obsidian社区插件
Dataview 语法实战 - 如何把一列内容拆到两列

插件ID:dataview%E8%AF%AD%E6%B3%95%E5%AE%9E%E6%88%98-%E5%A6%82%E4%BD%95%E6%8A%8A%E4%B8%80%E5%88%97%E5%86%85%E5%AE%B9%E6%8B%86%E5%88%B0%E4%B8%A4%E5%88%97
dataview%E8%AF%AD%E6%B3%95%E5%AE%9E%E6%88%98-%E5%A6%82%E4%BD%95%E6%8A%8A%E4%B8%80%E5%88%97%E5%86%85%E5%AE%B9%E6%8B%86%E5%88%B0%E4%B8%A4%E5%88%97
dataview%E8%AF%AD%E6%B3%95%E5%AE%9E%E6%88%98 %E5%A6%82%E4%BD%95%E6%8A%8A%E4%B8%80%E5%88%97%E5%86%85%E5%AE%B9%E6%8B%86%E5%88%B0%E4%B8%A4%E5%88%97:把某一行中的某列内容拆分成两列,更方便展示
Dataview 语法实战 - 如何把一列内容拆到两列
用个例子解释下我们想要做什么
统计所有标题『学习』下的无序列表,并且按照标签分列
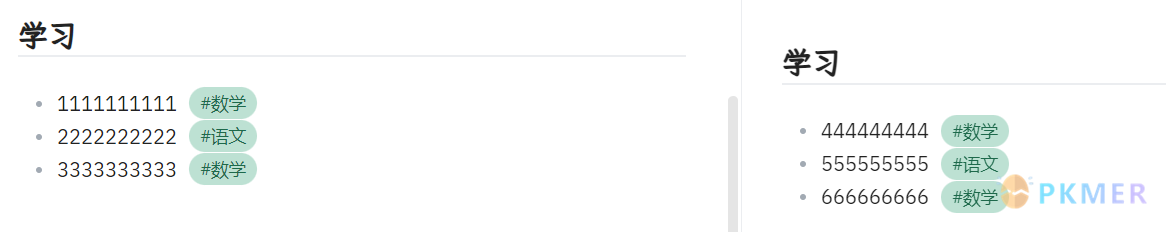
上图中我们有以上两个文件,他们都有标题『学习』以及一些带标签的无序列表。我们需要得到以下的 dv 检索结果

分别把带有数学标签和语文标签的拆分成两列,且维持依旧在同一行。
实现逻辑
- 第一步 - 获得标题下的所有无序列表:用 Dataview语法实战-列出特定标题下的元素 中讲过的做法,使用 FLATTEN 和 WHERE 即可。
- 第二步 - 按标题成组:经过第一步 FLATTEN 之后,我们的结果单位是一个个无序列表,但是我们预计的目标是标题,因此需要按照标题成组(如果确保每个文件中都只有一个这个标题,也可以直接按文件成组)
- 第三步 - 清除无需要的标签的列表:我们需要收集的是具有数学标签或者语文标签的列表,这里需要加个 WHERE 筛选,否则结果中会有空白行。
- 第四步 - 筛选所需结果:切记不是继续使用 WHERE 筛选,结果已经一行一行排列好了,我们要做的是筛选我们每一列呈现什么,因此我们需要借助 dv 提供的一些 Function 直接在输出结果出进行筛选。这里我选择使用
contains()和filter()判断该无序列表具有什么标签。
结果如下
```dataview
table without id
rows.file.link[0] as 日期,
filter(rows, (x) => contains(x.L.tags,"数学")).L.text as "数学",
filter(rows, (x) => contains(x.L.tags,"语文")).L.text as "语文"
from "Laboratory"
flatten file.lists as L
where meta(L.section).subpath = "学习"
group by meta(L.section)
where contains(rows.L.tags, "数学") or contains(rows.L.tags, "语文")
```更多 dataview 相关内容请见:dataview
讨论
若阁下有独到的见解或新颖的想法,诚邀您在文章下方留言,与大家共同探讨。

