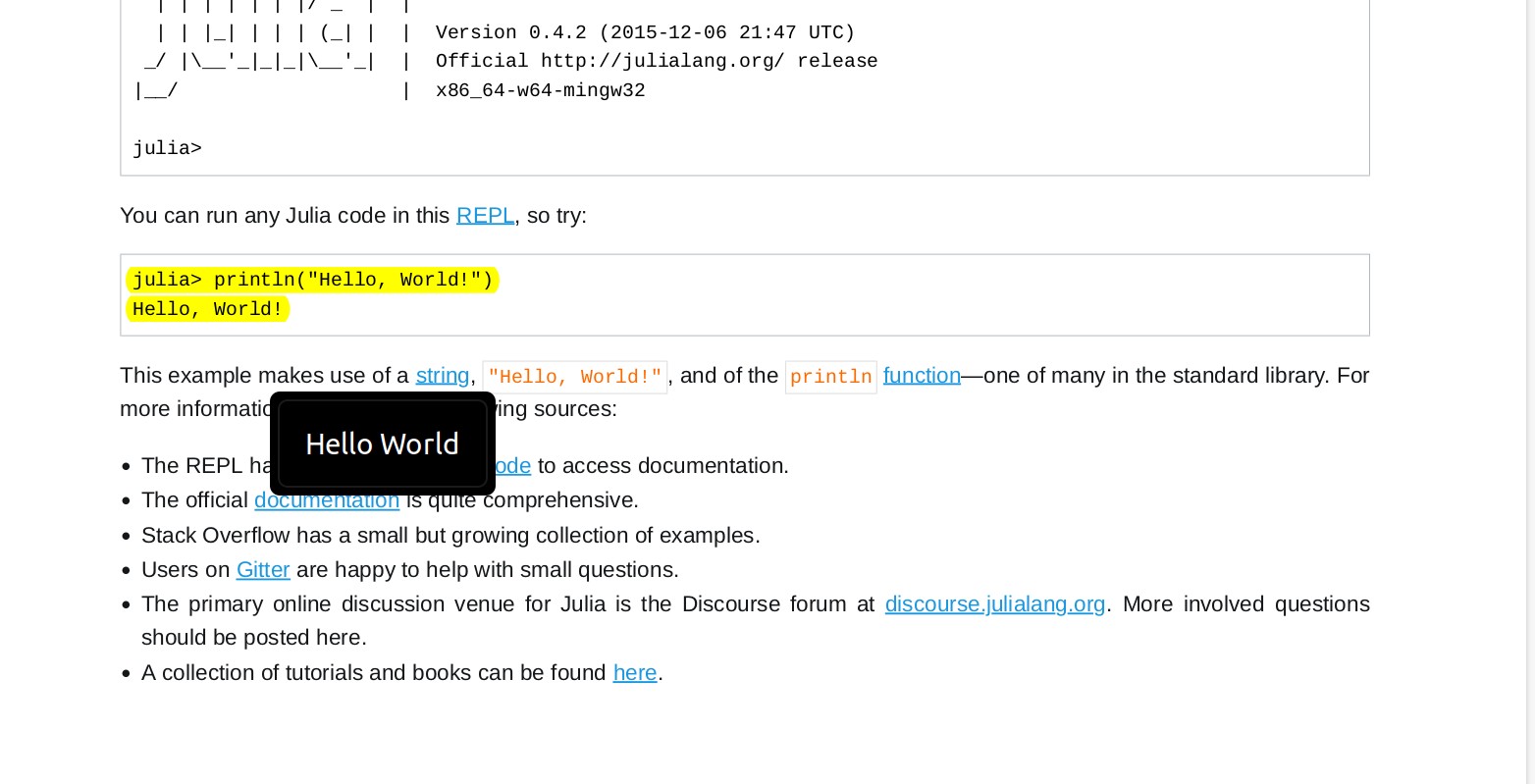
在编辑器中(例如_Extract),我们运行插件的命令 Extract PDF Annotations(所有命令的热键为 Ctrl-P)。这将获取当前文件夹中 PDF 文件中的所有注释,并按主题进行排序:
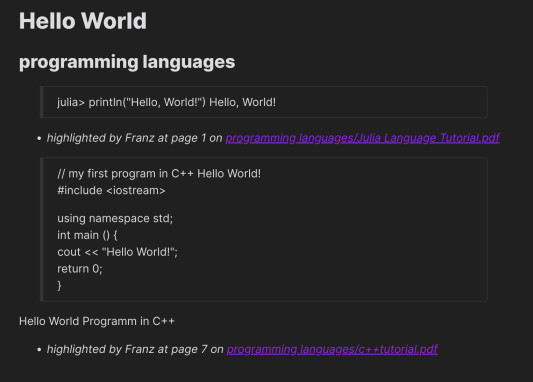
因此,您可以将来自多个 PDF 文件的注释与您的主题(这里是 ‘Hello World’)相关联。
命令
提取PDF批注在编辑 markdown 笔记时有效。搜索当前文件夹中的所有 PDF 文件的批注,并将它们插入到打开笔记的当前位置。提取单个文件的PDF批注在显示 PDF 文件时有效。从该文件中提取批注,并将它们写入到笔记Annotations for <文件名>中。
插件设置
- 是否使用评论的第一行作为“主题”(并相应地进行排序)
- 是否使用文件夹名称或 PDF 文件名进行排序
版本
1.0.4 清理连字符 https://github.com/munach/obsidian-extract-pdf-annotations/issues/5
1.0.3 更新了高亮提取,使用 QuadPoints 而不是矩形。
安装/构建
获取仓库:
$ git clone https://github.com/munach/obsidian-extract-pdf-annotations.git
$ cd obsidian-extract-pdf-annotations安装依赖:
$ npm i转译 main.ts:
$ npm run build然后创建插件目录并复制文件 main.js 和 manifest.json,例如:
$ mkdir ~/MyVault/.obsidian/plugins/obsidian-extract-pdf-annotations
$ cp main.js manifest.json ~/MyVault/.obsidian/plugins/obsidian-extract-pdf-annotations/在 Obsidian 的设置中启用插件。
问题 / 错误
[] 仅适用于从左到右的高亮。
鸣谢
该插件借鉴了 Alexis Rondeaus 的插件https://github.com/akaalias/obsidian-extract-pdf-highlights的思路,但使用了 Obsidian 内置的 pdf.js 库。
作者
Franz Achermann

