
通过 Dataview 实现汇总显示笔记内的关键信息
本文的效果预览:

开篇
当我在学习新事物时,我会一边看资料,一边记笔记。
记笔记的过程中,会冒出来一些新的想法,这时候我就会打个标记:
💡 这个方法可以应用在 XX 领域
或者,如果碰到了暂时不太明白的地方,为了之后能再深入研究,我也会先记上:
❗ 没搞懂 OO 的含义,回头再了解一下
而当我完成初步的学习,就需要把这些“关键内容”摘取出来,汇总查看。
这时候应该怎么做呢?
手动一个个复制粘贴——可以,但太过低效 也不优雅 。
好在我用的笔记软件是超强可定制功能嘎嘎多的 Obsidian!

在 Obsidian 里,我们可以使用 Dataview 插件来实现想要的效果。
它可以像下图这样将含有关键字的内容聚合显示,并且能跟随笔记内容实时更新。

实现方法
首先,你需要安装 Dataview 插件。
这在 OB 用户里算是常识了,这里略过。
有需要的话可以查看 Dataview 基础教程 Dataview基本语法
安装完之后,复制下面的代码到你的笔记里:
↓ 从这里开始
[term::💡]
```dataviewjs
const term = await dv.current().term;
const curFile = await dv.current().file;
if (curFile) {
const curFilePath = curFile.path;
const curTFile = await app.vault.getFileByPath(curFilePath);
const content = await app.vault.cachedRead(curTFile);
const lines = content.split("\n").filter(line => line.contains(term)).filter(line => !line.contains("term"))
dv.paragraph(`> 包含 [${term}] 的行:`);
dv.list(lines.flat())
} else {
dv.paragraph(`正在获取含${term}的行`);
}
```↑ 到这里结束
walla!这样就完成了。
实际使用时,只需把「💡」改成自己想要查询的字符——可以是 Emoji,也可以是特定的文本——下面的 dv 模块就会把当前笔记中含有该内容的文字都显示在一起。
例如,修改成❗就会提取出所有包含❗的文本,修改成「注意」就会提取出所有包含「注意」的文本。
更改关键字
出于性能考虑,dvjs 会隔一段时间再自动刷新。
因此,更改关键字之后,你可以通过「编辑代码块 ->退出编辑」的方式来手动更新 dvjs 的查询内容。
只需要使用的话,看到这里就可以了,祝你用得愉快!
但是这段代码只是最基础的版本,只能展示出内容,不支持跳转。
下面的 Obsidian汇总显示笔记内的关键信息#拓展功能 部分还提供了更多厉害的功能,感兴趣的话可以看下去 ⬇️
更进一步
因为我有很多笔记都需要用到这个功能,每次都复制粘贴一大段代码太麻烦了,怎么办呢?
功能更强的独立脚本
首先,Dataview 提供了一个 dv.view() 的功能,可以加载特定的 js 文件。
换而言之,我可以把上面 dvjs 里的所有代码都写进一个单独的 js 文件,然后加载这个 js 文件里的代码。
这样一来,dvjs 只需要传入参数,就能依赖外部脚本来获取结果。
这样的好处是,只要我修改 js 文件,所有用到这段代码的地方都会一起更新。
而且放在单独的文件里也能写多点内容,丰富一下功能。
使用单独脚本的时候,笔记里的 dvjs 代码块只需要这样写就可以:
[term::💡]
```dataviewjs
await dv.view("queryTermInFile", {term: dv.current().term})
```或者为了更省事儿,你也可以去掉内联属性,直接写上要搜索的关键字:
```dataviewjs
await dv.view("queryTermInFile", {term: "💡"})
```与此同时,你需要在 OB 库里创建一个叫做 queryTermInFile.js 的 js 文件。
你可以直接在这里查看并下载最新版本的脚本文件:
Dvjs code for Obsidian to query specific term in current note.
JS 文件里粘贴以下内容:
// ========================================
// 作者:Moy
// 日期:2024.05.22
// 版本:1.0.4
// ========================================
class Query {
/**
* 用来查询的类
* @param {string} _term 需要查询的关键字
* @param {boolean} _bShowInfo 是否显示第一行的查询信息
* @param {string} _info 查询信息的内容
* @param {boolean} _bShowLink 是否显示跳转链接
* @param {boolean} _bShowHeading 是否显示标题
* @param {string[]} _excludeTerms 需要排除的关键字
*/
constructor(_term, _bShowInfo=true, _info="", _bShowLink=true, _bShowHeading=false, _excludeTerms=[]) {
this.term = (_term == "加粗") ? "**" : ((_term == "高亮") ? "==" : _term);
const { output, isMulti } = processMultiValues(this.term);
this.term = output;
this.isMultiTerm = isMulti;
// 正则的处理
this.reg = null;
if (this.term.startsWith("/") && this.term.endsWith("/")) {
// 判断 正则表达式是否合法
try {
console.log("判断到正则表达式:", this.term.substring(1, this.term.length-1));
this.reg = new RegExp(this.term.substring(1, this.term.length-1), "i");
} catch (error) {
this.term = "(错误的正则表达式)";
}
}
this.bShowInfo = _bShowInfo;
this.info = processMultiValues(_info).output;
this.bShowLink = _bShowLink;
this.bShowHeading = _bShowHeading;
this.excludeTerms = _excludeTerms;
// 链接的图标
this.linkIcon = "»";
// 链接的字号
this.fontSize = "1em";
}
/**
* 判断是否包含关键字(或符合正则表达式)
* @param {string} text 需要判断的文本
* @returns {boolean} 返回是否包含关键字(或符合正则表达式)
*/
Verify(text) {
// 过滤掉需要排除的关键字
if (this.excludeTerms.some(f => text.contains(f))){
return false;
}
// 过滤掉 term 和 dv.view 关键字,避免把检索代码也显示出来
if (text.contains("dv.view") || text.contains("term")){
return false;
}
// 匹配给定的关键字
if (this.reg) {
return this.reg.test(text);
} else {
return text.includes(this.term);
}
}
/**
* 获取标题
* @param {number} line 行号
* @returns {string} 返回标题
*/
FetchHeadings(headings, line) {
let heading = "";
let isLastHeading = true;
if (!headings || headings.length == 0) {
return heading;
}
for (let i = 1; i < headings.length; i++) {
// 判断在哪个标题内
if (headings[i].position.start.line > line) {
// console.log("标题:", headings[i-1].heading);
heading = headings[i-1].heading;
isLastHeading = false;
break;
}
}
if (isLastHeading) {
heading = headings[headings.length-1].heading;
}
return heading;
}
/**
* 获取并输出最终的显示结果
* @returns {string} 返回最终的显示结果
*/
async GetResult() {
const term = this.term;
const curFile = await dv.current().file;
const curFilePath = curFile.path;
const curFileName = curFile.name;
const curTFile = await app.vault.getFileByPath(curFilePath);
const fileCache = app.metadataCache.getFileCache(curTFile);
const headings = fileCache.headings;
if (!curTFile) {
dv.paragraph(`正在获取含 [${term}] 的行...`);
return;
}
// 利用 AdvURI 的方案
const encodedName = encodeURIComponent(curFileName);
const extraAttr = `style="font-size: ${this.fontSize}" title="跳转到对应行" `;
const linkPrefix = ` <a ${extraAttr} href="obsidian://advanced-uri?filename=${encodedName}&line=`;
const linkSuffix = `">${this.linkIcon}</a>`;
const noteContent = await app.vault.cachedRead(curTFile);
const lines = noteContent.split("\n")
// 先存成对象,保证原来的行号
.map((line, index) => ({ content: line.trim(), index }))
// 过滤
.filter( ( {content} ) => this.Verify(content))
// 后处理
.map(( {content, index} ) => {
// 处理原先的列表符号,避免多层嵌套
if (content.startsWith("- ") || content.startsWith("* ") || content.startsWith("+ ") ) {
content = content.substring(2);
}
const line = index+1;
// 添加标题
let heading = this.bShowHeading ? this.FetchHeadings(headings, line) : "";
// 添加跳转链接
const jumpLink = `${linkPrefix}${index+1}${linkSuffix}`;
return { content , jumpLink, heading };
});
if (this.bShowInfo) {
if (this.info){
dv.paragraph(`> ${this.info}:`);
} else {
if (this.reg) {
dv.paragraph(`> 正则匹配 ${this.term} 的行:`);
} else {
dv.paragraph(`> 包含 [${term}] 的行:`);
}
}
}
if (lines.length) {
// 直接调用 list 来显示,会导致样式渲染问题
// dv.list(lines.map( ({content, jumpLink}) => `${content} ${this.bShowLink ? jumpLink : ""}`));
// 为了兼容下划线啥的……避免被作为样式渲染
const divContainer = document.createElement('div');
const listContainer = document.createElement('ul', { cls: "dataview dataview-class", attr: { alt: "Nice!" }});
let lastHeading = "";
lines.forEach( ({content, jumpLink, heading}) => {
// 添加标题
if (heading != lastHeading) {
const headingContainer = document.createElement('div');
let isFirstLine = lastHeading == "";
lastHeading = heading;
headingContainer.innerHTML = (isFirstLine?"":"<br>") + `▌ ${lastHeading}`;
// 设置下划线
// headingContainer.style.textDecoration = "underline";
listContainer.appendChild(headingContainer);
}
// 手工实现列表 = =。
const itemContainer = document.createElement('li');
itemContainer.appendChild(dv.span(content))
// itemContainer.innerHTML = content;
if (this.bShowLink) {
const linkContainer = document.createElement('span');
linkContainer.innerHTML = jumpLink;
itemContainer.appendChild(linkContainer);
// itemContainer.innerHTML += jumpLink;
}
listContainer.appendChild(itemContainer);
});
divContainer.appendChild(listContainer);
dv.container.appendChild(divContainer);
return;
}
if (this.term == "(未定义)") {
dv.paragraph(`(请在笔记属性里输入有效的关键字,或者直接指定 \`term: 关键字\` )`);
return;
}
if (this.isMultiTerm) {
dv.paragraph(`*(检测到页面内存在多个关键字,仅显示第一项 [${this.term}] 的查询结果)*`);
} else {
dv.paragraph(`- 没有找到含 [${term}] 的行`);
}
}
}
function processMultiValues(input) {
/**
* 处理多个值的情况
* @param {string | string[]} input 输入的值
* @returns {object} 返回处理后的值和是否为多个值
*/
let output = input;
if (typeof(input) != "string" && input.length > 1) {
output = "(未定义)";
// 设为第一个非空的值
const filteredTerms = input.filter(t => t && t.trim() != "");
if (filteredTerms.length > 0) {
output = filteredTerms[0];
}
return {output, isMulti: true};
} else {
return {output, isMulti: false};
}
}
/* ---------------------------------------- */
// 运行代码
/* ---------------------------------------- */
console.log("🔍 Querying...");
let { term, bShowInfo, info, bShowLink, bShowHeading, excludeTerms } = input;
if (!term) term = "(未定义)";
let query = new Query( term, bShowInfo, info, bShowLink, bShowHeading, excludeTerms );
query.GetResult();
这段 JS 代码很长,因为我加了很多厉害的工作并做了各种防呆适配。
不用细看,闭着眼睛粘贴进去就行了。
拓展功能说明
独立脚本比起 dvjs 直接内嵌的代码块多了一些功能,这里也说明一下。
跳转到文本
可以注意到,独立脚本版的每行文字后面都带上了一个 » 符号:
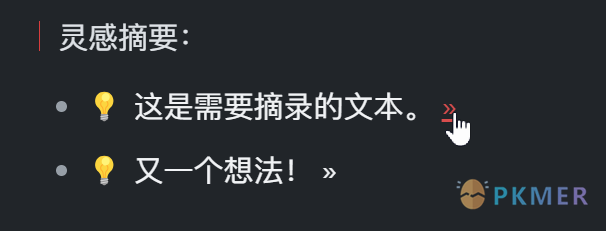
点击就可以跳转到这行所在的位置,方便查看上下文或进行编辑。
跳转功能
注意,跳转到某行的功能需要安装插件 Advanced URI。
你可以查看这篇文章获得更多信息:obsidian-advanced-uri
匹配加粗或高亮文本
如果你喜欢用 加粗 文本或者 高亮 文本在笔记里划重点的话,脚本额外提供了两个属性值用来提取这类内容。
term填写加粗可以提取出所有带有加粗文本的内容;term填写高亮可以提取出所有带有高亮文本的内容;
这俩符号因为本身会带有渲染,所以提供了关键字的替换。
正则匹配
如果你希望使用正则匹配,可以用 / 包裹住关键字。
语法和 JS 的正则匹配语法一致,脚本在检测到正则的时候会自动切换成正则匹配模式。
例如:/\d+/ 可以匹配多个数字。
定制显示内容
事实上,你可以把 dvjs 拓展成这样带有多个参数的代码块:
```dataviewjs
await dv.view(
"queryTermInFile",
{
term: dv.current().term,
bShowInfo: true,
bShowLink: true,
info: "灵感摘要",
excludeTerms: []
})
```别看它很长,最基本的结构其实还是这样:
await dv.view("js文件", {属性: 值, 另一个属性: 值})我们的脚本文件叫做 queryTermInFile,所以第一个参数填写这个文件的名字,让 dvjs 知道要去调用这个脚本。
第二个参数相当于是一些附加的配置,用来定制渲染的内容。
- term:和原先一样,获取当前笔记的
term属性作为搜索的关键字 - bShowInfo:是否显示第一行的信息,默认
true是显示,改成false可以隐藏 - info:第一行的信息,可以用自定义
- bShowLink:是否显示跳转到文本的链接,改成
false可以隐藏 - bShowHeading:是否显示文本所在的标题
- excludeTerms:一个列表,用来排除特定的关键字;比如说,我要排除包含“测试”和“取消”的行,这里就写成
excludeTerms: ["测试", "取消"]
只需要填写自己需要的参数就可以。
举个例子,我想要把标题显示出来,并隐藏第一行信息,就可以改成:
```dataviewjs
await dv.view(
"queryTermInFile",
{
term: dv.current().term,
bShowInfo: false,
bShowHeading: true
})
```使用模板快速插入
解释完了参数,该解决怎么快速插入的问题了。
如果你不想每次都输入 await dv.view("queryTermInFile", {term: dv.current().term}) 这一段代码,可以使用 Templater 插件,创建一个模板文件:
[term::] [info::]
```dataviewjs
await dv.view(
"queryTermInFile",
{
term: dv.current().term,
bShowInfo: true,
info: dv.current().info,
bShowLink: false,
bShowHeading: false,
excludeTerms: []
})
```然后在需要检索的时候直接插入这个模板,并修改检索的关键字即可。
Templater 插件也是 OB 用户基操了,templater-obsidian 这里不再介绍,有需要了解可以看文档:Templater插件基本语法格式
多个关键字查询
当前的脚本不支持多个关键字的查询,或者说,一次只认一个 term 属性,如果你定义了多次,它只会显示出首个 term 的结果。
如果想查询多个关键字,你可以起新的属性名,比如 term2::另一个关键字
然后相应地把 dvjs 里的 term 也替换成 term2,这样就能同时查询多个关键字了。
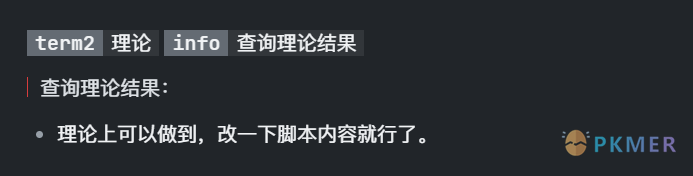
汇总不同文件的关键字内容
理论上可以做到,改一下脚本内容就行了。
但是我自己暂时没这个需求,所以就先不折腾了。
这里只简单讲一下思路:
目前是用 const curFile = await dv.current().file; 获取当前文件,如果改成 app.vault.getMarkdownFiles() 就能获取库里的所有文件,对它们逐个遍历就可以了。
⚠️ 但是也请注意,这样会导致运算量大幅增加,可能造成卡顿。
原理解析
所谓「授人以鱼,不如授人以渔」。
如果你好奇这个功能的原理,接下来的内容是为你准备的。
可能会有点长,但我会尽量讲解得清晰易懂,别担心!
这次的功能使用了 Dataview 插件的两个特性:
- Inline Field 内联属性
- DataviewJS 代码
内联属性
内联属性是像 key::value 这样格式的文本,写在笔记的任意一个位置就相当于给这个笔记添加了一条属性。
例如写上 姓名::张三 ,就相当于给这个笔记设置了一个「姓名」属性,对应的值是「张三」。
内联属性的要义是两个英文的冒号,双冒号 :: 左边代表属性名称,右边代表属性的值,拼在一起就组成了一个属性的定义。

如果两边加上英文圆括号,就会只显示值;
如果两边加上英文中括号,就会渲染成好看的样式。
另外,在加上括号的情况下,一行里可以写多个属性的定义。
DataviewJS
Dataview JS 是使用 Javascript 语言写的一段脚本,Dataview 插件会解析这段脚本的内容并渲染出来。
在 Obsidian 内,包裹在 ```dataviewjs ``` 内的 代码块都会被解析为 DataviewJS 脚本(下文简称为 dvjs )。
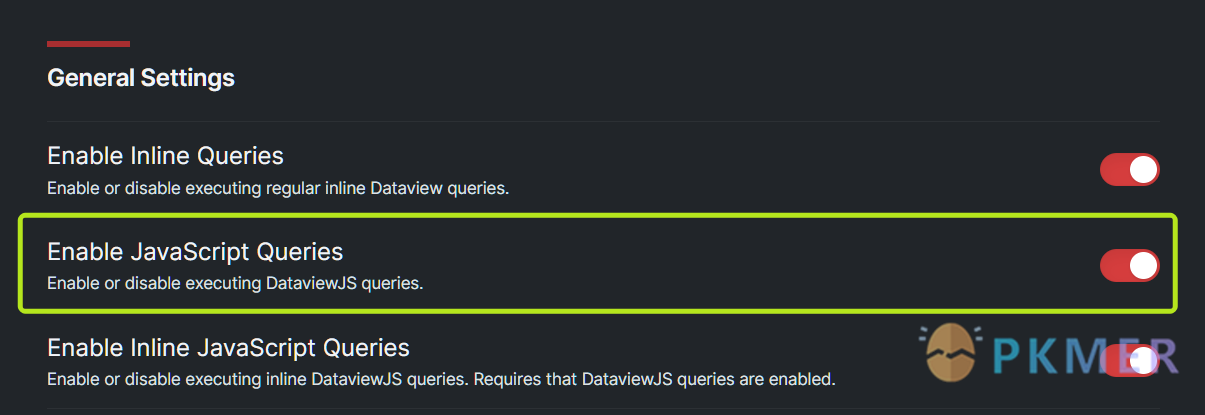
启用 dvjs 查询功能
注意,你需要在 Dataview 插件的设置中启用 Enable JavaScript Queries 选项才能应用 dvjs 脚本:
事实上,写在 dataviewjs 代码块里的内容基本等同于用 Javascript 语言编程,所以可以实现一些相当复杂的功能。
获取文件信息
具体的 JS 语言我们这里就不深入了,只简单了解一下 Dvjs 相关的语法。
例如:
const term = await dv.current().term;
const curFile = await dv.current().file;这里我们用 dv.current() 获取了当前的文件,以便查询文件内的数据。
如果你在笔记里粘贴这段内容:
// 使用 console.log 打印当前笔记的信息
console.log(dv.current())
dv.paragraph("> 这段脚本打印了当前文件的信息,请在控制台查看")然后按 Ctrl+Shfit+I 显示开发者工具,点开那个三角箭头,你就能看到「当前文件」包含了哪些内容:
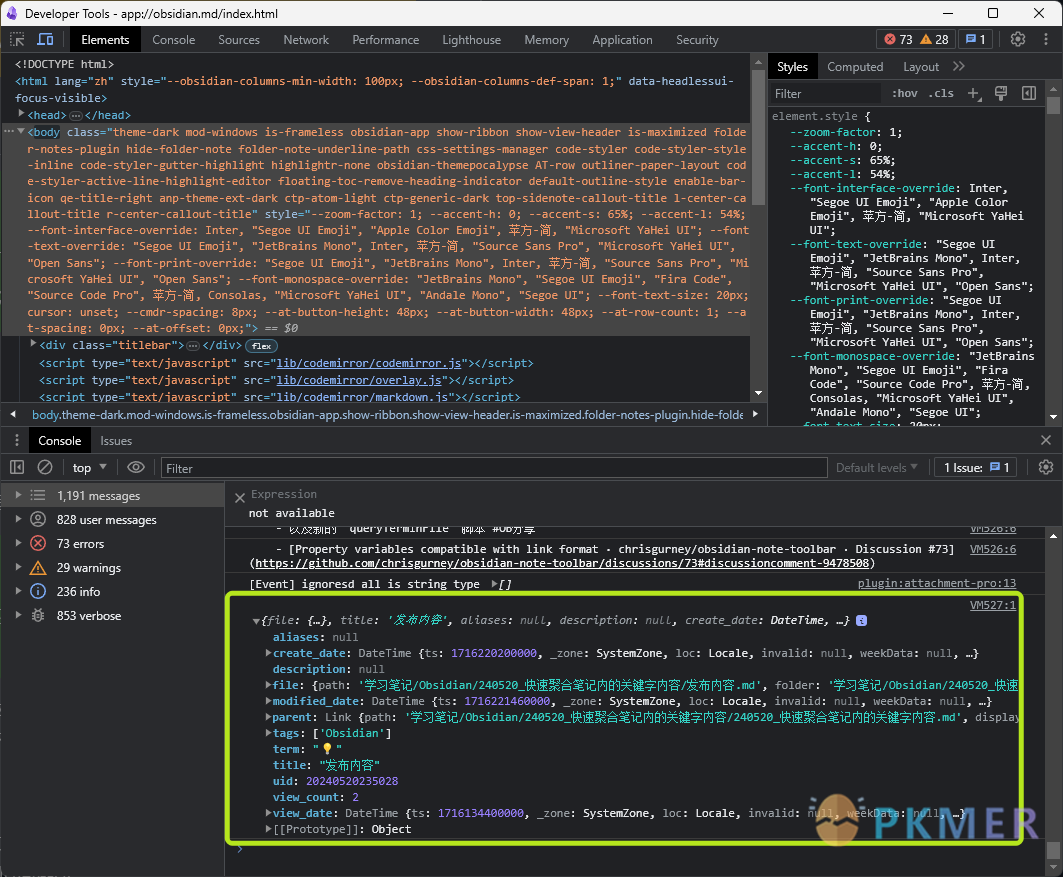
在这里可以看到,term: "💡" 属性已经被放进文件内了。
所以我们用 await dv.current().term 就能获取到我们写在 term 属性里的文本内容。
内联属性不是必要的
这里我们使用内联属性只是为了好看……咳,我是说,方便编辑。
事实上你在 dvjs 里直接写const term = "💡"也是一样的。
后面的代码是 JS 脚本的内容,这里就不深入了,前端开发长路漫漫,最好别踏上这条不归路。

总之,这段代码就是获取了当前笔记的所有文本内容,拆成一行行,然后看「这行里包含关键字吗?包含,那就塞进列表里」。
最后用 dv.list() 把列表里的每个句子显示出来,完事儿。
更多关于 Dataview JS 的脚本说明,可以查看插件的官方文档:Codeblock Reference - Dataview
总结
总的来说,这篇文章介绍了:
- 如何用 Dataview 插件查询文章内的特定关键字
- Dataview 插件的内联属性和 dvjs 说明
- 将 dvjs 代码提取成单独脚本,方便复用
这篇文章除了分享这个技巧之外,也是想基于一个实例去讲解 Dataview 的用法和原理,希望可以帮助到大家举一反三,实现更多的想法。
最后还是要说一句:这些「术」是辅助用的,重要的还是「道」:即你自己的记录、想法、积累——这些才是核心。
多写,多思考。
附注
翻看 PKMer 社区文章的时候,发现 Dataview实战-通过Dataview列出关键字所在的行和行数 里的代码和思路可以算作是这套方案的基础原型,我最早用的脚本应该也是源自这里。
这篇文章是站在巨人肩膀上做出的一些调整,这里也总结一下创新点(怎么像是水论文啊笑死🤣):
- 使用
dv.current()直接获取当前笔记,而非app.vault.getMarkdownFiles()获取所有笔记之后通过路径进行过滤,感觉会省一些性能(大概?) - 将
term单独拆分成内联属性,编辑上更舒适和美观 - 使用
dv.view()调用独立脚本,可以全局多次复用,并且保持样式和处理逻辑的的一致性 - 增加了对提取文本的一些处理,避免出现列表嵌套的情况
- 增加了跳转的链接,可以快速跳转到对应文本的位置
- 加了一些有的没的参数,用于定制查询结果的显示
以上!
这里是 Moy,希望能分享更多 OB 的有趣有用的技巧。
讨论
若阁下有独到的见解或新颖的想法,诚邀您在文章下方留言,与大家共同探讨。

