obsidian社区插件
自定义 Excalidraw 脚本 -OCR 自动提取图片文字 (可批量可修改)

自定义 Excalidraw 脚本 -OCR 自动提取图片文字 (可批量可修改)
Note
对 Excalidraw 的图片进行 OCR,并保留文本信息在图片中,可以编辑修改、重新 OCR 和进行批量识别。
脚本思路
- 对图片添加弹窗,如果不存在 OCR 文本则进行 OCR,然后保留数据文本在 Yaml 中 (参考 Excalidraw 自带的识别保留识别数据结构),弹窗可以添加。
- 对图片进行 OCR,可以保存数据为到指定 Cache 文件夹为 Json 数据 (参考 Text Extractor 的数据存储结构)
- OCR 借助的 Text Extractor插件的API
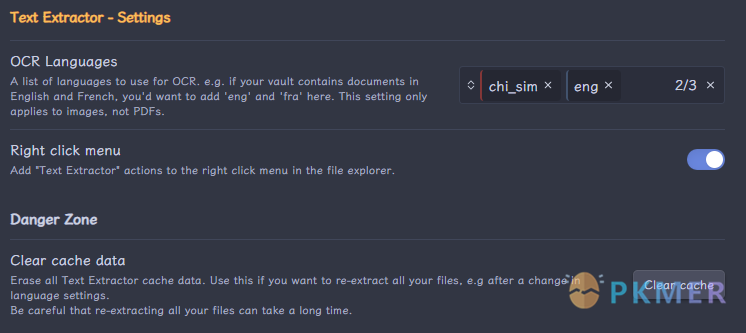
在控制台的使用 Text Extractor 的 API 案例:
function getTextExtractor() {
return app.plugins.plugins['text-extractor'].api;
}
// Example usage
let file={
path:'Y-图形文件存储/ZoteroImages/JPQENLZK.png',
};
const text = await getTextExtractor().extractText(file)
console.log(text)自动识别设置
首先默认自动识别是关闭的,在装了 Text Extractor 后你可以开启,可以在脚本设置里面管理
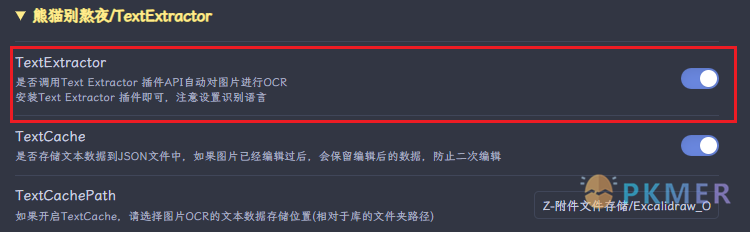
OcrText 保存方式
默认只会保留图片编辑后的数据文件到画板的 Yaml 区域:

如果图片不存在,该 Yaml 对应的值会在下一次运行脚本的时候删除,减少冗余数据
TextCache 本地数据缓存
对同一个图片的编辑结果在其他画板中不会保留,因此在设置选项中有 TextCache 选项可以保存同一张图片的编辑结果,使你在不同画板中对同一个图片的编辑数据保留,如果更改,存储数据也会更改,数据保存格式为 Json 文件。
📌注意:开启后,需要配置数据保存的文件夹,相对库的相对路径
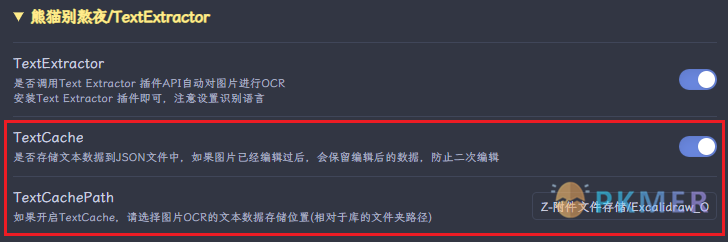
脚本代码:Text Extractor
- 选中多个图片可以进行批量识别但不会弹窗
await ea.addElementsToView();
const api = ea.getExcalidrawAPI();
const fs = require('fs');
const path = require('path');
const Activefile = app.workspace.getActiveFile();
let settings = ea.getScriptSettings();
//set default values on first run
if (!settings["TextCache"]) {
settings = {
"TextExtractor": {
value: false,
description: "是否调用Text Extractor 插件API自动对图片进行OCR<br>安装Text Extractor 插件即可,注意设置识别语言"
},
"TextCache": {
value: false,
description: "是否存储文本数据到JSON文件中,如果图片已经编辑过后,会保留编辑后的数据,防止二次编辑"
},
"TextCachePath": {
value: "",
description: "如果开启TextCache,请选择图片OCR的文本数据存储位置(相对于库的文件夹路径)"
}
};
ea.setScriptSettings(settings);
}
// 获取库的基本路径
const basePath = (app.vault.adapter).getBasePath();
const textCachePath = `${basePath}/${settings["TextCachePath"].value}`;
if (!fs.existsSync(textCachePath)) {
fs.mkdirSync(textCachePath, { recursive: true });
console.log('配置路径已创建');
} else {
console.log('配置路径已存在');
}
const els = ea.getViewSelectedElements().filter(el => el.type === "text" || el.type === "image" || el.type === "embeddable");
// 是否为批处理
const nums = els.filter(el => el.type == "image" || el.type === "text").length;
let batchRecognition = false;
// 多文本则进行批处理
if (nums > 1) {
new Notice(`检测到${nums}张图片\n进行批量识别`, 500);
batchRecognition = true;
}
// 图片计数
let n = 0;
// 汇集所有文本集合
let allText = [];
// 获取库所有文件列表
const files = app.vault.getFiles();
for (let el of els) {
if (el.type == "image") {
let data = {
filePath: "",
fileId: "",
ocrText: "",
};
const currentPath = ea.plugin.filesMaster.get(el.fileId).path;
const file = app.vault.getAbstractFileByPath(currentPath);
const jsonPath = path.join(textCachePath, `${el.fileId}.json`);
// 判断是否进行存储Json数据
let jsonData = {};
if (settings["TextCache"].value) {
jsonData = readJsonData(jsonPath, data);
console.log(jsonData.valueOf());
} else {
jsonData = {};
}
// 初始化ocr文本
let ocrText = "";
let ocrText_yaml = "";
n++;
await app.fileManager.processFrontMatter(Activefile, fm => {
ocrText_yaml = fm[`ocrText_${el.fileId}`];
});
if (ocrText_yaml) {
ocrText = JSON.parse(ocrText_yaml);
} else if (jsonData.ocrText) {
new Notice(`图片已存在OCR文本`, 500);
ocrText = jsonData.ocrText;
} else if (settings["TextExtractor"].value) {
new Notice(`图片OCR中......`);
const text = await getTextExtractor().extractText(file);
new Notice(`第${n}张片已完成OCR`, 500);
ocrText = processText(text);
}
if (!batchRecognition) {
const { insertType, ocrTextEdit } = await openEditPrompt(ocrText);
// 不管复制还是修改,都会保存
ocrText = ocrTextEdit;
if (insertType == "copyText") {
copyToClipboard(ocrTextEdit);
new Notice(`已复制:图片文本`, 1000);
} else if (insertType) {
new Notice(`完成修改`, 500);
}
}
// 更新数据源
data.filePath = file.path;
data.fileId = el.fileId;
data.ocrText = ocrText;
// 保存信息到Yaml区(方便GPT识别)
await app.fileManager.processFrontMatter(Activefile, fm => {
fm[`ocrText_${el.fileId}`] = JSON.stringify(ocrText);
});
console.log("写入Yaml");
if (settings["TextCache"].value) {
// 保存数据到Json文件中
fs.writeFileSync(jsonPath, JSON.stringify(data));
}
// 收集提取的信息
allText.push(ocrText);
} else if (el.type == "text") {
let exText = el.rawText;
if (!batchRecognition) {
const { insertType, ocrTextEdit } = await openEditPrompt(exText);
// 不管复制还是修改,都会保存
exText = ocrTextEdit;
if (insertType == "copyText") {
copyToClipboard(exText);
new Notice(`已复制:图片文本`, 1000);
} else if (insertType) {
new Notice(`完成修改`, 500);
}
el.originalText = el.rawText = el.text = exText;
}
console.log(exText);
allText.push(exText);
} else if (el.type == "embeddable" && el.link.endsWith("]]")) {
let filePaths = getFilePath(files, el);
// 读取文件内容
let markdownText = getMarkdownText(filePaths);
console.log(markdownText);
allText.push(markdownText);
copyToClipboard(markdownText);
new Notice(`复制文本`, 3000);
}
await ea.addElementsToView(false, true);
}
await ea.addElementsToView(false, true);
if (batchRecognition) {
// 如果批量识别则直接进行复制文本
const output = allText.join("\n");
console.log(output);
new Notice(`✅已完成批量OCR`, 3000);
copyToClipboard(output);
new Notice(`📋复制所有文本到剪切板`, 3000);
}
// 如果图片不存在则清楚yaml对应的id
await app.fileManager.processFrontMatter(Activefile, fm => {
allels = ea.getViewElements();
Object.keys(fm).forEach(key => {
if (key.startsWith("ocrText_") && !allels.some(el => `ocrText_${el.fileId}` === key)) {
delete fm[key];
}
});
});
// 调用Text Extractor的API
function getTextExtractor() {
return app.plugins.plugins['text-extractor'].api;
}
// 格式化文本
function processText(text) {
// 替换特殊空格为普通空格
text = text.replace(/[\ue5d2\u00a0\u2007\u202F\u3000\u314F\u316D\ue5cf]/g, ' ');
// 将全角字符转换为半角字符
text = text.replace(/[\uFF01-\uFF5E]/g, function (match) { return String.fromCharCode(match.charCodeAt(0) - 65248); });
// 替换英文之间的多个空格为一个空格
text = text.replace(/([a-zA-Z])([\u4e00-\u9fa5])/g, '$1 $2');
// 删除中文之间的空格
text = text.replace(/([0-9\.\u4e00-\u9fa5])\s+([0-9\.\u4e00-\u9fa5])/g, '$1$2');
text = text.replace(/([0-9\.\u4e00-\u9fa5])\s+([0-9\.\u4e00-\u9fa5])/g, '$1$2');
text = text.replace(/([\u4e00-\u9fa5])\s+/g, '$1');
text = text.replace(/\s+([\u4e00-\u9fa5])/g, '$1');
// 在中英文之间添加空格
text = text.replace(/([\u4e00-\u9fa5])([a-zA-Z])/g, '$1 $2');
text = text.replace(/([a-zA-Z])([\u4e00-\u9fa5])/g, '$1 $2');
return text;
}
// 打开文本编辑器
async function openEditPrompt(ocrText) {
// 打开编辑窗口
let insertType = "";
let ocrTextEdit = await utils.inputPrompt(
"OCR文本",
"可以自行修改文字保存在图片的属性中,输入一个空格会重新识别,注意清空并不会清除数据",
ocrText,
[
{
caption: "复制文本",
action: () => {
insertType = "copyText";
return;
}
},
{
caption: "修改文本",
action: () => {
insertType = "insertImage";
return;
}
}
],
10,
true
);
if (!ocrTextEdit) {
ocrTextEdit = ocrText;
} else if (ocrTextEdit == " ") {
ocrTextEdit = "";
}
return { insertType, ocrTextEdit };
}
// 复制内容到剪切板
function copyToClipboard(extrTexts) {
const txtArea = document.createElement('textarea');
txtArea.value = extrTexts;
document.body.appendChild(txtArea);
txtArea.select();
if (document.execCommand('copy')) {
console.log('copy to clipboard.');
} else {
console.log('fail to copy.');
}
document.body.removeChild(txtArea);
}
// 读取Json数据文件转为对象
function readJsonData(jsonPath, data) {
if (!fs.existsSync(jsonPath)) {
console.log('文件不存在');
fs.writeFileSync(jsonPath, JSON.stringify(data));
} else {
console.log('文件已存在');
}
const existingDataString = fs.readFileSync(jsonPath, 'utf8');
let jsonData = JSON.parse(existingDataString);
return jsonData;
}
// 获取文件路径下的md中的文本(排除Yaml)
function getMarkdownText(filePath) {
// 获取文件的完整路径
const fileFullPath = app.vault.adapter.getFullPath(filePath);
// 读取文件内容
const fileContent = fs.readFileSync(fileFullPath, 'utf8');
// 排除首行YAML区域
const markdownText = fileContent.replace(/---[\s\S]*?---/, '').replace(/\n\n/, "\n");
return markdownText;
}
// 由文件列表和el元素获取文件路径(相对路径)
function getFilePath(files, el) {
let files2 = files.filter(f => path.basename(f.path).replace(".md", "").endsWith(el.link.replace(/\[\[/, "").replace(/\|.*]]/, "").replace(/\]\]/, "").replace(".md", "")));
let filePath = files2.map((f) => f.path)[0];
console.log(filePath);
return filePath;
}