
自定义 Excalidraw 脚本 - OCR 自动提取图片文字
Cite
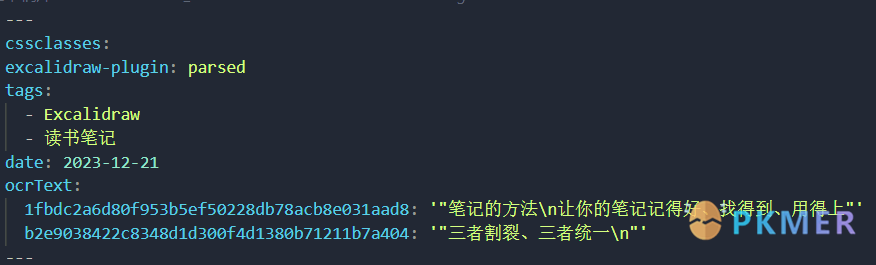
对 Excalidraw 的图片进行 OCR,并保留文本信息在图片中,可以编辑修改、重新 OCR 和进行批量识别。
脚本文件
脚本链接
可以用 Excalidraw Scripts 代码块安装:
https://raw.githubusercontent.com/PandaNocturne/ExcalidrawScripts/master/PandaScripts/TextExtractor.md配置文件
配置文件 paddleocr.zip,解压到到
.obsidian文件夹下即可采用脚本的默认配置:
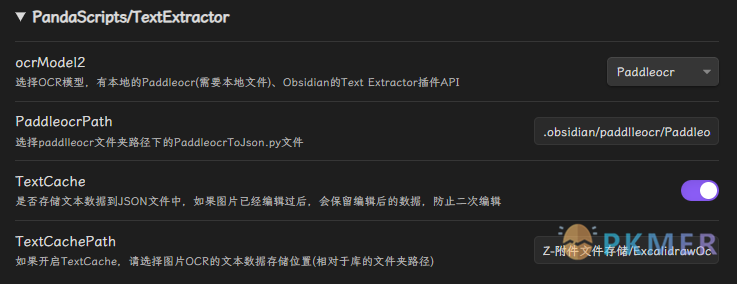
脚本思路
- 对图片添加弹窗,如果不存在 OCR 文本则进行 OCR,然后保留数据文本在 Yaml 中 (参考 Excalidraw 自带的识别保留识别数据结构),弹窗可以添加。
- 对图片进行 OCR,可以保存数据为到指定 Cache 文件夹为 Json 数据 (参考 Text Extractor 的数据存储结构)
- OCR 借助的 Text Extractor插件的API
在控制台的使用 Text Extractor 的 API 案例:
function getTextExtractor() {
return app.plugins.plugins['text-extractor'].api;
}
// Example usage
let file={
path:'Y-图形文件存储/ZoteroImages/JPQENLZK.png',
};
const text = await getTextExtractor().extractText(file)
console.log(text)OcrText 保存方式
默认只会保留图片编辑后的数据文件到画板的 Yaml 区域:
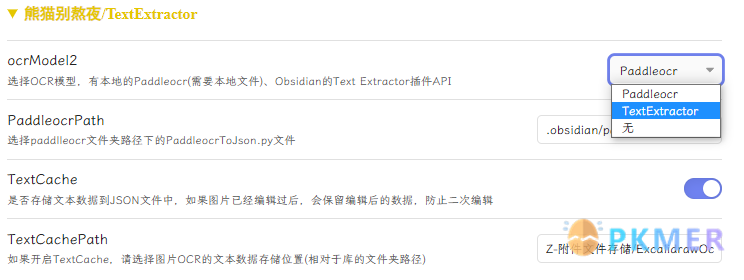
如果图片不存在,该 Yaml 对应的值会在下一次运行脚本的时候删除,减少冗余数据
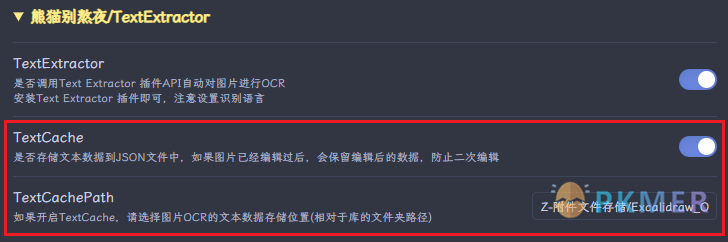
TextCache 本地数据缓存
对同一个图片的编辑结果在其他画板中不会保留,因此在设置选项中有 TextCache 选项可以保存同一张图片的编辑结果,使你在不同画板中对同一个图片的编辑数据保留,如果更改,存储数据也会更改,数据保存格式为 Json 文件。
📌注意:开启后,需要配置数据保存的文件夹,相对库的相对路径
选中多个图片可以进行批量识别但不会弹窗
Ocr 识别模式
识别模式 1:插件 Text Extractor
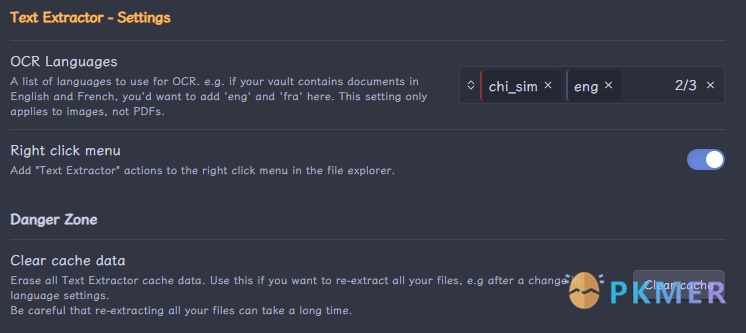
需要配置 Text Extractor 插件安装即可使用,注意要在 Text Extractor 插件设置里面开启中文识别模式,这样中文的准确率会稍微好一点。
Text Extractor 设置参数如下:

识别模式 2:本地模型 Paddleocr
采用的是百度的飞桨 Paddleocr 模型,中文识别率会好很多。
如果不会配置请使用 Text Extractor 的识别方法
前者脚本只需要配合 Text Extractor 插件联网使用,后者需要手动安装配置文件可以离线使用且与 Text Extractor 插件兼容。
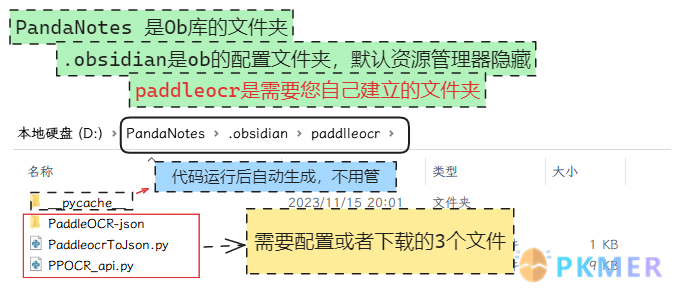
再开始配置之前我先展示下下面代码的大概存储结构:
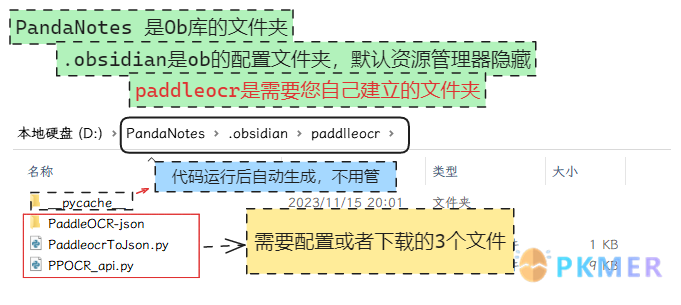
下载 PaddleOCR-json 模型
将压缩包解压为文件夹,改名为“PaddleOCR-json”,然后就不需要动了
采用 Python 调用的 PPOCR_api.py 文件
因为我 js 是半吊子,采用对的是 Python 调用的形式,代码能跑就行。
下载 PPOCR_api.py 或者复制下面代码为 PPOCR_api.py 文件中
# 调用 PaddleOCR-json.exe 的 Python Api
# 项目主页:
# https://github.com/hiroi-sora/PaddleOCR-json
import os
import socket # 套接字
import subprocess # 进程,管道
from json import loads as jsonLoads, dumps as jsonDumps
from sys import platform as sysPlatform # popen静默模式
from base64 import b64encode # base64 编码
class PPOCR_pipe:
"""调用OCR(管道模式)"""
def __init__(self, exePath: str, argument: dict = None):
"""初始化识别器(管道模式)。\n
`exePath`: 识别器`PaddleOCR_json.exe`的路径。\n
`argument`: 启动参数,字典`{"键":值}`。参数说明见 https://github.com/hiroi-sora/PaddleOCR-json
"""
cwd = os.path.abspath(os.path.join(exePath, os.pardir)) # 获取exe父文件夹
# 处理启动参数
if not argument == None:
for key, value in argument.items():
if isinstance(value, str): # 字符串类型的值加双引号
exePath += f' --{key}="{value}"'
else:
exePath += f" --{key}={value}"
# 设置子进程启用静默模式,不显示控制台窗口
startupinfo = None
if "win32" in str(sysPlatform).lower():
startupinfo = subprocess.STARTUPINFO()
startupinfo.dwFlags = subprocess.CREATE_NEW_CONSOLE | subprocess.STARTF_USESHOWWINDOW
startupinfo.wShowWindow = subprocess.SW_HIDE
self.ret = subprocess.Popen( # 打开管道
exePath, cwd=cwd,
stdin=subprocess.PIPE,
stdout=subprocess.PIPE,
stderr=subprocess.DEVNULL, # 丢弃stderr的内容
startupinfo=startupinfo # 开启静默模式
)
# 启动子进程
while True:
if not self.ret.poll() == None: # 子进程已退出,初始化失败
raise Exception(f"OCR init fail.")
initStr = self.ret.stdout.readline().decode("utf-8", errors="ignore")
if "OCR init completed." in initStr: # 初始化成功
break
def runDict(self, writeDict: dict):
"""传入指令字典,发送给引擎进程。\n
`writeDict`: 指令字典。\n
`return`: {"code": 识别码, "data": 内容列表或错误信息字符串}\n"""
# 检查子进程
if not self.ret.poll() == None:
return {"code": 901, "data": f"子进程已崩溃。"}
# 输入信息
writeStr = jsonDumps(writeDict, ensure_ascii=True, indent=None)+"\n"
try:
self.ret.stdin.write(writeStr.encode("utf-8"))
self.ret.stdin.flush()
except Exception as e:
return {"code": 902, "data": f"向识别器进程传入指令失败,疑似子进程已崩溃。{e}"}
# 获取返回值
try:
getStr = self.ret.stdout.readline().decode("utf-8", errors="ignore")
except Exception as e:
return {"code": 903, "data": f"读取识别器进程输出值失败。异常信息:[{e}]"}
try:
return jsonLoads(getStr)
except Exception as e:
return {"code": 904, "data": f"识别器输出值反序列化JSON失败。异常信息:[{e}]。原始内容:[{getStr}]"}
def run(self, imgPath: str):
"""对一张本地图片进行文字识别。\n
`exePath`: 图片路径。\n
`return`: {"code": 识别码, "data": 内容列表或错误信息字符串}\n"""
writeDict = {"image_path": imgPath}
return self.runDict(writeDict)
def runClipboard(self):
"""立刻对剪贴板第一位的图片进行文字识别。\n
`return`: {"code": 识别码, "data": 内容列表或错误信息字符串}\n"""
return self.run("clipboard")
def runBase64(self, imageBase64: str):
"""对一张编码为base64字符串的图片进行文字识别。\n
`imageBase64`: 图片base64字符串。\n
`return`: {"code": 识别码, "data": 内容列表或错误信息字符串}\n"""
writeDict = {"image_base64": imageBase64}
return self.runDict(writeDict)
def runBytes(self, imageBytes):
"""对一张图片的字节流信息进行文字识别。\n
`imageBytes`: 图片字节流。\n
`return`: {"code": 识别码, "data": 内容列表或错误信息字符串}\n"""
imageBase64 = b64encode(imageBytes).decode('utf-8')
return self.runBase64(imageBase64)
def exit(self):
"""关闭引擎子进程"""
self.ret.kill() # 关闭子进程
@staticmethod
def printResult(res: dict):
"""用于调试,格式化打印识别结果。\n
`res`: OCR识别结果。"""
# 识别成功
if res["code"] == 100:
index = 1
for line in res["data"]:
print(f"{index}-置信度:{round(line['score'], 2)},文本:{line['text']}")
index+=1
elif res["code"] == 100:
print("图片中未识别出文字。")
else:
print(f"图片识别失败。错误码:{res['code']},错误信息:{res['data']}")
def __del__(self):
self.exit()
class PPOCR_socket(PPOCR_pipe):
"""调用OCR(套接字模式)"""
def __init__(self, exePath: str, argument: dict = None):
"""初始化识别器(套接字模式)。\n
`exePath`: 识别器`PaddleOCR_json.exe`的路径。\n
`argument`: 启动参数,字典`{"键":值}`。参数说明见 https://github.com/hiroi-sora/PaddleOCR-json
"""
# 处理参数
if not argument:
argument = {}
argument["port"] = 0 # 随机端口号
argument["addr"] = "loopback" # 本地环回地址
super().__init__(exePath, argument) # 父类构造函数
# 再获取一行输出,检查是否成功启动服务器
initStr = self.ret.stdout.readline().decode("utf-8", errors="ignore")
if not self.ret.poll() == None: # 子进程已退出,初始化失败
raise Exception(f"Socket init fail.")
if "Socket init completed. " in initStr: # 初始化成功
splits = initStr.split(":")
self.ip = splits[0].split("Socket init completed. ")[1]
self.port = int(splits[1]) # 提取端口号
self.ret.stdout.close() # 关闭管道重定向,防止缓冲区填满导致堵塞
print(f"套接字服务器初始化成功。{self.ip}:{self.port}")
return
# 异常
self.exit()
raise Exception(f"Socket init fail.")
def runDict(self, writeDict: dict):
"""传入指令字典,发送给引擎进程。\n
`writeDict`: 指令字典。\n
`return`: {"code": 识别码, "data": 内容列表或错误信息字符串}\n"""
# 检查子进程
if not self.ret.poll() == None:
return {"code": 901, "data": f"子进程已崩溃。"}
# 通信
writeStr = jsonDumps(writeDict, ensure_ascii=True, indent=None)+"\n"
try:
# 创建TCP连接
clientSocket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
clientSocket.connect((self.ip, self.port))
# 发送数据
clientSocket.sendall(writeStr.encode())
# 接收数据
resData = b''
while True:
chunk = clientSocket.recv(1024)
if not chunk:
break
resData += chunk
getStr = resData.decode()
except ConnectionRefusedError:
return {"code":902, "data": "连接被拒绝"}
except TimeoutError:
return {"code":903, "data": "连接超时"}
except Exception as e:
return {"code":904, "data": f"网络错误:{e}"}
finally:
clientSocket.close() # 关闭连接
# 反序列输出信息
try:
return jsonLoads(getStr)
except Exception as e:
return {"code": 905, "data": f"识别器输出值反序列化JSON失败。异常信息:[{e}]。原始内容:[{getStr}]"}
def GetOcrApi(exePath: str, argument: dict = None, ipcMode: str = "pipe"):
"""获取识别器API对象。\n
`exePath`: 识别器`PaddleOCR_json.exe`的路径。\n
`argument`: 启动参数,字典`{"键":值}`。参数说明见 https://github.com/hiroi-sora/PaddleOCR-json\n
`ipcMode`: 进程通信模式,可选值为套接字模式`socket` 或 管道模式`pipe`。用法上完全一致。
"""
if ipcMode == "socket":
return PPOCR_socket(exePath, argument)
elif ipcMode == "pipe":
return PPOCR_pipe(exePath, argument)
else:
raise Exception(f'ipcMode可选值为 套接字模式"socket" 或 管道模式"pipe" ,不允许{ipcMode}。')
配置 PaddleocrToJson.py 文件
复制下面代码为 PaddleocrToJson.py 文件
#coding:utf-8
from PPOCR_api import GetOcrApi
import json
import os
import sys
# 测试图片路径
TestImagePath = sys.argv[1]
# 初始化识别器对象,传入 PaddleOCR-json.exe 的路径。
ocr = GetOcrApi(f"{os.path.dirname(os.path.abspath(__file__))}/PaddleOCR-json/PaddleOCR-json.exe")
# 识别本地图片
res = ocr.run(TestImagePath)
print(f'{json.dumps(res, ensure_ascii=False)}')3 个配置文件的结构形式
配置 TextExtractor 脚本
有 3 种模式

首次加载脚本
Tip首次次运行脚本或者重启 ob 会在 Excalidraw 插件中加载该选项

单个图片文本数据缓存功能同样也可以开启,只是在原基础上添加本地识别的模型而已
TextExtractor 本地版脚本
await ea.addElementsToView();
const api = ea.getExcalidrawAPI();
const fs = require('fs');
const path = require('path');
const Activefile = app.workspace.getActiveFile();
const { exec } = require('child_process');
const fileName = app.workspace.getActiveFile().name;
let settings = ea.getScriptSettings();
//set default values on first run
if (!settings["ocrModel2"]) {
settings = {
"ocrModel2": {
value: "Paddleocr",
valueset: ["Paddleocr", "TextExtractor", "无"],
description: "选择 OCR 模型,有本地的 Paddleocr(需要本地文件)、Obsidian 的 Text Extractor 插件 API",
},
"PaddleocrPath": {
value: ".obsidian/paddlleocr/PaddleocrToJson.py",
description: "选择 paddlleocr 文件夹路径下的 PaddleocrToJson.py 文件"
},
"TextCache": {
value: false,
description: "是否存储文本数据到 JSON 文件中,如果图片已经编辑过后,会保留编辑后的数据,防止二次编辑"
},
"TextCachePath": {
value: "",
description: "如果开启 TextCache,请选择图片 OCR 的文本数据存储位置(相对于库的文件夹路径)"
}
};
ea.setScriptSettings(settings);
}
// 获取库的基本路径
const basePath = (app.vault.adapter).getBasePath();
const textCachePath = `${basePath}/${settings["TextCachePath"].value}`;
if (!fs.existsSync(textCachePath)) {
fs.mkdirSync(textCachePath, { recursive: true });
console.log('配置路径已创建');
} else {
console.log('配置路径已存在');
}
// !添加 ocrText 属性
await app.fileManager.processFrontMatter(Activefile, fm => {
if (typeof fm[`ocrText`] !== 'object') fm[`ocrText`] = {};
});
console.log("写入 Yaml");
// ! text 类型
const selectedTextElements = ea.getViewSelectedElements().filter(el => el.type === "text");
if (selectedTextElements.length === 1) {
ea.copyViewElementsToEAforEditing(selectedTextElements);
const el = ea.getElements()[0];
let exText = el.rawText;
const { insertType, ocrTextEdit } = await openEditPrompt(exText);
if (insertType == "copyText") {
copyToClipboard(ocrTextEdit);
new Notice(`已复制文本`, 1000);
} else if (insertType) {
copyToClipboard(ocrTextEdit);
new Notice(`完成修改`, 500);
}
el.originalText = el.rawText = el.text = ocrTextEdit;
// 文本全部居左,居中
el.textAlign = "left";
el.textVerticalAlign = "middle";
ea.refreshTextElementSize(el.id);
await ea.addElementsToView(false, false);
if (el.containerId) {
const containers = ea.getViewElements().filter(e => e.id === el.containerId);
api.updateContainerSize(containers);
ea.selectElementsInView(containers);
}
return;
}
// ! frame 类型
const selectedFrameElements = ea.getViewSelectedElements().filter(el => el.type === "frame");
if (selectedFrameElements.length === 1) {
const el = selectedFrameElements[0];
let exText = el.name;
const { insertType, ocrTextEdit } = await openEditPrompt(exText, 1);
const frameLink = `[[${fileName}#^frame=${el.id}|${ocrTextEdit}]]`;
if (insertType == "copyText") {
copyToClipboard(frameLink);
new Notice(`已复制Frame${ocrTextEdit}的链接`, 2000);
} else if (insertType) {
copyToClipboard(frameLink);
new Notice(`完成修改并复制链接`, 500);
el.name = ocrTextEdit;
} else {
el.name = ocrTextEdit;
}
ea.copyViewElementsToEAforEditing(selectedFrameElements);
await ea.addElementsToView(false, true);
} else if ((selectedFrameElements.length > 1)) {
let frameLinks = [];
for (el of selectedFrameElements) {
const frameLink = `[[${fileName}#^frame=${el.id}|${el.name}]]`;
frameLinks.push(frameLink);
}
copyToClipboard(frameLinks.join("\n"));
ea.copyViewElementsToEAforEditing(selectedFrameElements);
await ea.addElementsToView(false, true);
new Notice(`已复制${frameLinks}链接`, 2000);
}
if (selectedFrameElements.length >= 1) {
// ! 给aliaes添加所有Frame的名称
const allFrameElements = ea.getViewElements().filter(el => el.type === "frame");
await app.fileManager.processFrontMatter(Activefile, fm => {
fm.aliases = [];
for (el of allFrameElements) {
fm.aliases.push(el.name);
}
})
await ea.addElementsToView();
}
// ! 图片 OCR 或文本编辑
const els = ea.getViewSelectedElements().filter(el => el.type === "text" || el.type === "image" || el.type === "embeddable");
if (els.length >= 1) {
// 是否为批处理
const nums = els.filter(el => el.type == "image" || el.type === "text").length;
let batchRecognition = false;
// 多文本则进行批处理
if (nums > 1) {
new Notice(`检测到${nums}张图片\n进行批量识别`, 500);
batchRecognition = true;
}
// 图片计数
let n = 0;
// 汇集所有文本集合
let allText = [];
// 获取库所有文件列表
const files = app.vault.getFiles();
for (let el of els) {
if (el.type == "image") {
let data = {
filePath: "",
fileId: "",
ocrText: "",
};
const currentPath = ea.plugin.filesMaster.get(el.fileId).path;
const file = app.vault.getAbstractFileByPath(currentPath);
// 获取图片路径
const imagePath = app.vault.adapter.getFullPath(file.path);
console.log(`获取图片路径:${imagePath}`);
const jsonPath = path.join(textCachePath, `${el.fileId}.json`);
// 判断是否进行存储Json数据
let jsonData = {};
if (settings["TextCache"].value) {
jsonData = readJsonData(jsonPath, data);
console.log(jsonData.valueOf());
} else {
jsonData = {};
}
// 初始化ocr文本
let ocrText = "";
let ocrText_yaml = "";
n++;
await app.fileManager.processFrontMatter(Activefile, fm => {
ocrText_yaml = fm[`ocrText`]?.[`${el.fileId}`];
});
if (ocrText_yaml) {
ocrText = JSON.parse(ocrText_yaml);
} else if (jsonData.ocrText) {
new Notice(`图片已存在OCR文本`, 500);
ocrText = jsonData.ocrText;
} else if (settings["ocrModel2"].value == "Paddleocr") {
new Notice(`图片OCR中......`);
// 其次执行Paddleocr,如果报错则会保留ocrText的值
const scriptPath = `${basePath}/${settings["PaddleocrPath"].value}`;
console.log(scriptPath);
await runPythonScript(scriptPath, imagePath)
.then(output => {
// 在这里处理Python脚本的输出
console.log(output);
let paddlleocrJson = JSON.parse(output);
let paddlleocrText = paddlleocrJson.data.map(item => item.text);
ocrText = paddlleocrText.join("\n");
new Notice(`第${n}张片已完成OCR`, 500);
})
.catch(error => {
new Notice(`Paddleocr识别失败,采用TextExtractor`);
console.error(error);
});
} else if (settings["ocrModel2"].value == "TextExtractor") {
new Notice(`图片OCR中......`);
const text = await getTextExtractor().extractText(file);
new Notice(`第${n}张片已完成OCR`, 500);
ocrText = processText(text);
}
if (!batchRecognition) {
const { insertType, ocrTextEdit } = await openEditPrompt(ocrText);
// 不管复制还是修改,都会保存
ocrText = ocrTextEdit;
if (insertType == "copyText") {
copyToClipboard(ocrTextEdit);
new Notice(`已复制:图片文本`, 1000);
} else if (insertType) {
new Notice(`完成修改`, 500);
}
}
// 更新数据源
data.filePath = file.path;
data.fileId = el.fileId;
data.ocrText = ocrText;
// 保存信息到Yaml区
await app.fileManager.processFrontMatter(Activefile, fm => {
fm[`ocrText`][`${el.fileId}`] = JSON.stringify(ocrText);
});
console.log("写入Yaml");
if (settings["TextCache"].value) {
// 保存数据到Json文件中
fs.writeFileSync(jsonPath, JSON.stringify(data));
}
// 收集提取的信息
allText.push(ocrText);
} else if (el.type == "text") {
let exText = el.rawText;
console.log(exText);
allText.push(exText);
} else if (el.type == "embeddable" && el.link.endsWith("]]")) {
let filePaths = getFilePath(files, el);
// 读取文件内容
let markdownText = getMarkdownText(filePaths);
console.log(markdownText);
allText.push(markdownText);
copyToClipboard(markdownText);
new Notice(`复制文本`, 3000);
}
await ea.addElementsToView(false, true);
}
await ea.addElementsToView(false, true);
if (batchRecognition) {
// 如果批量识别则直接进行复制文本
const output = allText.join("\n");
console.log(output);
new Notice(`✅已完成批量OCR`, 3000);
copyToClipboard(output);
new Notice(`📋复制所有文本到剪切板`, 3000);
}
}
// ! 如果图片不存在则清理 yaml 对应的 id
await app.fileManager.processFrontMatter(Activefile, fm => {
allels = ea.getViewElements();
Object.keys(fm.ocrText).forEach(key => {
console.log(key);
if ((!allels.some(el => `${el.fileId}` === key)) || fm[key] === "\"\"") {
delete fm.ocrText[key];
}
});
});
// 调用 Text Extractor 的 API
function getTextExtractor() {
return app.plugins.plugins['text-extractor'].api;
}
// 格式化文本
function processText(text) {
// 替换特殊空格为普通空格
text = text.replace(/[\ue5d2\u00a0\u2007\u202F\u3000\u314F\u316D\ue5cf]/g, ' ');
// 将全角字符转换为半角字符
text = text.replace(/[\uFF01-\uFF5E]/g, function (match) { return String.fromCharCode(match.charCodeAt(0) - 65248); });
// 替换英文之间的多个空格为一个空格
text = text.replace(/([a-zA-Z])([\u4e00-\u9fa5])/g, '$1 $2');
// 删除中文之间的空格
text = text.replace(/([0-9\.\u4e00-\u9fa5])\s+([0-9\.\u4e00-\u9fa5])/g, '$1$2');
text = text.replace(/([0-9\.\u4e00-\u9fa5])\s+([0-9\.\u4e00-\u9fa5])/g, '$1$2');
text = text.replace(/([\u4e00-\u9fa5])\s+/g, '$1');
text = text.replace(/\s+([\u4e00-\u9fa5])/g, '$1');
// 在中英文之间添加空格
text = text.replace(/([\u4e00-\u9fa5])([a-zA-Z])/g, '$1 $2');
text = text.replace(/([a-zA-Z])([\u4e00-\u9fa5])/g, '$1 $2');
return text;
}
// 打开文本编辑器
async function openEditPrompt(ocrText, n = 10) {
// 打开编辑窗口
let insertType = "";
let ocrTextEdit = await utils.inputPrompt(
"编辑文本",
"可以自行修改文字保存在图片的属性中,输入一个空格会重新识别,注意清空并不会清除数据",
ocrText,
[
{
caption: "修改",
action: () => {
insertType = "insertImage";
return;
}
},
{
caption: "复制",
action: () => {
insertType = "copyText";
return;
}
},
],
n,
true
);
if (!ocrTextEdit) {
ocrTextEdit = ocrText;
} else if (ocrTextEdit == " ") {
ocrTextEdit = "";
}
return { insertType, ocrTextEdit };
}
// 复制内容到剪切板
function copyToClipboard(extrTexts) {
const txtArea = document.createElement('textarea');
txtArea.value = extrTexts;
document.body.appendChild(txtArea);
txtArea.select();
if (document.execCommand('copy')) {
console.log('copy to clipboard.');
} else {
console.log('fail to copy.');
}
document.body.removeChild(txtArea);
}
// 读取 Json 数据文件转为对象
function readJsonData(jsonPath, data) {
if (!fs.existsSync(jsonPath)) {
console.log('文件不存在');
fs.writeFileSync(jsonPath, JSON.stringify(data));
} else {
console.log('文件已存在');
}
const existingDataString = fs.readFileSync(jsonPath, 'utf8');
let jsonData = JSON.parse(existingDataString);
return jsonData;
}
// 获取文件路径下的 md 中的文本(排除 Yaml)
function getMarkdownText(filePath) {
// 获取文件的完整路径
const fileFullPath = app.vault.adapter.getFullPath(filePath);
// 读取文件内容
const fileContent = fs.readFileSync(fileFullPath, 'utf8');
// 排除首行YAML区域
const markdownText = fileContent.replace(/---[\s\S]*?---/, '').replace(/\n\n/, "\n");
return markdownText;
}
// 由文件列表和 el 元素获取文件路径(相对路径)
function getFilePath(files, el) {
let files2 = files.filter(f => path.basename(f.path).replace(".md", "").endsWith(el.link.replace(/\[\[/, "").replace(/\|.\*]]/, "").replace(/\]\]/, "").replace(".md", "")));
let filePath = files2.map((f) => f.path)[0];
console.log(filePath);
return filePath;
}
// 运行本地 Python 文件
function runPythonScript(scriptPath, args) {
return new Promise((resolve, reject) => {
const command = `python "${scriptPath}" "${args}"`;
exec(command, (error, stdout, stderr) => {
if (error) {
console.error(`执行命令时发生错误: ${error.message}`);
reject(error);
}
if (stderr) {
console.error(`命令执行返回错误: ${stderr}`);
reject(stderr);
}
resolve(stdout.trim());
});
});
}
常见 bug
本地版运行不了或者出现 Bug,不想折腾请转插件版,另外你想继续深究这里可以提供几个常见 bug 以及解决方法:
- 本地版运行不了:
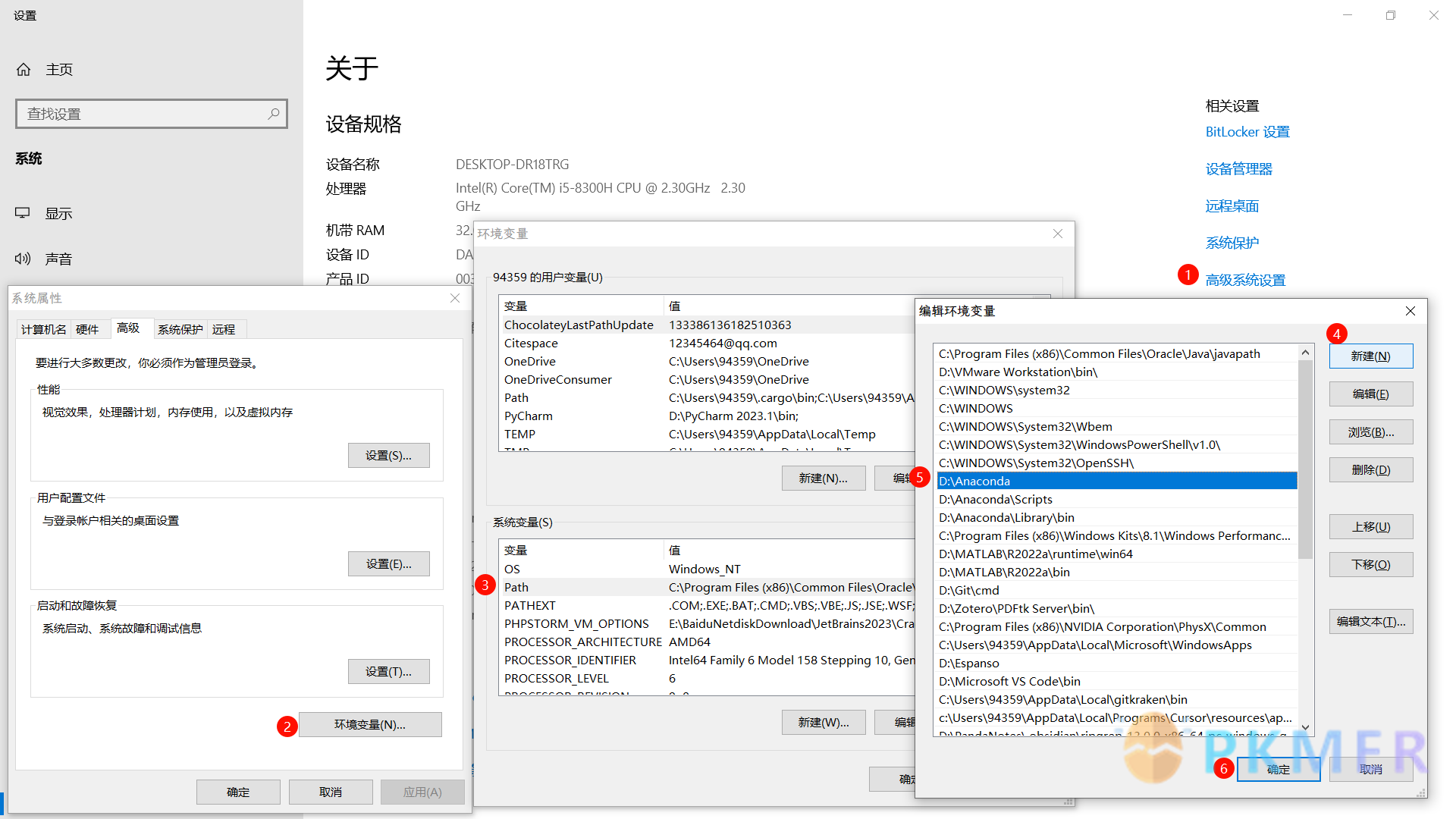
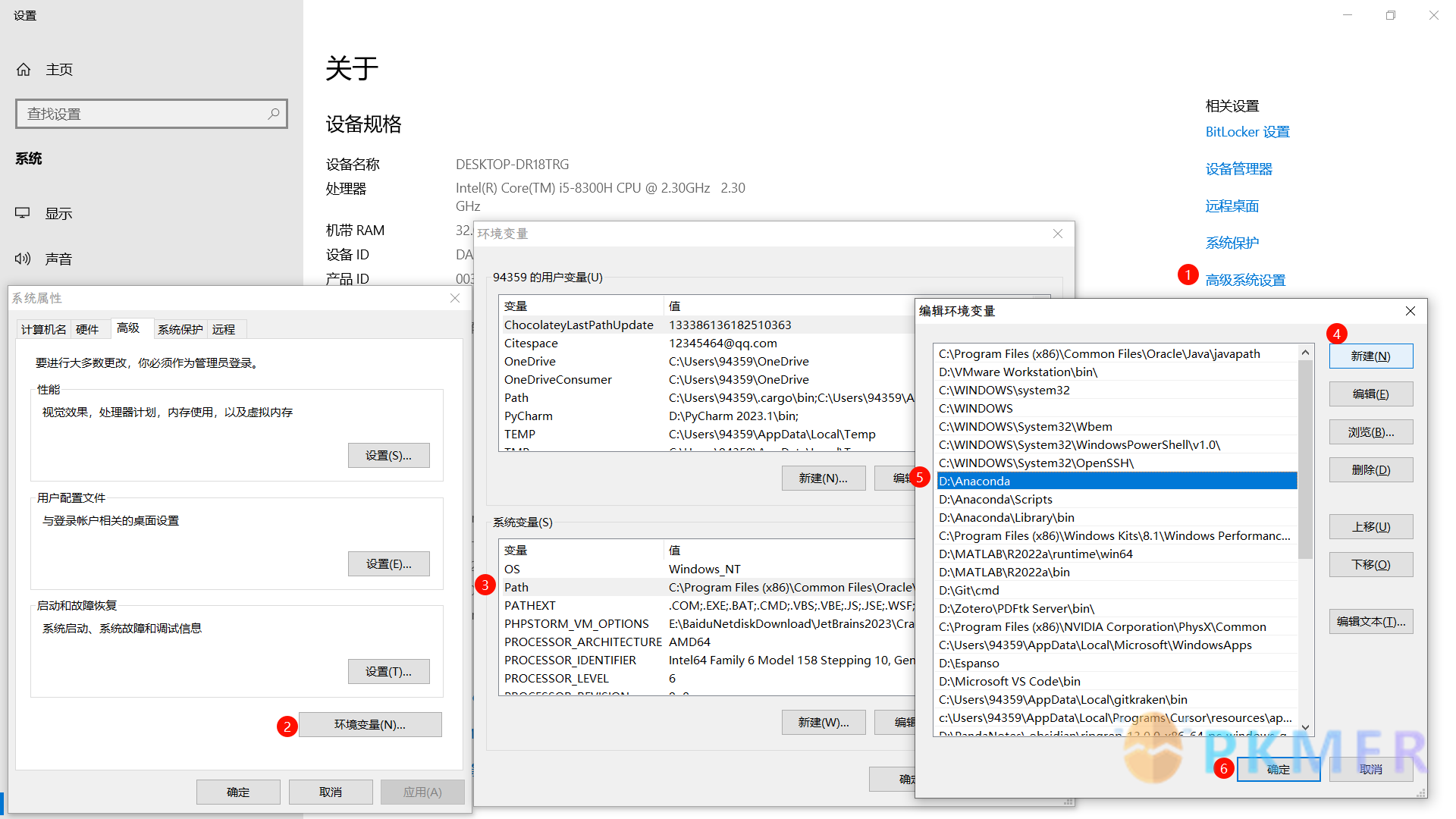
- 是否安装 Python 编辑器,有时候 Anaconda 装了但没有配置 Python 系统环境同样运行不了,
- 方法 1:安装官方 Python
- 方法 2:给 Anaconda 配置系统环境
- 是否安装 Python 编辑器,有时候 Anaconda 装了但没有配置 Python 系统环境同样运行不了,
- 识别出来的是乱码:
- 这是你没给 Python 配置 utf-8 的系统环境
PYTHONIOENCODINGUTF8
- 这是你没给 Python 配置 utf-8 的系统环境
已有的 bug 已经给你标注出来了,剩余的问题自己折腾,画板的这个功能其实用处不大,简单娱乐的脚本而已。
Log
因为我本人只使用本地模型的识别模式 2 的代码,所以修改部分全部更新在识别模式 2 中,识别模式 1 存在问题不会修复,识别模式 2 是兼容识别模式 1 的,只要不设置本地 Paddleocr 模式就行。
- 2023-12-29:
- 优化 OCR 识别文本的 Yaml 数据结构存储
- 修复修改文本后不同步问题
- 2024-03-02:
- 添加 当编辑 Frame 名称后,会将名称添加到 Yaml 的 aliases 属性中,方便通过别名来定位 Excalidraw 内的标题
讨论
若阁下有独到的见解或新颖的想法,诚邀您在文章下方留言,与大家共同探讨。

