obsidian社区插件
Dataview 支持的Data Commands 操作符

插件ID:23---%E6%93%8D%E4%BD%9C%E7%AC%A6
23---%E6%93%8D%E4%BD%9C%E7%AC%A6
23 --%E6%93%8D%E4%BD%9C%E7%AC%A6:基本语法学习指南,Data Commands 操作符,FROM,WHERE,SORT,FLATTEN,LIMIT,GROUP BY
Dataview 支持的 Data Commands 操作符
FROM
FROM <source> 语句用于决定你所有结果的来源,这些来源可以是:
- Tags:所有含有该标签的文件,用法是
FROM #tag - Folders:所有这个文件夹中的文件,用法是
FROM "文件夹" - Single Files:指定的文件,用法是
FROM "文件的路径" - Links:可以是所有引用了该文件的文件,或者是该文件引用的文件(引用是
[[文件]])- 收集所有引用了文件 A 的文件,语法为
FROM [[A]] - 收集文件 A 中引用了的文件,语法为
FROM outgoing([[A]])
- 收集所有引用了文件 A 的文件,语法为
小技巧
- 用
!或-代表非,比如FROM -#Tag或FROM !#Tag是指除了这个标签以外的文件,文件夹和文件也同样;- 不同的条件之间用 AND 和 OR 来表示“与”和“或”,用括号辅助明确“与”和“或”的关系;
- 如果没有 FROM 只有查询类型时,会查询所有的文件
示例
- 查询文件夹 PKMER/Dataview 中的所有文件:
```dataview
Table
From "PKMER/Dataview"
```- 查询文件夹 PKMER/Dataview 中的所有文件但不包含目录的文件:
```dataview
Table
From "PKMER/Dataview" and !"PKMER/Dataview/00-MOC 目录"
```- 查询引用了本文的文件(省略号处填查询的文件的标题):
```dataview
Table
From [[...]]
```[[00 - Dataview 基本语法学习指南]]引用的文件:
```dataview
Table
From outgoing([[00 - Dataview 基本语法学习指南]])
```WHERE
where 在英文中就是用来表示从句,就是用来做修饰用的。在这里对目标文件进行修饰就是筛选;
语法是 WHERE 加上约束条件:WHERE expression,满足约束条件的 file (文件) 或 task (任务) 保留;
- 约束条件:筛选满足 expression 条件的对象,expression 是一个结果为真或假的表达式,比如
1 + 1 = 2这个 表达式 的结果为真; - 约束条件可以配合比较大小和基本运算
<, >, <=, >=, =, +, - *, /使用; - 同时约束条件还可以使用许多 Dataview 提供的 函数;
- 如果你有一个属性名就是
where,那么你可以用row["where"]来替代 WHERE 操作符
示例
- 查找所有 24 小时以内修改过的文件(使用了比较运算符大于等于,以及函数
date(today)和dur()):
```dataview
LIST
WHERE file.mtime >= date(today) - dur(1 day)
```- 查找所有未完成且超过一个月的项目(使用了函数
date()和dur())
```dataview
LIST
FROM #projects
WHERE !completed AND file.ctime <= date(today) - dur(1 month)
```- 搜索所有未完成的并含有 shopping 标签的任务(使用了函数
contain())
```dataview
TASK
WHERE !completed AND contains(tags, "#shopping")
```SORT
对已经挑选出来的文件(或任务)按照某个规则进行排序,这个规则一般是按照某个可排序的属性升序降序排序
- 只依据一个属性排序时,语法为
SORT 属性 [ASC/DESC],其中 ASC 代表升序排序(从小到大),DESC 代表降序排序(从大到小),也可以写他们的全称 ASCENDING/DESCENDING; - 如果有两个文件,用于排序的属性值相同,还可以添加多个排序条件,语法为
示例
```
SORT 属性1 [ASC/DESC] 属性2 [ASC/DESC] ... 属性N [ASC/DESC]
```GROUP BY
成组,即对挑选出来的文件(或任务)按照某种规则进行分组。
- 规则一般是按照属性分类,比如按照文件是否 starred 分为两类,或是按照拥有的 tags 分类等。
- 分类之后,同一类的数据会合并并放在同一行,用关键字
rows指代,因此可以以此来继续操作每一行
示例
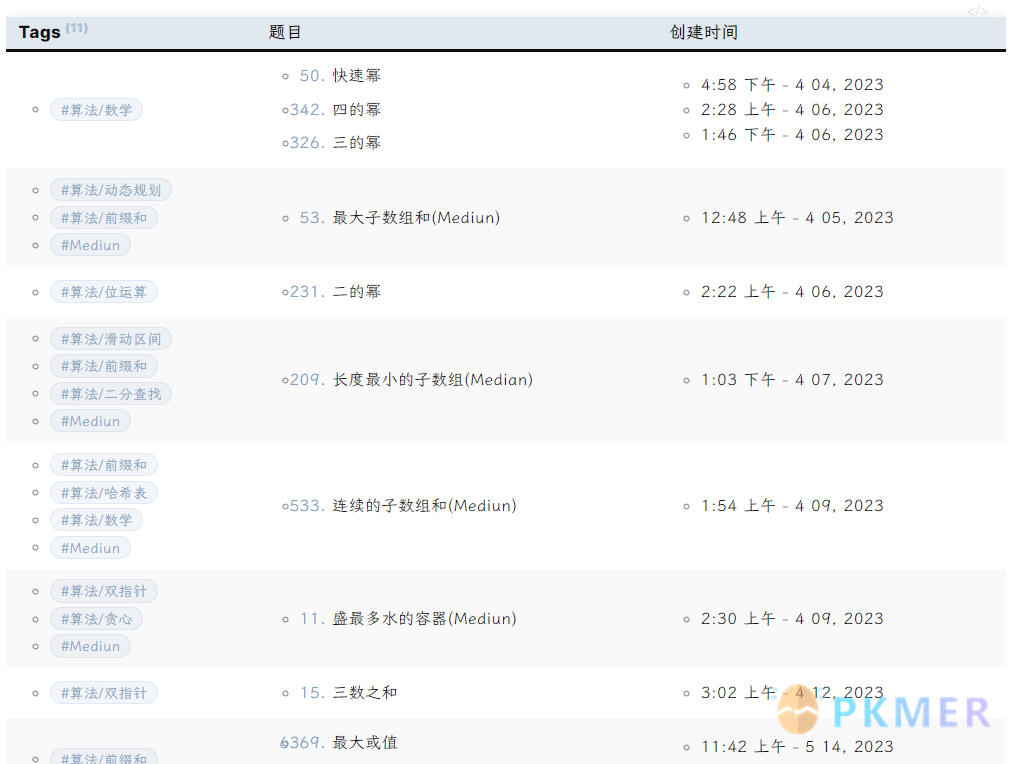
例子:按照拥有相同标签且均含有算法标签来分类题目,并且按照创建时间升序排列
```dataview
TABLE rows.file.name AS "题目", rows.file.ctime AS "创建时间"
FROM #算法
GROUP BY file.etags AS "Tags"
SORT rows.file.ctime ASC
```
FLATTEN
扁平化,将数组中的每一行都扁平化,即为数组中的每个条目生成一个结果行。
示例
例如,将每个文献注释中的作者字段平铺为每行一个作者
```dataview
TABLE authors
FROM #LiteratureNote
FLATTEN authors
```输出:
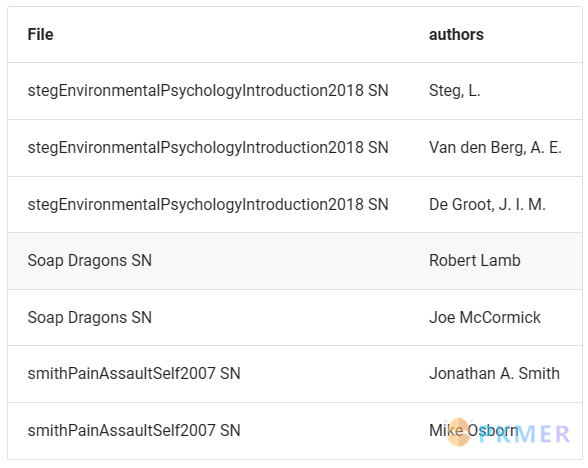
可见,第一个文献被拆分成三条,对应三个作者,后面两个同理。
如果我们给输入值不是原本文件里的值时,不会对我们的结果集造成什么影响。他就可以作为一种中间值构造一些描述词;(见 示例)
LIMIT
用于限制数量,没有很复杂的语法,比如 LIMIT 5 就是指只取五条,一般会配合 SORT 使用;
示例
例子:搜索最近一个月内创建的前 10 个文件
```dataview
TABLE
WHERE file.mtime >= date(today) - dur(1 day)
LIMIT 10
```注意
因为 Dataview 是按顺序自上而下执行代码,所以如果你先使用了 Limit 操作符,得到的结果可能就不是预期的结果了。所以建议除非有特殊需求,否则 LIMIT 应该在最后一行使用。
接下来,我们开始学习 dataview 语法的 24 - 表达式
讨论
若阁下有独到的见解或新颖的想法,诚邀您在文章下方留言,与大家共同探讨。

反馈交流

其他渠道
版权声明
版权声明:所有 PKMer 文章如果需要转载,请附上原文出处链接。