
Obsidian 达人成长之路 2:使用终极工具 Dataview 释放笔记库的潜力 · JavaScript API
前言
上一篇 Obsidian达人成长之路_1-使用终极工具Dataview 释放笔记库的潜力-DQL查询语言 讲了 Dataview 的基础查询语法。
本文为【Obsidian 达人成长之路】系列第 2 篇,主要讲解 Dataview 插件的 JavaScript API 调用方式的详尽用法,努力让每一个读者有所收获并应用到自己的 Obsidian 知识管理库中。
由于作者写作水平有限,在表达上正在努力提高自已的写作水平,以期望帮助更多的人了解 Obsidian 的主流插件来丰富自己的笔记功能,实现更多的想法。
提前高能预警
由于文章内容较长,涉及到代码,所以建议读者在电脑上阅读以获得更佳的体验。这样更方便复制示例内容在自己的 Obsidian 仓库中运行以加深理解和消化内容。
Dataview 提供的 DQL 查询语言为不同背景和需求的用户带来了便利,特别是对于那些不擅长或不愿意深入学习复杂编程语言的用户降低了使用门槛,让其数据查询和管理更多直观和易于上手。
然而,用户的群体是多种多样的,不同的用户对体验的要求是不尽相同的。这种多样性体现在对编辑器或工具的选择上,还体现在对数据查询和管理的个性化需求上。就拿代码编辑器来举例,有些用户倾向于使用功能丰富、界面友好的集成开发环境(IDE);有的用户则更喜欢轻便、快捷的文本编辑器;还有一部分极客喜欢 DIY 神器 Vim。
在这方面,Dataview 的优势在于其灵活性和可扩展性。与其说 Dataview 提供了 2 种方式来满足不同用户的需求,不如说它为用户提供了一个开放平台,让用户可以根据自己的喜欢和需求来定制和优化自己的查询结果。
快速入门
在编程的世界中,有一个广泛接受的传统,那就是使用“Hello World”作为学习新编程语言时的第一个示例程序,本文也不例外。
显示 Hello World
任意新建一个文档将下面的内容复制粘贴并运行。
greet:: Hello World!
- [ ] `= this.greet`
```dataviewjs
const page = dv.current()
const inlineGreet = page["greet"]
console.log(inlineGreet)
dv.header(2, inlineGreet)
dv.list([inlineGreet])
dv.el("span", `- [ ] ${inlineGreet}`)
dv.taskList(page.file.tasks)
dv.table(["问候"], [[inlineGreet]])
```结果:
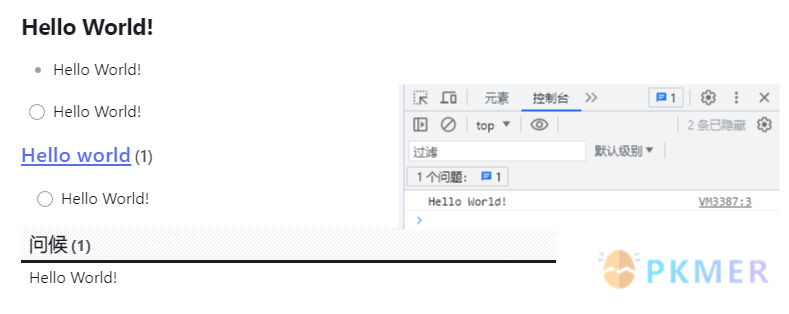
下面我们来分析一下上述示例:
首先,我们在文档中创建了一个内联属性 greet,然后创建了一个任务并通过内联 DQL 查询出 greet 属性并作为任务的名称。
接下来,我们通过调用 dv.current() 函数获取脚本当前正在执行的页面的页面信息,这相当于调用 dv.page("当前文档名") 函数。然后赋值给常量 page,紧接着读取了页面中的内联属性 greet 并赋值给常量 inlineGreet。
第一个输出使用浏览器的控制台作为载体,通过调用 JavaScript 的 console.log() 函数来实现。如果你不知道怎么显示开发者工具,1)在 Windows 或 Linux 下可以使用快捷键 Ctrl+Shift+I;2)macOS 请使用Cmd+Opt+I。
接下来我们分别使用了 div.header(2, inlineGreet) 函数来将问候输出为二级标题;使用 dv.list([inlineGreet]) 将其输出为列表元素;使用 dv.el("span", ...) 函数来将其输出为任务(这里只是为了演示,通常我们是从文档中获取任务);使用 dv.taskList(page.file.tasks) 函数将页面中的任务查询出来;最后使用 dv.table(["问候"], [[inlineGreet]]) 函数将其输出为表格显示。
读取属性
在 Obsidian 中我们可以在 Fronat matter 中定义 YAML 属性,也可以使用 Dataview 提供的内联属性在文体任意有效的位置定义属性。
下面是一段包含了各种属性的文档内容片段,我们将基于此进行讲解。
---
---
description: 测试描述
tags:
- 标签1
- 标签2
---
inlineProp1:: 测试
inline_test:: 下划线命名测试
InlineTest2:: 大写字母开头命名测试
Test Long Split Words:: 不规则变量名测试
**Bold Text**:: 加粗文本测试
这是内联字段 [inlineProp2:: 在文本内部]
我的名称不可见 (inlineProp3:: 我的变量名不可见)
- 在列表中定义标签 #标签3 和内联变量 [inlineProp4:: 在列表内]
- [ ] 在任务中定义标签 #标签4 和内联变量 [inlineProp5:: 在任务内]
外链:[[2022-01-06]]我们使用 dv.current() 获取当前页面的数据,然后使用 Object.keys() 方法来遍历所有属性。
```dataviewjs
Object.keys(dv.current()).forEach(key => {
console.log(key);
})
```Tip
dv.current()为dv.page("文档路径")的便捷方法。
结果:
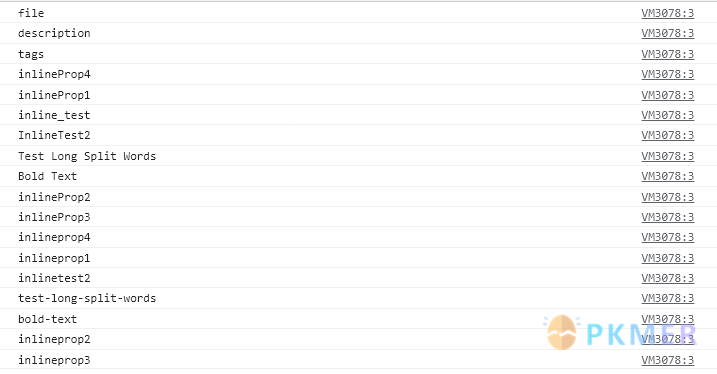
我们在命名变量时分别使用了驼峰式命名法、帕斯卡命名法、下划线命令法以及带有空格的属性名。从结果来看当前页面中定义的属性都在了,而且输出的数量远比我们定义的多,这是因为对于不规则的属性名,Dataview 内部进行了规范化。在 JavaScript 中属性通常以 对象.属性名 的方式来读取,同时也可以使用 对象['属性名'] 的方式,后者在通常用于动态计算属性名和特殊属性名读取。
```dataviewjs
const page = dv.current()
console.log(page['test-long-split-words']) // 不规则变量名测试
console.log(page['Test Long Split Words']) // 不规则变量名测试
console.log(page.inline_test) // 下划线命名测试
console.log(page.InlineTest2) // 大写字母开头命名测试
console.log(page.inlineprop1) // 测试
```以 Hello World 字符串为属性变量名举例,建议使用 hello-world,其次是 helloWorld / HelloWorld / hello_world 这三者可自行选用,在不同的编程语言环境都有其适用的场景。
为什么选择以 hello-world 的方式一方面是 YAML 中定义属性支持,然后 DQL 内联查询支持(= hello-world), 再一个很重要的原因这是官方内部默认使用(比如将带空格的属性转化后的结果)。虽然方便了 DQL 的读取,但是使用 API 读取时,我们需要额外多输入中括号和引号(dv.current()['hello-world']),这种成本通常可以忽略不计。
我们在前面通过遍历 dv.current() 在控制台显示所有属性,接下来我们看一下如何获取指定区域的属性。
YAML 中的属性读取
在 Obsidian 中 tags,cssclasses 和 aliases 是内置的默认属性,如果要获取自定义或者第三方插件提供的属性,则需要提前知识有哪些属性名,因为所有属性全挂在了 dv.current() 返回的对象中。要获取 YAML 中的属性我们需要使用 file.frontmatter 属性:
```dataviewjs
console.log(dv.current().file.frontmatter) // {description: '测试描述', tags: Array(2), hello-world: '你好呀'}
```列表和任务中的属性读取
Dataview 将任务作为一种特殊的列表来处理,可以使用 page.file.lists 来获取当前页面中的列表数据,使用 page.file.tasks 来获取任务数据。在获取的列表数据同时包含了所有的任务,可通过基属性 task 是否为 true 来判断当前列表是否为任务项。
在列表中定义的属性会挂载在当前列表对象下,而标签则位于 tags 属性中,下面我们分别读取列表和任务中的标签和属性。
```dataviewjs
const lists = dv.current().file.lists;
const tasks = dv.current().file.tasks;
lists.forEach(list => {
if (list.task) {
console.log(list.tags) // ['#标签4']
console.log(list.inlineProp5) // 在任务内
} else {
console.log(list.tags) // ['#标签3']
console.log(list.inlineProp4) %% 在列表内 %%
}
})
tasks.forEach(task => {
console.log(task.tags) %% ['#标签4'] %%
console.log(task.inlineProp5) %% 在任务内 %%
})
```外链文档中的属性获取
在示例中我们使用外部链接引用了一篇笔记的地址,现在我们通过遍历 page.file.outlinks 属性来获取外链的元数据,然后将其 path 属性传入 dv.page() 中来获取页面的所有信息,接着使用 file.tags 来读取标签值。
```dataviewjs
const links = dv.current().file.outlinks
links.forEach(link => {
console.log(dv.page(link.path).file.tags.array()) // ['#daily', '#journal']
})
```查询数据输出
在 DQL 中我们可以将查询的结果以表格、任务和日历的方式渲染到当前查询脚本所在的代码块位置。在 JavaScript 中没有对应的日历视图 API,只有 dv.list() 方法对应 LIST 语句,dv.taskList() 方法对应 TASK 语句以及 dv.table() 方法对应 TABLE 语句。虽然没有提供日历输出的方法,但是我们可以 API 中执行 DQL 查询语句变相实现。
dv.list(element, text) 方法
用于将结果渲染成列表,可接收 JavaScript 数组及 DataArray 类型。
```dataviewjs
const vanillaArray = [1, 2, [3, 4, 5, [6]]]
const dvArray = dv.array(vanillaArray)
dv.list(dvArray)
// dv.list(vanillaArray)
```结果:
dv.taskList(tasks, groupByFile) 方法
用于将结果渲染成任务列表,数据源必须从 page.file.tasks 中获取,默认情况下如果数据从多个文档中获取,则会按文档名进行分组,当然也可以将第二个参数指定为 false 来禁用分组。
下面根据 #daily 标签查询任务来展示 groupByFile 参数的作用,查询语句为:dv.taskList(dv.pages("#daily").file.tasks), 结果如下:
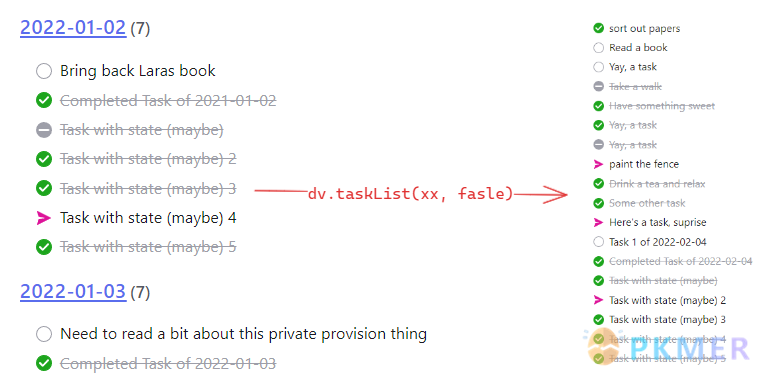
从结果来看,在指定了第 2 个参数为 false 后,任务的顺序发生了变化,右则的截图中的任务可能来自于多个页面中。
dv.table(headers, elements) 方法
用于将结果渲染成表格数据,headers 为一个数组,表示表头名称,而 elements 为表格数据,其值为数组,数组的每一项值同样为数组,用于表示表格的行数据。
```dataviewjs
const headers = ["姓名", "年龄", "性别", "爱好"]
const data = [
["张三", 20, "男", "打篮球"],
["李四", 25, "女", "踢足球"],
["王五", 30, "男", "游泳"]
]
dv.table(headers, dv.array(data))
```结果:

下面我们通过查询书籍数据来演示实际使用:
```dataviewjs
dv.table(["File", "Author", "Book topics", "Genres", "Total pages", "Cover image"], dv.pages('"10 Example Data/books"')
.sort( b => b.totalPages)
.map(b => [b.file.link, b.author, b.booktopics, b.genres, b.totalPages, b['Cover-Img']]))
```结果:
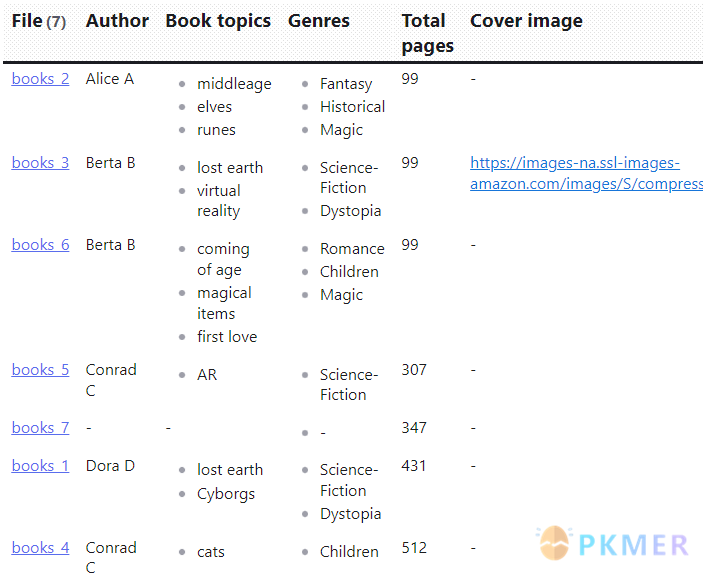
注意:虽然我们查询出来了图片的地址,但是并没有在表格中渲染出来,这个会留在系列文章中的案例篇进行讲解。
以日历输出
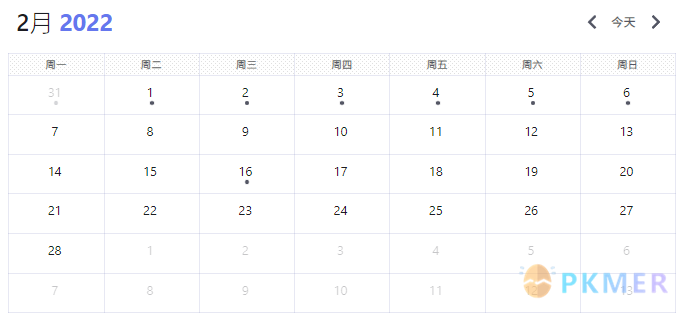
Dataview 并没有提供 dv.calendar() 方法来将查询的数据渲染为日历显示,但是我们可以通过 dv.execute(source) 来执行 DQL 查询,实现在 API 中渲染日历的功能。
```dataviewjs
const query = `
CALENDAR file.day
FROM "10 Example Data/dailys"
`
dv.execute(query)
```结果:
HTML 渲染
我们使用的表格、任务和列表在 Obsidian 中实际上都是最终用特定的 HTML 标签元素表示的,比如说表格为 <table></table> 标签,列表分为有符号列表 <ol></ol>,无符号列表 <ul></ul>,定义列表 <dl></dl>,像日历这种比较复杂的组件则是由多个 <div></div> 等元素嵌套而成的。
我们在 Obsidian 页面编辑时可以输入标题(1-6 号),正文内容,插入图片、代码等,这都可以使用 API 来动态设置。
dv.header(level, text)用于渲染标题,其中level取值为1-6。dv.paragraph(text)用于渲染段落,即<p></p>标签。dv.span(text)用于渲染行内元素,即<span></span>标签。dv.el(element, text)用于渲染指定的<element></element>标签内容。
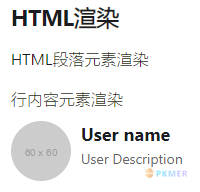
```dataviewjs
dv.header(2, "HTML渲染")
dv.paragraph("HTML段落元素渲染")
dv.span("行内容元素渲染")
const html = `
<div style="display: flex; align-items: flex-start;margin: 10px 0;">
<div width="60" height="60">
<img src="https://via.placeholder.com/60" style="border-radius:50%;" alt="Avatar">
</div>
<div style="margin-left: 10px;">
<div style="font-size: 18px; font-weight: bold;">User name</div>
<div style="font-size: 14px; color: #666;">User Description</div>
</div>
</div>
`
dv.el("div", html)
```结果:
Markdown 原始内容输出
在 Obsidian 中我们可以通过标题栏右则的【更多选项】-> 【源码模式】来切换至 Markdown 原始内容视图。我们可以将任何 Markdown 文本内容渲染到页面中。
```dataviewjs
const raw = `
## 2号标题
这是文本内容。
- 列表
- [x] 任务
**文字加粗**
双链:[[2022-08-03]]
## 表格
| 姓名 | 年龄 | 性别 | 爱好 |
| -- | -- | -- | --- |
| 张三 | 20 | 男 | 打篮球 |
| 李四 | 25 | 女 | 踢足球 |
| 王五 | 30 | 男 | 游泳 |
`
dv.paragraph(raw)
```结果:
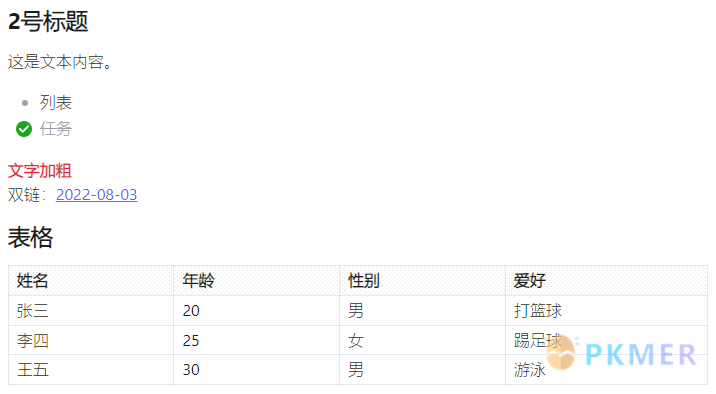
上面我们是手动提供的 Markdown 原始数据进行演示的,如果我们相要获取查询页面中的列表、任务或者表格的原始数据,该如何作呢?Dataview 已经为我们准备好了开箱即用的方法:
dv.markdownTable(headers, values)将结果输出为原始的 Markdown 表格表示形式,参数同dv.table()。dv.markdownList(values)将结果输出为原始的 Markdown 列表形式,即:- xxx。dv.markdownTaskList(tasks)将结果输出为原始的 Markdown 任务形式,即:- [ ] xxx或者- [x] xxxx。
将上述输出的 Markdown 原始数据使用 dv.paragraph() 挂载即可在页面中显示,当然也可以使用 dv.el() 选择其它的标签来作为容器。
解析 DQL 查询语句
DQL(数据查询语言)为普通用户提供了一种便捷的查询方式,使用户无需编写复杂的代码即可满足大部分数据管理需求。这种方式不仅简化了操作过程,还提高了使用效率和友好性。
在有些场景下我们使用 DQL 查询语句会更加高效,可以将其结合在代码中发挥特定的作用。当然,也有些场景下我们必须用到,如前面提到的日历渲染。Dataview 为我们提供了以下几个方法来解析 DQL 查询语句或者 DataviewJS 语句。
dv.execute(source)执行任意数据视图查询并将视图嵌入到当前页面中。dv.executeJs(source)执行任意 DataviewJS 查询并将视图嵌入到当前页面中。
使用方式:
```dataviewjs
dv.executeJs("dv.list([1, 2, 3, 4])") // 相当于 dv.list([1, 2, 3, 4])
dv.execute("TASK FROM #daily")
```DataArray 接口介绍
DataArray 接口是 Dataview 提供的列表数据操作的抽象,它是对 JavaScript 数组操作的扩展和基于 Dataview 环境的本地化。我们可过 dv.array() 将一个普通的数组转换成 DataArray 类型,也可以反向操作将其转换成普通的 JavaScript 数组,比如:dv.list(dv.current()).array()。
下面是官方提供的 DataArray 接口定义,为了简少行数,删除了所有注释:
export type ArrayFunc<T, O> = (elem: T, index: number, arr: T[]) => O;
export type ArrayComparator<T> = (a: T, b: T) => number;
export interface DataArray<T> {
length: number;
where(predicate: ArrayFunc<T, boolean>): DataArray<T>;
filter(predicate: ArrayFunc<T, boolean>): DataArray<T>;
map<U>(f: ArrayFunc<T, U>): DataArray<U>;
flatMap<U>(f: ArrayFunc<T, U[]>): DataArray<U>;
mutate(f: ArrayFunc<T, any>): DataArray<any>;
limit(count: number): DataArray<T>;
slice(start?: number, end?: number): DataArray<T>;
concat(other: Iterable<T>): DataArray<T>;
indexOf(element: T, fromIndex?: number): number;
find(pred: ArrayFunc<T, boolean>): T | undefined;
findIndex(pred: ArrayFunc<T, boolean>, fromIndex?: number): number;
includes(element: T): boolean;
join(sep?: string): string;
sort<U>(key: ArrayFunc<T, U>, direction?: "asc" | "desc", comparator?: ArrayComparator<U>): DataArray<T>;
groupBy<U>(key: ArrayFunc<T, U>, comparator?: ArrayComparator<U>): DataArray<{ key: U; rows: DataArray<T> }>;
distinct<U>(key?: ArrayFunc<T, U>, comparator?: ArrayComparator<U>): DataArray<T>;
every(f: ArrayFunc<T, boolean>): boolean;
some(f: ArrayFunc<T, boolean>): boolean;
none(f: ArrayFunc<T, boolean>): boolean;
first(): T;
last(): T;
to(key: string): DataArray<any>;
expand(key: string): DataArray<any>;
forEach(f: ArrayFunc<T, void>): void;
array(): T[];
[Symbol.iterator](): Iterator<T>;
[index: number]: any;
[field: string]: any;
}接下来我们将分类介绍接口中的属性和方法的用法。
数据读取
一个数组通过索引来获取其对应的数据项的值是一个很常规的操作。这里我们有一个数组 arr,就可以通过 arr[0] 和 arr[arr.length - 1] 来分别读取第一项和最后一项的值,这对应 DataArray 中的 first() 和 last() 方法。如果数组项是一个对象值,想要获取读取对象中某个字段的值,就需要使用遍历方法,比如 for 语句,或者数组的 forEach() 方法,为了方便操作,DataArray 接口直接提供了一个通过属性来获取数组中对象值的方法 to(),也可以在 DataArray 实例中直接访问这个属性名。
```dataviewjs
const arr = [1, 2, 3]
const arr2 = [{name: 'jenemy', age: 34}, {name: 'xiaolu', age: 33}, {name: 'lulu', age: 25 }]
const dvArr = dv.array(arr)
const dvObjArr = dv.array(arr2)
console.log(dvArr.length) // 3
console.log(dvArr.first(), dvArr.last()) // 1 3
console.log(dvArr[0], dvArr[dvArr.length - 1]) // 1 3
console.log(dvObjArr.name.array()) // ['jenemy', 'xiaolu', 'lulu']
console.log(dvObjArr['name'].array()) // ['jenemy', 'xiaolu', 'lulu']
console.log(dvObjArr.to('name').array()) // ['jenemy', 'xiaolu', 'lulu']
console.log(dvObjArr[0]) // {name: 'jenemy', age: 34}
// 通过遍历获取属性值
for (p of dvObjArr) {
console.log(p.name) // jenemy, xiaolu, lulu
}
// 使用 `.forEach()` 遍历
dvObjArr.forEach(p => console.log(p.name)) // jenemy, xiaolu, lulu
```数据遍历
数据遍历除了使用 for 和 for of 语句外,DataArray 接口中还定义了很多遍历方法,有的是 JavaScript 中相同的,有的是 Dataview 特有的。
forEach() 方法
方法签名为:forEach(f: ArrayFunc<T, void>): void,对数组的每一项执行指定的函数。
```dataviewjs
dv.array([1, 2, 3, 4, 5]).forEach(n => dv.span(n)) // 页面显示:12345
```map() 方法
方法签名为:map<U>(f: ArrayFunc<T, U>): DataArray<U>,对数组中的每一项执行指定的函数,并返回一个值。
```dataviewjs
dv.list(dv.array([1, 2, 3, 4, 5]).map(x => x * 2)) // 渲染列表:2, 4, 6, 8, 10
dv.list(dv.array([1, 2, 3, 4, 5]).map(x => x % 2 === 0)) // 渲染列表:false, true, false, true, false
```mutate() 方法
方法签名为:mutate(f: ArrayFunc<T, any>): DataArray<any>,这个方法实际上是对 map() 遍历对象数组操作的一种特定场景下的简化操作。
下面我们一步步来追本溯源,解读其适用的场景。
我们知道使用 map() 方法可以对普通数组(如:[1, 2, 3, 4]),执行遍历操作如:x => x * 2 或者 x => x % 2 === 0 来返回布尔值,但是我们无法使用 mutate() 来实现同样的功能。
接下来我们看一下对象数组(如:const arr = [{a: 1, b: 2}, {a: 3, b: 4}, {a: 5, b: 6}]),使用 map() 方法我们可以执行操作 x => x.a + x.b,但是同样在 mutate() 方法中无法使用。接下来通过 map() 方法为对象添加一个属性 c,代码为:x => {x.c = x.a + x.b; return x},然后我们这次发现可以使用 mutate() 发挥作用了:arr.mutate(x => x.c = x.a + x.b),进一步我们尝试:arr.mutate(x => delete x.b) 以及 arr.mutate(x => x.b = x.a + x.b)。
总结:mutate() 方法适用于修改遍历项(仅对象)的值,如添加属性、删除属性以及修改属性值操作。它是在不改变遍历项数据类型情况下,map() 方法的一种简化操作。
下面我们看一下在实际操作中的运用。
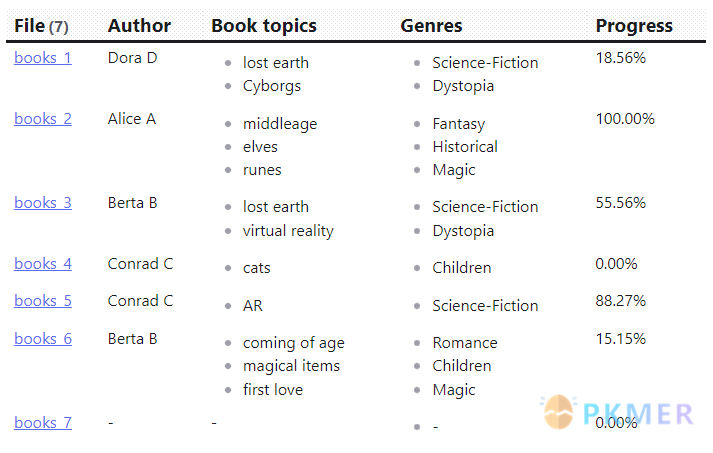
```dataviewjs
dv.table(["File", "Author", "Book topics", "Genres", "Progress"], dv.pages('"10 Example Data/books"')
.mutate(b => b.percent = (b.pagesRead / b.totalPages * 100).toFixed(2) + "%")
.map(b => [b.file.link, b.author, b.booktopics, b.genres, b.percent]))
```结果:
flatMap() 方法
方法签名为:flatMap<U>(f: ArrayFunc<T, U[]>): DataArray<U>,通过对数据数组中的元素应用函数来映射每个元素,然后展平结果以生成新数组。
这是一个很重要的方法,应用得当在很多场景下能够简化操作,但是这个方法初次接触有点不好理解,下面我们来一一解读其用法。
首先我们将在 mutate() 方法讲解时我们使用的简单数组 [1, 2, 3, 4] 和 const arr = [{a: 1, b: 2}, {a: 3, b: 4}, {a: 5, b: 6}] 使用 flatMap() 方法进行同样操作:
```dataviewjs
const arr = dv.array([{a: 1, b: 2}, {a: 3, b: 4}, {a: 5, b: 6}])
dv.list(dv.array([1, 2, 3, 4]).flatMap(x => [x * 2])) // 页面显示 [2, 4, 6, 8]
dv.list(dv.array([1, 2, 3, 4]).flatMap(x => [x % 2 === 0])) // 页面显示 [false, true, false, true]
dv.list(arr.flatMap(x => [x.a + x.b])) // 页面显示 [3, 7, 11]
dv.list(arr.flatMap(x => {x.c = x.a + x.b; return [x]})) // 页面显示 [{a: 1, b: 2, c: 3}, {a: 3, b: 4, c: 7}, {a: 5, b: 6, c: 11}]
```从上面的示例可以看出,使用 flatMap() 方法改写 map() 方法只需要将结果套上一层数组。
读者可能会疑惑,就这还需要单独搞一个方法出来多此一举吗?其实不然,下面我们来揭示其真正发挥作用的地方。
在使用 map() 方法时不会改变数组的长度,这是一个共识。现在我想把数组 [1, 2, 3, 4] 变成 [1, 2, [3], 2, 3, [5], 3, 4, [7]],其中嵌套数组值为第 i 项加上 i + 1 项的值,其中 i 为数组索引。这个时候就无法使用 map() 来实现了,需要使用 for 语句或者 forEach() 方法来遍历数组,然后声明一个新的数组来存放结果:
```dataviewjs
const arr = dv.array([1, 2, 3, 4])
const result = []
for (let i = 0; i < arr.length; i++) {
if (i < arr.length - 1) {
result.push(arr[i], arr[i + 1], [arr[i] + arr[i + 1]])
}
}
console.log(result) // [1, 2, [3], 2, 3, [5], 3, 4, [7]]
```那么使用 flatMap() 实现如何呢?
很简单,只需要一行代码:arr.flatMap((x, i, arr) => i < arr.length - 1 && [arr[i], arr[i + 1], [arr[i] + arr[i + 1]]]).array()。
上面的示例我们使用 flatMap() 实现了数组增加元素的操作,接下来我们来看一下如何删除元素。
我们通常使用 filter() 方法来过滤数据,如 [1, 2, 3, 4].filter(x => x % 2 === 0) 来得到偶数组成的数组,而使用 flatMap() 删除不需要的数组项,只需要返回 [] 即可,如:[1, 2, 3, 4].flatMap(x => x % 2 === 0 ? [x] : [])。
最后,说一下 flatMap() 之所以叫这个名字,是因为它实际上是先执行了 map() 操作,然后再执行了深度为 1 的 flat() 操作。
```dataviewjs
const arr = [{a: 1, b: 2, c: [1, 2]}, {a: 3, b: 4, c: [3, 4]}, {a: 5, b: 6, c: [5, 6]}]
console.log(arr.map(x => x.c).flat()) // [1, 2, 3, 4, 5, 6]
console.log(arr.flatMap(x => x.c)) // [1, 2, 3, 4, 5, 6]
```数据查询与过滤
在 JavaScript 中数据数据查询通常使用 find()/findIndex()/findLastIndex(), includes() 和 indexOf()/lastIndexOf() 这几种方法,而过滤则使用 filter()。在 DataArray 中支持 find()/findIndex(), includes(),indexOf() 和 filter() 方法。
where() 方法
在 Dataview 中我们通常使用 where(predicate: ArrayFunc<T, boolean>): DataArray<T> 方法来过滤数据,同样也可以使用 filter() 方法,两者是一样的,只不过后者是 JavaScript 中数组的常用方法。
下面我们接着讲解 mutate() 方法时使用的书籍查询示例,加上一个条件判断:
```dataviewjs
dv.table(["File", "Author", "Book topics", "Genres", "Progress"], dv.pages('"10 Example Data/books"')
.where(b => b.author === "Dora D" && b.genres.includes("Dystopia"))
.mutate(b => b.percent = (b.pagesRead / b.totalPages * 100).toFixed(2) + "%")
.map(b => [b.file.link, b.author, b.booktopics, b.genres, b.percent]))
```结果:

Warning需要注意的是使用
where()方法查询数据时可能会修改原始数据。
下面以 filter() 方法来举例:
const arr = [1, 2, 3, 4, 5, 6]
const result = arr.filter((d, i, arr) => {
if (i < arr.length - 1) arr[i + 1] += 10
return d < 5
})
console.log(result, arr) // [1] (6) [1, 12, 13, 14, 15, 16]
const arr2 = [1, 2, 3, 4, 5, 6]
const result2 = arr2.filter((d, i, arr) => {
arr.push(3)
return d < 4
})
console.log(result2, arr2) // [1, 2, 3] (12) [1, 2, 3, 4, 5, 6, 3, 3, 3, 3, 3, 3]
const arr3 = [1, 2, 3, 4, 5, 6]
const result3 = arr3.filter((d, i, arr) => {
arr.pop()
return d < 5
})
console.log(result3, arr3) // [1, 2, 3] (3) [1, 2, 3]对 arr 的过滤中我们将当前遍历的数据项的下一项执行了加 10 操作,导致第 2 次执行时其值为 12,依次类推,最终只有第一次执行时满足过滤条件。
对 arr2 的过滤中我们每执行一次过滤函数就在数组的后面加上数字 3,观察结果并没有对扩充后的数据项进行遍历,因为这会进入一个死循环。
对 arr3 的过滤中我们每执行一次过滤函数就从数组尾部移出一个元素,这最终导致执行 3 次后已再元小于 5 的元素了,因为 4 已经移出数组了。
find() 和 findIndex() 方法
find(pred: ArrayFunc<T, boolean>): T | undefined 方法返回数组中满足提供的测试函数的第一个元素的值,否者返回 undefined。如果需要查询某个值的索引,则使用 findIndex(pred: ArrayFunc<T, boolean>, fromIndex?: number): number 方法。
下面我们通过这两个方法来找出 6:00-6:30 第一次早起的日期和在日记中记录的索引位置,需要注意的是由于第一篇日记没有相关数据,所以这里的 index 结果为 2。
```dataviewjs
const dt = dv.luxon.DateTime
const link = dv.pages('"10 Example Data/dailys"').find(p => {
const wakeUpTime = p['wake-up'] && dt.fromFormat(p['wake-up'], 'HH:mm').startOf('minute')
const start = dt.fromObject({ hour: 6, minute: 0 }).startOf('minute')
const end = dt.fromObject({ hour: 6, minute: 30 }).startOf('minute')
return wakeUpTime > start && wakeUpTime < end
}).file.link
const index = dv.pages('"10 Example Data/dailys"').findIndex(p => {
const wakeUpTime = p['wake-up'] && dt.fromFormat(p['wake-up'], 'HH:mm').startOf('minute')
const start = dt.fromObject({ hour: 6, minute: 0 }).startOf('minute')
const end = dt.fromObject({ hour: 6, minute: 30 }).startOf('minute')
return wakeUpTime > start && wakeUpTime < end
})
dv.span(`第 ${index + 1} 天(${link})开始 6:00-6:30 早起`)
```结果:

includes() 方法
includes(element: T): boolean 方法用于判断数组中是否包含某个数据项。
对于数组 [1, 2, 3] 我们可以使用 dv.array([1, 2, 3]).includes(2) 来判断 2 是否在数组中。下面是一个判断页面是否在日记目录中的示例:
```dataviewjs
console.log(dv.pages('"10 Example Data/dailys"').includes(dv.page("2022-01-12"))) // true
console.log(dv.pages('"10 Example Data/dailys"').includes(dv.page("2023-01-12"))) // false
```indexOf() 方法
indexOf(element: T, fromIndex?: number): number 方法返回数组中第 fromIndex 次出现给定元素的下标,如果不存在则返回 -1。这个方法的使用场景目前作者能想的是多个同名文件(如未命名的)的查找,不过这里不打算这个作为示例,而是以普通的数字数组更方便直白。
```dataviewjs
const data = dv.array([1, 2, 3, 2, 45, 23, 2, 32, 43242, 5435, 2, 23])
console.log(data.indexOf(2)) // 1
console.log(data.indexOf(2, data.length - 1)) // -1
console.log(data.indexOf(2, 4)) // 6
```测试判断
在 JavaScript 中可以通过数组的 every() 方法测试一个数组内的所有元素是否都能通过指定函数的测试,使用 some() 方法测试数组中是否至少有一个元素通过了由提供的函数实现的测试。如果在数组中找到一个元素使得提供的函数返回 true,则返回 true;否则返回 false。而 DataArray 同样也提供了这两个方法,同时还提供了一个和 every() 相反的 none() 方法。
```dataviewjs
const data = dv.array([11, 20, 23, 43, 123, 13, 55])
console.log(data.every(item => item > 10)) // true
console.log(data.none(item => item > 10)) // false
console.log(data.some(item => item > 100)) // true
```分组与展开操作
在 DQL 查询语句中我们使用 GROUP BY 来将数据按指定的字段进行分组,而使用 FLATTEN 来对查询结果进行展开。但是在使用 API 时我们需要自己来解析分组后的数据,可自定义渲染,虽然很灵活,但是也增加了成本。
DataArray 接口提供了 groupBy() 方法来对数据进行分组,expan() 方法来展开数据。
groupBy() 方法
方法的签名为: groupBy<U>(key: ArrayFunc<T, U>, comparator?: ArrayComparator<U>): DataArray<{ key: U; rows: DataArray<T> }>,第一个参数为一个函数,一般返回字段名称,后续会介绍其它用法。第二个参数为一个比较函数,默认情况下按升序排序。
groupBy() 方法调用后返回一个结果数组,数组项为一个对象,其中 key 属性表示分组的名称,rows 表示分组的数据。
为了方便理解,接下来我们将采用 DQL 和 API 对比的方式来举例。
示例一:一对多分组
下面我们来查询书籍并按作者进行分组。这个示例中一个作者对应多本书籍,因此我们需要将分组后的数据 rows 进行展开。
```dataview
TABLE rows.file.link AS 书籍
FROM "10 Example Data/books"
GROUP BY author AS 作者
```
```dataviewjs
dv.table(['作者', '书籍'], dv.pages('"10 Example Data/books"')
.groupBy((p) => p['author'])
.flatMap(p => {
const result = []
if (p.rows.length > 1) {
p.rows.forEach((r, i) => {
if (i > 0) {
result.push(['', r])
} else {
result.push([p.key, r])
}
})
} else {
result.push([p.key, p.rows.first()])
}
return result
})
.map(r => {
return [r[0], r[1].file.link]
}))
```结果:

示例二:多对多分组
同样是查询书籍信息,这次我们查询书籍的分类信息。这是一个多对多的关系,一本书可以归为多种类型,而一个类型也可以包含多本书籍。
在使用 DQL 查询语言时,需要注意一点,我们使用了 FLATTEN 语句来展开分类,让每一个分类对应一本书籍,不然就会显示成多个分类对应一本书籍,这显然不符合结果。
在使用 API 处理这种多对多分组时,我们就需要分别对 key 和 rows 进行遍历展开才能得到和 DQL 查询类似的结果。
```dataview
TABLE rows.file.link AS 书籍
FROM "10 Example Data/books"
FLATTEN genres
GROUP BY genres AS 类别
```
```dataviewjs
dv.table(['类别', '书籍'], dv.pages('"10 Example Data/books"')
.groupBy((p) => p['genres'])
.flatMap(p => {
const result = []
if (p.rows.length > 1) {
p.rows.forEach((r, i) => {
if (i > 0) {
if (Array.isArray(p.key)) {
p.key.flatMap(k => {
result.push([k, r])
})
} else {
result.push([p.key, r])
}
} else {
if (Array.isArray(p.key)) {
p.key.flatMap(k => {
result.push([k, r])
})
} else {
result.push([p.key, r])
}
}
})
} else {
if (Array.isArray(p.key)) {
p.key.flatMap(k => {
result.push([k, p.rows.first()])
})
} else {
result.push([p.key, p.rows.first()])
}
}
return result
})
.sort(p => p[1].file.name)
.sort(p => p[0])
.flatMap((r, i, arr) => {
if (!r) return []
const result = []
const key = r[0]
for (j = i; j < arr.length; j++) {
if (i === j) {
let exist = false
// 如果已经存在就不再添加
for (let k = j - 1; k > 0; k--) {
if (key === arr[k][0]) {
exist = true
break
}
}
if (!exist) {
result.push(r)
} else {
result.push(['', arr[j][1]])
}
} else {
if (arr[j][0] === key) {
result.push(['', arr[j][1]])
arr.splice(j, 1)
}
}
}
return result
})
.map(r => {
return [r[0], r[1].file.link]
}))
```结果:

上述代码虽然我们实现了类似的结果,但是观察结果会发现我们丢失了分组信息:原数据有 8 个分组,我们的结果为 13 个分组。代码中,通过两个 sort() 方法分别按分组分类名和文件名进行了排序;通过两个 flatMap() 方法分别处理了文档名称的展开和分类同名的空白显示。
示例三:根据计算结果分组
下面这个示例我们不返回字段名,而是返回一个根据条件判断自定义的名称。
```dataview
LIST rows.file.link
FROM "10 Example Data/assignments"
GROUP BY choice(due < date("2022-05-12"), "已过期", "还有机会")
```
```dataviewjs
dv.list(dv.pages('"10 Example Data/assignments"')
.groupBy(p => {
if (p.due < dv.date("2022-05-12")) {
return "已过期"
}
return "还有机会"
})
.flatMap(g => {
return [g.key, g.rows.map(r => r.file.link)]
}))
```结果:

从结果来看还是有细微差别的,左边分组名和数据是放置在一个 <li> 标签中,而右边则是将分组名和数据单独放置在一个 <li> 标签中。
expand() 方法
expand(key: string): DataArray<any> 方法的作用不同于 FLATTEN 语句,它可以用于列表和任务的展开,需要指定 key 为 children 或者 subtasks,但是结果不能保证是按原来的顺序输出。
这个方法在 Dataview Example Valut 示例库也没有找到相应的示例,说明其适用范围很小,很冷门。作者本以为能够实现将嵌套的任务展开,然而却…
- [ ] 1
- [ ] 2
- [ ] 3
- [ ] 4
- [ ] 5
- [ ] 6
```dataviewjs
dv.list(dv.current().file.tasks.expand('subtasks').map(t => t.text))
dv.taskList(dv.current().file.tasks.expand('subtasks'))
```结果:

其它方法
由于篇幅有限就不一一讲解所有的方法了。sort() 方法有在前面的示例中应用到,剩下的都比较简单,直接上示例:
```dataviewjs
const arr = dv.array([1, 2, 3, 4, 2, 1, 23, 12])
console.log(arr.distinct().array()) // [1, 2, 3, 4, 12, 23]
console.log(arr.join('#')) // 1#2#3#4#2#1#23#12
console.log(arr.limit(2).array()) // [1, 2]
console.log(arr.slice(0, 3).array()) // [1, 2, 3]
console.log(arr.concat(dv.array([5, 6, 7, 8])).array()) // [1, 2, 3, 4, 2, 1, 23, 12, 5, 6, 7, 8]
```进阶用法
现在开始我们来介绍在入门中没有提及到的方法,这些知识点会让你应对复杂的需求时更加游刃有余,有更多的思路。
更多页面获取方式
在前面的示例中我们使用 dv.current() 来获取代码所在当前页面,使用 dv.page(path) 来获取单个文档页面,使用 dv.pages(source) 来获取指定目录的文档。现在我们来进一步了解 dv.pages() 的其它用法。
```dataviewjs
dv.list(dv.pages().limit(5).map(p => p.file.link)) // 获取所有页面,返回前5个链接
dv.list(dv.pages('#daily').limit(5).map(p => p.file.link)) // 获取所有带有daily标签的页面,返回前5个链接
dv.list(dv.pages('#daily or #clientC').map(p => p.file.link)) // 获取所有带有daily或clientC标签的页面,返回链接列表
dv.list(dv.pages('"10 Example Data/books" and -(#daily and #journal)').map(p => p.file.link)) // 获取目录名为"10 Example Data/books"且不带有daily和journal标签的页面,返回链接列表
dv.list(dv.pages('"10 Example Data/books" or #clientC').map(p => p.file.link)) // 获取目录名为"10 Example Data/books"或带有clientC标签的页面,返回链接列表
```需要注意的是目录名必需加上双引号然后再放在单引号内。
如果只相要获取文档的完整路径,可以直接使用 dv.pagePaths(source) 方法,如将所有路径以列表显示:dv.list(dv.pagePaths('#daily'))。
结果:
插入链接
作者有在这个系列的教程中的 DQL 查询语言篇中详细介绍了内部和外部链接以及双链的概念,现在我们来看一下在 API 中如何操作链接。
在 Obsidian 中使用链接来唯一描述一个文档、标题和块。在 Dataview 中定义了 Link 类来描述链接,它有以下属性:
path: string表示链接指向的文件路径。display?: string链接的显示名称,为可选字段。subpath?: string如果存在的话就指向文件内部的标题或者块 ID。embed: boolean是否为嵌入的链接。type: "file" | "header" | "block"链接的类型,会影响到subpath的结果。
获取链接元数据
在 DQL 查询语言中我们使用 meta() 函数来获取链接的元数据信息,而在 API 中则将其拆分成 3 个独立的函数,分别对应其 type 的 3 种类型。
dv.fileLink(path, [embed?], [display-name])对应类型为file,用于链接文件。dv.sectionLink(path, section, [embed?], [display?]对应类型header,用于链接文档中的标题。dv.blockLink(path, blockId, [embed?], [display?]对应类型block,用于链接文档中的段落。
```dataviewjs
console.log(dv.fileLink("2022-02-04")) // Link {path: '2022-02-04', display: undefined, subpath: undefined, embed: false, type: 'file'}
console.log(dv.fileLink("2022-02-04", true)) // Link {path: '2022-02-04', display: undefined, subpath: undefined, embed: true, type: 'file'}
console.log(dv.fileLink("2022-02-04", false, '显示名称')) // Link {path: '2022-02-04', display: '显示名称', subpath: undefined, embed: false, type: 'file'}
console.log(dv.sectionLink("2022-02-04", 'Metadata', false, '显示名称')) // Link {path: '2022-02-04', display: '显示名称', subpath: 'Metadata', embed: false, type: 'header'}
console.log(dv.blockLink("2022-02-04", '220763', true, '显示名称')) // Link {path: '2022-02-04', display: '显示名称', subpath: '220763', embed: true, type: 'block'}
```页面中显示链接
要在文档中显示我们通过 dv.fileLink() 等方法创建的链接,只需要使用在入门中提及的渲染 HTML 方法即可。
这里我们来使用 dv.span() 渲染来展示块引用的效果:
```dataviewjs
dv.span(dv.blockLink("2022-02-04", '220763', true, '显示名称'))
```结果:

Tip在 obsidian 中我们使用
[[]]来嵌入链接,如果所指向的文件不存在,在鼠标点击链接时会自动创建这个链接文件。如果相要将嵌入的链接的内容显示出来只需要在双括号前加一个感叹号,即![[]],这就等同于在代码中将embed设置为true,这个时候display指定的名称将会失效。
日期和时间操作
我们知道在 Obsidian 中的每一个文档都有一个 file 对象内部属性,其 cday / ctime 和 mday / mtime 分别表示文档的创建日期和时间以及修改日期和时间。
在创建日记类文档时,会自动以当前日期作为文件名。为此,在 file 对象中还提供了一个属性 day 来获取这个日期文件名(即返回日期值)。
在 API 中 Dataview 提供了 dv.date(text) 和 dv.duration(text) 来分别表示日期和时间以及持续时间。它们的返回值分别对应于底层的 dv.luxon.DateTime 和 dv.luxon.Duration 对象。关于 Luxon 日期和时间操作库我们会在文章中单独介绍其用法。
```dataviewjs
const now = new dv.luxon.DateTime(new Date())
const dur = dv.luxon.Duration
console.log(dv.date("2022-02-04").toFormat("yyyy-MM-dd")) // 2022-02-04
console.log(dv.date(dv.blockLink("2022-02-04", '220763', true, '显示名称')).toISODate()) // 2022-02-04
console.log(dv.date(now).toISOTime()) // 11:32:58.843+08:00
console.log(dv.date(now).offsetNameLong) // 中国标准时间
console.log(dv.duration('8h30m').toObject()) // {hours: 8, minutes: 30}
console.log(dv.duration('8h30m').toFormat("h'小时'm'分钟'")) // 8小时30分钟
console.log(dv.duration('8h30m').toHuman()) // 8小时、30分钟
console.log(dv.duration(dur.fromObject({hours: 8, minutes: 30})).toHuman()) // 8小时、30分钟
```查询评估
这里介绍的方法对于基于 Dataview API 进行二次开发的读者或许有帮助。使用这些方法我们可以对 Dataview 的查询结果进行评估:添加/删除值、改变文档路径、强制显示/不显示分组 ID 以及对查询过程中出现报错进行捕捉处理等。
dv.query() 和 dv.tryQuery() 方法
dv.query(source, [file, settings]) 执行 Dataview 查询并将结果作为结构化返回返回。这里的 source 为 DQL 查询语句,因此我们可以得到 4 种结构化的输出类型。
在 Dataview 源码中将查询结果声明为类型 QueryResult,这是一个联合类型,下面是相关的源码:
export type IdentifierMeaning = { type: "group"; name: string; on: IdentifierMeaning } | { type: "path" };
export type TableResult = { type: "table"; headers: string[]; values: Literal[][]; idMeaning: IdentifierMeaning };
export type ListResult = { type: "list"; values: Literal[]; primaryMeaning: IdentifierMeaning };
export type TaskResult = { type: "task"; values: Grouping<SListItem> };
export type CalendarResult = {
type: "calendar";
values: {
date: DateTime;
link: Link;
value?: Literal[];
}[];
};
export type QueryResult = TableResult | ListResult | TaskResult | CalendarResult;从上面的 TypeScript 类型声明来看,符合我们已知的 4 种查询类型 table | list | task 和 calendar,每一种类型都有其特殊的数据结构。
下面我们单独介绍每一种类型,但会在第一个 TableResult 类型中重点介绍相关的知识点,后面几种不再详细描述细节。同时,还会在第一个类型中介绍可选参数 file 和 settings 的作用。
TableResult 类型
我们使用前面提到过的书籍查询例子,并将结果使用输出为 JSON 格式。
```dataviewjs
const query = `
TABLE rows.file.link AS 书籍
FROM "10 Example Data/books"
GROUP BY author AS 作者
`
const queryResult = await dv.query(query)
console.log(JSON.stringify(queryResult))
```下面是控制台中输出的数据,我们将其中文件元数据使用 Link 来指代,这样有利于关注重要部分。
{
"value": {
"type": "table",
"values": [
[ null, [ Link ] ],
[ "Alice A", [ Link ] ],
[ "Berta B", [ Link, Link ] ],
[ "Conrad C", [ { Link }, { Link } ] ],
[ "Dora D", [ { Link } ] ]
],
"headers": [
"作者",
"书籍"
],
"idMeaning": {
"type": "group",
"name": "作者",
"on": {
"type": "path"
}
}
},
"successful": true
}我们现在来分析一下上面这个结果 JSON 数据:
successful 值为 true 意味着查询是成功的。如果我们提供的数据不存在但是查询语法是正确的,那么 successful 仍然为 true,只不过 value.values 结果为 []。另外一种情况就是查询语法不正确,这种情况下就会返回 false,并且会返回一个类似:Failure {error: 'Error: \n-- PARSING FAILED … \n', successful: false} 的信息。
如果去翻阅这部分的源码会发现上实际上 dv.query() 和 dv.tryQuery() 的区分在于返回结果,前者将结果使用 Success 和 Failure 类型包裹了一下,而后者没有。
value 属性中包含了查询结果数据的相关信息,其中 type 表明了结果类型为表格,values 为结果数据,headers 为表格的表头名称,idMeaning 为一个对象,其中 type 为 group 表明使用了分组,如果我们没有使用 GROUP BY 语句,这里将会是 path 值,同时也不会有 name 和 on 属性值。name 是在使用 GROUP UP 语句时指定 AS 名称,而 on 的值始终为 { type: "path" }。
分析完结果数据,现在我们来看一下可选参数 file 和 settings 的作用。
file 默认为当前代码所在文档的路径,格式为 xxx.md,我们可以通过传入自定义的路径来修改这个值。这个可选参数有什么用途呢?目前作者对 Obsidian 探索还不够深入,就留给读者去挖掘,这里在给出一个示例来演示其作用。
```dataviewjs
const query = `
TABLE WITHOUT ID file.link AS 替换后文件
WHERE file = this.file
`
const currentFile = dv.current().file
const queryResult = await dv.query(query, '实例候选.md')
queryResult.value.headers.push('原来的文件')
queryResult.value.values[0].push([currentFile.link])
dv.table(queryResult.value.headers, queryResult.value.values)
```结果:

Tip
dv.query()方法返回值签名为Promise<Result<QueryResult, string>>,因些我们需要使用await dv.query()来获取异步值,然后也可以使用dv.query().then(v => {//...})以 Promise API 方式来处理。
settings 可先参数是一个 QueryApiSettings 类型,目前只有一个配置属性 forceId: boolean,这个值将覆盖 WITHOUT ID 的设置。当值为 true 时会包含链接或者分组名字段,false 则排序。
修改上面介绍 file 参数的示例中的 dv.query() 为 dv.query(query, '实例候选.md', { forceId: true }),会得到一个显示文件链接的结果:

ListResult 类型
这里我们同样使用前面分组时的示例,来看一下解析后数据:
```dataviewjs
const query = `
LIST rows.file.link
FROM "10 Example Data/assignments"
GROUP BY choice(due < date("2022-05-12"), "已过期", "还有机会")
`
const queryResult = await dv.query(query)
console.log(JSON.stringify(queryResult))
```结果:
{
"value": {
"type": "list",
"values": [
{
"$widget": "dataview:list-pair",
"key": "还有机会",
"value": [ Link, Link, ... ]
},
{
"$widget": "dataview:list-pair",
"key": "已过期",
"value": [ Link, Link, ... ]
}
],
"primaryMeaning": {
"type": "group",
"name": "choice(due < date(\"2022-05-12\"), \"已过期\", \"还有机会\")",
"on": {
"type": "path"
}
}
},
"successful": true
}从结果数据来分析,会发现在 primaryMeaning.name 中,分组字段不是一个常规的属性名,而是一个条件判断语句。在结果中我们还发现有一个特殊的字段 $widget。如果试图将其删除,那么在使用 dv.list(queryResult.value.values) 时将会得到一个错误提示结果:- **<unknown widget ''>**,然后我们翻阅相关部分源码,会发现 ListResult 的查询结果数据为 ListPairWidget 类型,它实现了抽象类 Widget,而后者则定义了一个 $widget 属性,用于标识组件。
Dataview 目前定义了 2 种类型分别为 ListPairWidget ID 为 dataview:list-pair 和 ExternalLinkWidget ID 为 dataview:external-link。我们可以根据其定义来强制将 ListPairWidget 显示为 ExternalLinkWidget
。
下面是演示代码:
```dataviewjs
const query = `
LIST rows.file.link
FROM "10 Example Data/assignments"
GROUP BY choice(due < date("2022-05-12"), "已过期", "还有机会")
`
const queryResult = await dv.query(query)
queryResult.value.values.forEach(row => {
row.value = row.value.slice(0, 2)
row.display = row.key
row.$widget = 'dataview:external-link'
})
dv.list(queryResult.value.values)
```结果:

如果读者有那个精力也可以去扩展自己的 Widget,作者就浅尝辄止,不再过多去探索了。
TaskResult 类型
用于表示任务类查询的结果。我们可以遍历所有任务将未完成的任务强制完成,或者改变任务中的任何属性,需要注意的是由于在 Dataview 结果或者任务原始位置将任务状态改变,Dataview 都会重新执行查询。如果在查询结果中改变状态,而代码中又将其全部标记为已完成,这会陷入一个死角,所以不建议在文档的代码区域来改变任务的状态信息,而是结合 Obsidian 的命令来一健完成或取消完成任务更加合理。
下面给出一个改变任务状态的示例代码:
```dataviewjs
const query = `
TASK
WHERE file = this.file
`
const queryResult = await dv.query(query)
queryResult.value.values.forEach(row => {
row.annotated = true
row.checked = true
row.completed = true
row.fullCompleted: true
row.status = 'x'
})
dv.taskList(queryResult.value.values)
```CalendarResult 类型
我们在前面说过 Dataview API 并没有提供输出日历的方法,因此这里我们解析出来的日历数据就得另寻他法来渲染。我们这里就不再额外说明了,有一个渲染年度日历数据的案例会在我们系列文章的第 3 篇进行讲解。
这一小节最后再说一下 dv.tryQuery() 方法,它的使用和 dv.query() 一样,只不过没有 Success 和 Failure 类型封装,而是直接返回 { type: 'xx', values: 'xx' } 结构的数据,对于 TableResult 类型的数据其在 value 中的属性也自动变成 { type: 'xx', headers: [xx], idMeaning: {...}, values: [...]} 的结构。最后如果不符合 DQL 查询语法会直接在文档中抛出错误。
dv.queryMarkdown() 和 dv.tryQueryMarkdown() 方法
这 2 个方法的实际用法同 dv.query() 和 dv.tryQuery(),只不过它是将结果以 Markdown 语法原始格式输出。
```dataviewjs
const query = `
TABLE rows.file.link AS 书籍
FROM "10 Example Data/books"
GROUP BY author AS 作者
`
const queryResult = await dv.tryQueryMarkdown(query)
console.log(queryResult)
dv.paragraph(queryResult)
```输出的 Markdown 格式结果:
| 作者 | 书籍 |
| -------- | ----------------------------------------------------------------------------------------------------------------------- |
| \- | <ul><li> [![10 Example Data/books/books_7.md\\|books_7]]</li></ul> |
| Alice A | <ul><li> [![10 Example Data/books/books_2.md\\|books_2]]</li></ul> |
| Berta B | <ul><li> [![10 Example Data/books/books_3.md\\|books_3]]</li><li> [![10 Example Data/books/books_6.md\\|books_6]]</li></ul> |
| Conrad C | <ul><li> [![10 Example Data/books/books_4.md\\|books_4]]</li><li> [![10 Example Data/books/books_5.md\\|books_5]]</li></ul> |
| Dora D | <ul><li> [![10 Example Data/books/books_1.md\\|books_1]]</li></ul>在文档中的渲染结果:

这个结果渲染明显有问题,所以我提了一个 issue 给官方,期望下个版本能解决。
dv.evaluate() 和 dv.tryEvaluate() 方法
这两个方法的作用实际上是执行 DQL 查询语法中的表达式。同样两个函数的区别在于执行成功与失败是否有包装一层方便用户自行处理异常情况的区分。
两个方法的第二个可选参数 context 为一个对象,用于为表达式中的变量提供值。
为了方便参考,我直接将官方支持的表达式贴出来:
# Literals
1 (number)
true/false (boolean)
"text" (text)
date(2021-04-18) (date)
dur(1 day) (duration)
[[Link]] (link)
[1, 2, 3] (list)
{ a: 1, b: 2 } (object)
# Lambdas
(x1, x2) => ... (lambda)
# References
field (directly refer to a field)
simple-field (refer to fields with spaces/punctuation in them like "Simple Field!")
a.b (if a is an object, retrieve field named 'b')
a[expr] (if a is an object or array, retrieve field with name specified by expression 'expr')
f(a, b, ...) (call a function called `f` on arguments a, b, ...)
# Arithmetic
a + b (addition)
a - b (subtraction)
a * b (multiplication)
a / b (division)
a % b (modulo / remainder of division)
# Comparison
a > b (check if a is greater than b)
a < b (check if a is less than b)
a = b (check if a equals b)
a != b (check if a does not equal b)
a <= b (check if a is less than or equal to b)
a >= b (check if a is greater than or equal to b)
# Strings
a + b (string concatenation)
a * num (repeat string <num> times)
# Special Operations
[[Link]].value (fetch `value` from page `Link`)使用如下:
test:: 测试变量
```dataviewjs
dv.paragraph(dv.evaluate("x + y + z", {x: 1, y: 2, z: 3}).value) // 6
dv.paragraph(dv.evaluate("x + y + z", {x: 1, y: 2, z: 3}).successful) // true
dv.paragraph(dv.tryEvaluate("12 + val", {val: "world"})) // 12world
dv.paragraph(dv.tryEvaluate("hello + val", {val: "world"})) // -world
dv.paragraph(dv.tryEvaluate("val*3", {val: "world"})) // worldworldworld
dv.paragraph(dv.tryEvaluate("this.test")) // 测试变量
dv.paragraph(dv.tryEvaluate("length(this.file.tasks)")) // 0
dv.paragraph(dv.tryEvaluate("1 + 2 * 10")) // 21
dv.paragraph(dv.tryEvaluate("this.file.name")) // Untitled
dv.paragraph(dv.tryEvaluate("date(now)")) // 11:34 上午 - 5 25, 2024
dv.paragraph(dv.tryEvaluate("date(now) + dur(1d30m)")) // 12:06 下午 - 5 26, 2024
```文件 I/O 操作
I/O 操作是指输入 (Input)/输出 (Output) 操作,通常用于读取/写入文件。在 Dataview 中我们使用 dv.io.csv(path, [origin-file]) 来解析 CSV 文件,使用 dv.io.load(path, [origin-file]) 来读取文件的内容,使用 dv.io.normalize(path, [origin-file]) 将相对路径转换成绝对路径。
dv.io.csv() 方法
首先我们在当前编辑的文件同目录创建一个名为 person.csv 的 CSV 文件,然后复制以下内容粘贴进去:
姓名,性别,年龄
张三,男,20
李四,女,23
stu1,男,18
stu2,女,19现在,我们来通过 dv.io.csv() 方法读取数据,看一下读取数据后会被转换成什么样的结构。
```dataviewjs
const data = await dv.io.csv("person.csv")
console.log(data.array())
```因为 dv.io.csv() 是一个异步方法,因此我们需要在调用方法时加上 await 关键词。数据读取后会返回一个 DataArray 结构的数据,通过前面的讲解,我们可以直接使用 array() 方法将数据输出为 JavaScript 数组的形式。
CSV 数据经过 Dataview 解析后每一行(除了表头)会转换成 {表头名: 数据值} 的格式。接下来我们来将其渲染到页面中。
```dataviewjs
const data = await dv.io.csv("person.csv")
const headers = Object.keys(data[0])
const values = data.map(item => Object.values(item))
dv.table(headers, values)
```结果:

可选择参数 origin-file 的作用是指定解析文件所基于的相对目录,如果文档中存在多个同名的文件,在 path 中并没有带路径的话,默认在当前目录中查找。如果我们将第二个参数指定为 / 就会从根目录寻找。
如果指定的文件不存在,则会返回 undefined。
dv.io.load() 方法
这个方法用于读取文件,对于文本文件(如:Markdown, CSV, TXT 等)会直接原样输出文本内容,对于其它文件(如:PDF)可能会显示为乱码、特殊字符、转义序列、二进制表示,或者可能根本不显示这些数据,甚至抛出错误。
使用方式同 dv.io.csv(),只不过返回的数据是字符串(文本),需要自己去解析。
dv.io.normalize() 方法
这个方法的作用是规范路径,将不带路径目录的链接转换成基于当前 Vault 的绝对路径。
现在我们在根目录创建了一个 person.csv 文件,同时也在目录 dir1/dir2 和 dir1/dir2/dir3 中同时创建,然后来看一下使用效果:
```dataviewjs
console.log(dv.io.normalize("not-exist")) // not-exist
console.log(dv.io.normalize("not-exist", "/")) // not-exist
console.log(dv.io.normalize("not-exist.csv")) // not-exist.csv
console.log(dv.io.normalize("not-exist.csv", "/")) // not-exist.csv
console.log(dv.io.normalize("person.csv")) // dir1/dir2/dir3/person.csv
console.log(dv.io.normalize("person.csv", "/")) // person.csv
console.log(dv.io.normalize("person.csv", "not/exist/")) // person.csv
console.log(dv.io.normalize("person.csv", "dir1/dir2/")) // dir1/dir2/person.csv
```从结果来看,如果不指定第二个参数会返回当前传入的第一个参数。在指定第二个参数的情况下,如果文件不存在则原样返回,如果指定的路径不存在同样如此。只有在路径和文件都正确的情况下来能得到正确的路径。
自定义视图
使用 dv.view(path, input) 方法来构建自己的视图,是一项挺有创造性的事情,它可以把我们介绍的知识点全部融入进来创建可复用的,可分发的功能集。
使用这个方法我们可以将 JavaScript 脚本和样式放置在一个目录中,然后将其异步加载并传入参数运行,默认名称约定为 view.js 和 view.css。
下面我们用一个问候函数来举例,更多高级的用法后续案例分析篇会重点讲解。
%% views/demo/view.js %%
```js
function greet(name) {
return dv.el('h1', `你好,${name}`, { cls: 'demo' })
}
greet(input.name)
```
%% views/demo/view.css %%
```css
.demo {
color: red!important;
}
```
```dataviewjs
await dv.view("views/demo", { name: "Dataview" })
```结果:

代码中,所有传入的参数都存放在 input 对象中,样式我们使用了 !important 来提升优先级,不然会被 h1, .markdown-rendered h1 所覆盖。
辅助方法
我们在前面的代码中判断数组使用的是 Array.isArray() 方法,实际上官方也提供了一个同名的方法为 dv.isArray(),此外还提供了
dv.compare(a, b)比较任意 JavaScript 值,如果a > b则返回1,相等返回0,小于则返回-1。dv.equal(a, b)判断任意两个 JavaScript 值是否相等。dv.clone(value)深拷贝值。dv.parse(value)主要用于将字符串解析为链接、日期和持续时间。
举例:
```dataviewjs
const a = {a: 1, b: 2, c: [1, 2, 3, [4, [5, 6]]], d: {e: 1, f: 2}}
const b = {a: 1, b: 2, c: [1, 2, 3, [4, [5, 6]]], d: {e: 1, f: 2}}
const c = {a: 1, b: 2, c: b.c, d: {e: 1, f: 2}}
const d = {a: 1, b: 2, c: b.c, d: 5}
const e = dv.clone(a)
console.log(dv.isArray(a.c)) // true
console.log(dv.equal(a, b)) // true
console.log(dv.equal(a, c)) // true
console.log(dv.equal(a, d)) // false
console.log(dv.equal(a, e)) // true
console.log(dv.compare(a, b)) // 0
console.log(dv.compare(a, c)) // 0
console.log(dv.compare(a, d)) // -1
console.log(dv.parse("[[Welcome]]")) // Link {path: 'Welcome', display: undefined, subpath: undefined, embed: false, type: 'file'}
console.log(dv.parse("2024-05-25")) // DateTime {ts: 1716566400000, _zone: SystemZone, loc: Locale, invalid: null, weekData: null, …}
console.log(dv.parse("1d")) // Duration {values: {…}, loc: Locale, conversionAccuracy: 'casual', invalid: null, matrix: {…}, …}
```Luxon 库介绍
Luxon 是一个完整的日期与时间处理库,它提供了 ISO 8601 规范的解析、格式化、本地化以及日期与时间运算等功能。在 Dataview 中我们使用 dv.luxon 来获取 Luxon 实例。
Luxon 提供了以下几个操作类:
DateTime: 表示特定的毫秒时间,以及时区和区域设置。Duration: 表示时间量,例如:“1 小时 5 分钟”。FixedOffsetZone: 表示任何永不改变偏移的区域,例如 UTC。IANAZone: 通过 IANA 字符串来标识区域,例如:“Asia/Shanghai”。Info: 包含用于检索与常规时间和日期相关的数据的静态方法。例如,它具有用于查找时区是否具有 DST、列出任何受支持区域设置中的月份的方法,以及用于发现当前环境中可用的 Luxon 功能。Interval: 表示半开的时间间隔,其中每个终结点都是一个DateTime。InvalidZone: 表示解析失败的区域。Settings: 设置包含控制 Luxon 整体行为的静态 getter 和 setter。SystemZone: 表示当前 JavaScript 运行环境的本地区域。Zone: 表示区域。
在 Dataview 中我们只关心如何使用 DateTime 和 Duration 这 2 个类。因为文章主要但要 Dataview 的使用,所以只会介绍 Luxon 的常用功能。
接下来文章中使用的 DateTime 均指代 dv.luxon.DateTime,Duration 同样如此。
Note这部分但介绍的内容有点多,实际在 Dataview 中我们可能并不会涉及到所有这些知识。
DateTime 使用
DateTime 是一种不可变的数据结构,表示特定的日期和时间以及附带的方法。它包含用于创建、分析、查询、转换和格式化的类和实例方法。
创建日期和时间
Luxon 提供了多种方式来创建和获取日期和时间。
DateTime.now()方法在系统的时区中为当前时刻创建DateTime。- 使用
DateTime.local(year?, month, day, hour, minute, second, millisecond)创建。 - 使用
DateTime.utc(year?, month, day, hour, minute, second, millisecond)创建。 - 从 JavaScript 日期对象去解析(
DateTime.fromJSDate(date, options))。 - 从 ISO 8601 解析(
DateTime.fromISO(test, opts))。 - 从时间缀去解析(
DateTime.fromMillis(milliseconds, options)和DateTime.fromSeconds(seconds, options))。 - 从 JavaScript 对像创建(
DateTime.fromObject(obj, opts))。 - 从字符串中以特定格式去解析(
DateTime.fromFormat(text, fmt, opts))。
```dataviewjs
const dt = dv.luxon.DateTime
const print = date => console.log(date.toFormat('yyyy-MM-dd HH:mm:ss'))
print(dt.now()) // 2024-05-06 17:08:32
print(dt.local(2023, 8, 20)) // 2023-08-20 00:00:00
print(dt.local(2023, 8, 20, 8, 45, 0)) // 2023-08-20 00:00:00
console.log(dt.local(2017, 3, 12, { locale: "fr" }).toLocaleString(DateTime.DATE_FULL)) // 12 mars 2017
console.log(dt.local(2017, 3, 12, { zone: 'America/New_York' }).toFormat('FFFF')) // 2017年3月12日星期日 北美东部标准时间 0:00:00
print(dt.utc(2023, 8, 20, 8, 45, 22)) // 2023-08-20 08:45:22
print(dt.fromObject({ year: 2023, month: 8, day: 20, hour: 8, minute: 45, second: 23})) // 2023-08-20 08:45:23
print(dt.fromJSDate(new Date())) // 2024-05-06 17:35:58
print(dt.fromMillis(1714983450291)) // 2024-05-06 16:17:30
print(dt.fromSeconds(1646710400)) // 2022-03-08 11:33:20
print(dt.fromISO('2023-08-20')) // 2023-08-20 00:00:00
print(dt.fromISO('2023-08-20T08:23:23')) // 2023-08-20 08:23:23
print(dt.fromISO('2024-01-11T10:30:25+03:00')) // 2024-01-11 15:30:25
print(dt.fromISO('2023-W34-2T04:04:04')) // 2023-08-22 04:04:04
print(dt.fromFormat('12/17/2025', 'MM/dd/yyyy')) // 2025-12-17 00:00:00
print(dt.fromFormat('May 25, 1982', 'MMMM dd, yyyy')) // 1982-05-25 00:00:00
```输出时期和时间
将一个 DateTime 对象解析成易于读取的方式,我们可以选择使用 toFromat() 函数来使用格式字符显示表示一个日期和时间,也可以使用特定格式规范表示的输出函数如:toJSDate(),toISO(),toISODate(),toRFC2822() 等,也可以单独获取年、月、日、时、分、钞、季度和周信息,例如:dt.now().year。
获取 DateTime 对象属性
一个日期和时间通常可以解读为年、月、日、时、分、秒、毫秒、区域、季度、周等,下面我们通过实例来快速一阅。
```dataviewjs
const dt = dv.luxon.DateTime
console.log(dt.now().get("year")) // 2024
console.log(dt.now().locale) // zh-CN
console.log(dt.now().zone.ianaName) // Asia/Shanghai
console.log(dt.now().zone.name) // Asia/Shanghai
console.log(dt.now().zoneName) // zh-CN
console.log(dt.now().year) // 2024
console.log(dt.now().quarter) // 2
console.log(dt.now().month) // 5
console.log(dt.now().day) // 7
console.log(dt.now().hour) // 15
console.log(dt.now().minute) // 24
console.log(dt.now().second) // 1
console.log(dt.now().millisecond) // 661
console.log(dt.now().weekYear) // 2024
console.log(dt.now().weekNumber) // 19
console.log(dt.now().weekday) // 2
console.log(dt.now().ordinal) // 128
console.log(dt.now().monthShort) // 5月
console.log(dt.now().monthLong) // 五月
console.log(dt.now().offset) // 480
console.log(dt.now().offsetNameShort) // GMT+8
console.log(dt.now().offsetNameLong) // 中国标准时间
console.log(dt.now().isOffsetFixed) // false
console.log(dt.now().isInDST) // false
console.log(dt.now().isInLeapYear) // true
console.log(dt.now().daysInYear) // 366
console.log(dt.now().weeksInWeekYear) // 52
console.log(dt.now().resolvedLocaleOptions()) // {locale: 'zh-CN', numberingSystem: 'latn', outputCalendar: 'gregory'}
```toFormat(fmt, opts) 函数
使用格式字符(又叫令牌(Token))来格式化日期和时间是比较常用的一种方式,通常我们使用 yyyy-MM-dd HH:mm:ss 来显示日期和时间,下面是一些简单使用举例:
```dataviewjs
const dt = dv.luxon.DateTime
console.log(dt.now().toFormat('yyyy-MM-dd HH:mm:ss')) // 2024-05-06 14:55:23
console.log(dt.now().toFormat('MMMM dd, yyyy')) // May 06, 2024
console.log(dt.now().setLocale('fr').toFormat('MMMM dd, yyyy')) // mai 06, 2024
console.log('IANA区域:', dt.now().toFormat('z')) // IANA区域:Asia/Shanghai
console.log('周数:', dt.now().toFormat('WW'), '周') // 周数: 19 周
console.log('一年中的第:', dt.now().toFormat('ooo'), '天') // 一年中的第: 127 天
console.log('包含完整月份和工作日的本地化日期:', dt.now().toFormat('DDDD')) // 包含完整月份和工作日的本地化日期 2024年5月6日星期一
console.log('带秒和完整偏移的本地时间:', dt.now().toFormat('tttt')) // 带秒和完整偏移的本地时间: 中国标准时间 19:02:48
console.log('额外详细的本地化日期和时间(以秒为单位):', dt.now().toFormat('FFFF')) // 额外详细的本地化日期和时间(以秒为单位): 2024年5月6日星期一 中国标准时间 19:04:22
console.log('unix 时间戳(以秒为单位):', dt.now().toFormat('X')) // unix 时间戳(以秒为单位): 1714993513
console.log('unix 时间戳(以毫秒为单位):', dt.now().toFormat('x')) // unix 时间戳(以毫秒为单位): 1714993520929
```更多格式化符号请参考:Formatting (moment.github.io)
在格式化时 Luxon 还提供了一种在双引号中使用单引号进行字符串转义的使用方式,举例如下:
```dataviewjs
const dt = dv.luxon.DateTime
console.log(dt.now().toFormat("HH 'hours' mm 'minutes'")) // 12 hours 08 minutes
console.log(dt.now().toFormat("'现在是:'HH'点'mm'分'")) // 现在是:13点18分
```toLocaleString(formatOpts, opts) 函数
返回表示此日期的本地化字符串。接受与 Intl.DateTimeFormat 构造函数相同的选项以及 Luxon 定义的任何预设,如 DateTime.DATE_FULL 或 DateTime.TIME_SIMPLE。
下面是官方提供的预设在作者本地环境输出示例:
```dataviewjs
const dt = dv.luxon.DateTime
console.log(dt.now().toRFC2822())
console.log(dt.now().toLocaleString(dt.DATE_SHORT)) // 2024/5/6
console.log(dt.now().toLocaleString(dt.DATE_MED)) // 2024年5月6日
console.log(dt.now().toLocaleString(dt.DATE_MED_WITH_WEEKDAY)) // 2024年5月6日周一
console.log(dt.now().toLocaleString(dt.DATE_FULL)) // 2024年5月6日一
console.log(dt.now().toLocaleString(dt.DATE_HUGE)) // 2024年5月6日星期一
console.log(dt.now().toLocaleString(dt.TIME_SIMPLE)) // 19:21
console.log(dt.now().toLocaleString(dt.TIME_WITH_SECONDS)) // 19:21:47
console.log(dt.now().toLocaleString(dt.TIME_WITH_SHORT_OFFSET)) // GMT+8 19:22:05
console.log(dt.now().toLocaleString(dt.TIME_WITH_LONG_OFFSET)) // 中国标准时间 19:22:20
console.log(dt.now().toLocaleString(dt.TIME_24_SIMPLE)) // 19:22
console.log(dt.now().toLocaleString(dt.TIME_24_WITH_SECONDS)) // 19:23:03
console.log(dt.now().toLocaleString(dt.TIME_24_WITH_SHORT_OFFSET)) // GMT+8 19:23:50
console.log(dt.now().toLocaleString(dt.TIME_24_WITH_LONG_OFFSET)) // 中国标准时间 19:24:01
console.log(dt.now().toLocaleString(dt.DATETIME_SHORT)) // 2024/5/6 19:24
console.log(dt.now().toLocaleString(dt.DATETIME_MED)) // 2024年5月6日 19:25
console.log(dt.now().toLocaleString(dt.DATETIME_MED_WITH_WEEKDAY)) // 2024年5月6日周一 19:25
console.log(dt.now().toLocaleString(dt.DATETIME_FULL)) // 2024年5月6日 GMT+8 19:25
console.log(dt.now().toLocaleString(dt.DATETIME_HUGE)) // 2024年5月6日星期一 中国标准时间 19:26
console.log(dt.now().toLocaleString(dt.DATETIME_SHORT_WITH_SECONDS)) // 2024/5/6 19:26:30
console.log(dt.now().toLocaleString(dt.DATETIME_MED_WITH_SECONDS)) // 2024年5月6日 19:27:23
console.log(dt.now().toLocaleString(dt.DATETIME_FULL_WITH_SECONDS)) // 2024年5月6日 GMT+8 19:27:09
console.log(dt.now().toLocaleString(dt.DATETIME_HUGE_WITH_SECONDS)) // 2024年5月6日星期一 中国标准时间 19:26:57
```除了显示本地环境输出外,我们也可以通过调用 setLocale() 函数来指定其它语言输出环境:
console.log(dt.now().setLocale('fr').toLocaleString(DateTime.DATE_FULL)) // 7 mai 2024Intl 对象是 ECMAScript 国际化 API 的命名空间,它提供对语言敏感的字符串比较、支持数字格式化以及日期和时间的格式化。下面我们使用 Intl.DateTimeFormat 相同的选项来格式化日期和时间:
```dataviewjs
console.log(dt.now().toLocaleString({
year: 'numeric',
weekday: 'long',
month: 'long',
day: '2-digit',
hour: '2-digit',
minute: '2-digit',
second: '2-digit',
hour12: true
})) // 2024年5月06日星期一 下午08:23:52
console.log(dt.now().toLocaleString({
year: '2-digit',
weekday: 'short',
})) // 24年 周一
```从上面的示例中可以看出在格式化日期和时间相关的数据时,有 full / long / medium / short / 2-digit / numeric 这几种样式选项,下面通过一个表格来更好的演示几种样式的不同:
| 日期和时期属性 | full | long | medium | short | 2-digit | numeric |
|---|---|---|---|---|---|---|
年(year) | - | - | - | - | 24 年 | 2024 年 |
月(month) | - | 五月 | - | 5 月 | 05 月 | 5 月 |
日(day) | - | - | - | - | 06 日 | 6 日 |
时(hour) | - | - | - | - | 20 时 | 20 时 |
分(minute) | - | - | - | - | 14 | 11 |
秒(second) | - | - | - | - | 19 | 7 |
周(weekday) | - | 星期一 | - | 周一 | - | - |
需要注意的是如果要将小时数设置为 12 小时制,需要将选项 hour12 设置为 false。
输出为 ISO 8601 格式
ISO 8601 是使用最广泛的日期和时间字符串格式集。下面给出几个 Luxon 提供的相关输出函数示例:
```dataviewjs
const dt = dv.luxon.DateTime
console.log(dt.now().toISO()) // 2024-05-07T11:51:35.464+08:00
console.log(dt.now().toISODate()) // 2024-05-07
console.log(dt.now().toISOWeekDate()) // 2024-W19-2
console.log(dt.now().toISOTime()) // 11:52:22.894+08:00
```输出为 Unix 时间缀
通常,日期和时间的数值表达形式包括毫秒和秒两种,用于精确呈现时间数据。
```dataviewjs
const dt = dv.luxon.DateTime
console.log(dt.now().toMillis()) // 1715054074747
console.log(dt.now().toSeconds()) // 1715054084.961
console.log(dt.now().toUnixInteger()) // 1715054097
console.log(dt.now().valueOf()) // 1715054111806
```输出 JavaScript 格式
这里主要是指输出为 JavaScript 对象,Date 日期格式以及 JSON 格式。
```dataviewjs
const dt = dv.luxon.DateTime
console.log(dt.now().toJSDate()) // Tue May 07 2024 14:32:53 GMT+0800 (中国标准时间)
console.log(dt.now().toJSON()) // 2024-05-07T14:29:54.238+08:00
console.log(dt.now().toObject()) // {year: 2024, month: 5, day: 7, hour: 14, minute: 28, second: 12, millisecond: 374}
```输出相对时间
将输出的日期和时间与当前对比,输出类似于 x天前、前天 、去年 这种描述形式。
```dataviewjs
const dt = dv.luxon.DateTime
const date = dt.local(2024, 5, 5, 22, 23, 12)
const date2 = dt.local(2023, 8, 5, 22, 23, 12)
const date3 = dt.local(2024, 5, 9, 22, 23, 12)
console.log(date.toRelativeCalendar()) // 前天
console.log(date.toRelative()) // 1天前
console.log(date2.toRelativeCalendar()) // 去年
console.log(date2.toRelative()) // 9个月前
console.log(date3.toRelativeCalendar()) // 后天
console.log(date3.toRelative()) // 2天后
```其它输出
这里是一些不常用,但会在特定场景下适用的输出方式:
```dataviewjs
const dt = dv.luxon.DateTime
console.log(dt.now().toRFC2822()) // Tue, 07 May 2024 15:05:47 +0800
console.log(dt.now().toHTTP()) // Tue, 07 May 2024 07:06:25 GMT
console.log(dt.now().toSQLDate()) // 2024-05-07
console.log(dt.now().toSQLTime()) // 15:07:04.616 +08:00
console.log(dt.now().toSQL()) // 2024-05-07 15:07:23.940 +08:00
console.log(dt.now().toBSON()) // Tue May 07 2024 15:08:04 GMT+0800 (中国标准时间)
```日期和时间的数学运算
这里所指的运算通常是日期的相加、相减、差异比较等。在运算中不变的是时间始终为 60 分钟,分钟始终为 60 秒,秒始终为 1000 毫秒,其余的很多都不是固定的,比如年份因闰年而异,月份各不尽相同,季度始终为 3 个月,但是月份长度不同,因此天数也不相同等等。
相加和相减
使用 plus(duration: (Duration | Object | number)): DateTime 和 minus(duration: (Duration | Object | number)): DateTime) 来对日期和时间执行加减操作。
```dataviewjs
const dt = dv.luxon.DateTime
const print = date => console.log(date.toFormat('yyyy-MM-dd HH:mm:ss.SSS'))
const now = dt.local(2024, 5, 7, 12, 0, 0, 100)
print(now) // 2024-05-07 12:00:00.100
print(now.plus(55)) // 2024-05-07 12:00:00.155
print(now.plus({ minutes: 30 })) // 2024-05-07 12:30:00.100
print(now.plus({ days: 2 })) // 2024-05-09 12:00:00.100
print(now.plus({ days: -2 })) // 2024-05-05 12:00:00.100
print(now.minus({ days: 2 })) // 2024-05-05 12:00:00.100
print(now.plus({ hours: 5, minutes: 30 })) // 2024-05-07 17:30:00.100
print(now.plus(Duration.fromObject({ hours: 3, minutes: 13 }))) // 2024-05-07 15:13:00.100
```在上面的示例中我们传入的 duration 如果为对象则可以使用下面的属性单位:
years: 年months: 月days: 天数quarters: 季度weeks: 周数hours: 小时数minutes: 分钟数seconds: 秒数
比较
可以使用 <、> 、<= 和 >= 来进行日期和时间比较,因为 DateTime 在比较时使用了 valueOf() 函数返回纪元时间缀进行数字对比。
```dataviewjs
const dt = dv.luxon.DateTime
const date1 = dt.local(2024, 5, 7, 12, 0, 0, 100)
const date2 = dt.local(2024, 5, 7, 12, 12, 30, 100)
const date3 = dt.local(2024, 5, 7, 12, 0, 0, 100)
console.log(date1 > date2) // false
console.log(date1 >= date3) // true
```此外,还可以使用 hasSame(otherDateTime: DateTime, unit: string, opts: Object): boolean 函数来进行微妙的比较。需要注意的是这里的比较是基于日历进行检查的,也就是说在比较月的时候我们要保证年份是相同的,同理,比较分钟时,要确保是在同样的小时内。
```dataviewjs
const dt = dv.luxon.DateTime
const date1 = dt.local(2024, 5, 7, 12, 0, 0, 100)
const date2 = dt.local(2024, 5, 7, 12, 12, 30, 100)
const date3 = dt.local(2022, 5, 7, 12, 22, 22, 100)
console.log(date1.hasSame(date3, 'year')) // false
console.log(date1.hasSame(date2, 'month')) // true
console.log(date1.hasSame(date2, 'minute')) // false
```差异
使用 diff(otherDateTime: DateTime, unit: (string | Array<string>), opts: Object): Duration 函数可以来对比两个日期和时间的差异。如果要比较与当前时刻的时差,可以使用 diffNow(unit: (string | Array<string>), opts: Object): Duration 函数。
```dataviewjs
const dt = dv.luxon.DateTime
const d1 = dt.local(2024, 5, 7, 12, 23, 45, 100)
const d2 = dt.local(2023, 11, 27, 12, 23, 45, 100)
console.log(d1.diff(d2, 'years').toObject()) // {years: 0.4426229508196721}
console.log(d1.diff(d2, 'months').toObject()) // {months: 5.333333333333333}
console.log(d1.diff(d2, 'days').toObject()) // {days: 162}
console.log(d1.diff(d2).toObject()) // {milliseconds: 13996800000}
console.log(d1.diff(d2, ['months', 'days']).toObject()) // {months: 5, days: 10}
console.log(d1.diffNow('hours').toObject()) // {hours: -5.035617222222222}
```获取日期和时间的开始和结束表示
有时候我们想要舍弃日期和时间中的一部分值,比如只关心小时数,不关心具体多少秒,或者我们想输出一天的开始和结束时间,即:00:00:00 - 23:59:59 这种形式,这时可以使用 statOf(unit: string, opts: Object): DateTime 和 endOf(unit: string, opts: Object): DateTime 函数来实现:
```dataviewjs
const dt = dv.luxon.DateTime
const d = dt.local(2024, 5, 7, 12, 23, 45, 100)
console.log(d.startOf('year').toISODate()) // 2024-01-01
console.log(d.startOf('year').toISO()) // 2024-01-01T00:00:00.000+08:00
console.log(d.startOf('month').toISO()) // 2024-05-01T00:00:00.000+08:00
console.log(d.startOf('minute').toISOTime()) // 12:23:00.000+08:00
console.log(d.endOf('year').toISO()) // 2024-12-31T23:59:59.999+08:00
console.log(d.endOf('minute').toISOTime()) // 12:23:59.999+08:00
```Duration 使用
持续时间(Duration)指一个时间段的长度,比如几天、几小时、几分钟等。
创建持续时间
要创建一个持续时间,可以通过以下几种试:
- 通过
fromMillis(count: number, opts: Object): Duration函数传入毫秒数。 - 通过
fromObject(obj: Object, opts: Object): Duration函数传入一个对象(属性包含:years|quarters|months|weeks|days|hours|minutes|seconds|milliseconds)。 - 通过
fromDurationLike(durationLike: (Object | number | Duration)): Duration函数,个函数相当于不传opts的fromMillis()和fromObject()函数,同时还持续传入已有的Duration对象实例来创建持续时间。 - 通过
fromISO(text: string, opts: Object): Duration和fromISOTime(text: string, opts: Object): Duration函数来创建。
```dataviewjs
const dur = dv.luxon.Duration
const d = dur.fromMillis(1715238823499)
console.log(dur.fromMillis(86400000).toObject()) // {milliseconds: 86400000}
console.log(dur.fromObject({ hours: 2, minutes: 8 }).toObject()) // {hours: 2, minutes: 8}
console.log(dur.fromDurationLike(86400000).toObject()) // {milliseconds: 86400000}
console.log(dur.fromDurationLike({ hours: 2, minutes: 8 }).toObject()) // // {hours: 2, minutes: 8}
console.log(dur.fromDurationLike(d).toObject()) // {milliseconds: 1715238823499}
console.log(dur.fromISO('P3Y6M1W4DT12H30M5S').toObject()) // { years: 3, months: 6, weeks: 1, days: 4, hours: 12, minutes: 30, seconds: 5 }
console.log(dur.fromISOTime('11:22:33.444').toObject()) // { hours: 11, minutes: 22, seconds: 33, milliseconds: 444 }
```Note对于 ISO 格式的持续时间请参考官方网站,这里不作说明。
输出持续时间
这时令 d 为一个 Duration 的实例,可以通过 d.locale 获取当前持续时间的本地类型,通常为 zh-CN,然后通过 years | quarters | months | weeks | days | hours | minutes | seconds | milliseconds 实例属性可获取相应的日期和时间值,也可以将基作为参数传入 get() 函数来获取值,例如:d.get("months")。
接下来我们看一下几个相关的输出函数:
toFormat() 函数
通过前面 DateTime 的介绍,相信对于这个函数的使用不会存在任何疑惑,但是这里需要注意的是这是一个阉割版的,因为它所支持的格式符号仅限以下几种:
S: 毫秒s: 秒m: 分钟h: 小时d: 天w: 周M: 月y: 年,yy将填充为 2 位年数表示法。
这里的 toFormat() 函数同样也支持在字符串内使用单引号进行转义。
```dataviewjs
const dur = dv.luxon.Duration
const d = dur.fromISO('P3Y6M1W4DT12H30M5S')
console.log(d.toFormat('yy-MM-dd hh-mm-ss')) // 03-06-11 12-30-05
console.log(d.toFormat("yy'年'MM'月'")) // 03年06月
```toHuman() 函数
toHuman(opts: Object) 函数返回包含所有单位的 Duration 的字符串表示形式。
```dataviewjs
const dur = dv.luxon.Duration
const d = dur.fromISO('P3Y6M1W4DT12H30M5S')
console.log(d.toHuman()) // 3年、6个月、1周、4天、12小时、30分钟、5秒钟
console.log(d.toHuman({ unitDisplay: 'short' })) // 3年、6个月、1周、4天、12小时、30分钟、5秒
```Tips
toObject() 函数
这个函数就是将持续时间输出为 JavaScript 对象表示,没有什么好说的。
toISO() / toISOTime() 函数
ISO 8601 形式的持续时间表示法,对很多人来讲很陌生,作者也是一样第一次接触,但是查阅相关资源后其实也挺容易理解的,例如:P5M 表示 5个月,下面作一个简单的介绍。
持续时间以 P (表示 Period) 开头,格式为:
P[n]Y[n]M[n]DT[n]H[n]M[n]SP[n]WP<date>T<time>
基中 [n] 为要被替换的具体日期或时间值,例如 P2Y 表示 02年,P1Y-2M 表示 1年负2个月,也就是 10个月。
W 表示周数,例如:P2W 表示 第2周。
T 后面表示时间,格式为 Thh:mm:ss.sss 或者 hh:mm:ss.sss,可通过 toISOTime() 函数的选项 opts.includePrefix 来控制是否显示前缀 T。
下面是一些示例:
```dataviewjs
const dur = dv.luxon.Duration
console.log(dur.fromObject({years: 2024}).toISO()) // P2024Y
console.log(dur.fromObject({months: 5}).toISO()) // P5M
console.log(dur.fromObject({weeks: 5}).toISO()) // P5W
console.log(dur.fromObject({minutes: 5}).toISO()) // PT5M
console.log(dur.fromObject({seconds: 5}).toISO()) // PT5S
console.log(dur.fromObject({seconds: 5, milliseconds: 234}).toISO()) // PT5.234S
console.log(dur.fromObject({ hours: 11 }).toISOTime()) // 11:00:00.000
console.log(dur.fromObject({ hours: 11 }).toISOTime({ suppressMilliseconds: true })) // 11:00:00
console.log(dur.fromObject({ hours: 11 }).toISOTime({ includePrefix: true })) // T11:00:00.000
console.log(dur.fromObject({ hours: 11 }).toISOTime({ format: 'basic' })) // 110000.000
```Tips还有 2 个函数
toJSON()和toString()也是输出为 ISO 8601,只不过一个适用于 JSON,一个适用于调式。
除了上述几个函数外,还可以使用 toMillis() 和 valueOf() 来输出持续时间的毫秒表示。
持续时间的数学运算
持续时间的数学运算只支持相加(plus(duration: (Duration | Object | number)): Duration)和相减(minus(duration: (Duration | Object | number)): Duration)以及比较(equals(others: Duration): boolean)运算,此外还提供了一个遍历函数 mapUnits(fn: function): Duration 来根据条件作运算。
```dataviewjs
const dur = dv.luxon.Duration
const dur1 = dur.fromISO('P1Y')
const dur2 = dur.fromISO('P2M')
console.log(dur1.equals(dur2)) // false
console.log(dur1.plus(dur2).toISO()) // P1Y2M
console.log(dur1.minus(dur2).toISO()) // P1Y-2M
console.log(dur1.plus(dur2).mapUnits(x => x * 2).toISO()) // P2Y4M
console.log(dur1.plus(dur2).mapUnits((x, u) => u === "months" ? x * 3 : x).toISO()) // P1Y6M
```日期和时间的换算
我们知道 1 天有 24 小时,1 小时有 60 分钟,1 分钟有 60 秒,1 秒有 1000 毫秒,然后 1 天可以表示成 8640000 毫秒,在 Luxon 中提供了 as(unit: string): number 和 shiftTo(units: ...any): Duration 函数来处理,些外还有一个 shiftToAll(): Duration 函数,等同于调用 shiftTo("years", "months", "weeks", "days", "hours", "minutes", "seconds", "milliseconds")。
```dataviewjs
const dt = dv.luxon.DateTime
const dur = dv.luxon.Duration
const d1 = dt.local(2024, 5, 7, 12, 23, 45, 100)
const dur1 = dur.fromObject({days: 1})
console.log(dur1.as('minutes')) // 1440
console.log(dur1.as('seconds')) // 86400
console.log(dur1.as('milliseconds')) // 86400000
console.log(dur1.shiftTo('hours', 'minutes').toObject()) // {hours: 24, minutes: 0}
const dur2 = dur.fromObject(d1.toObject())
console.log(dur2.as('days')) // 738917.5164942129
console.log(dur2.shiftTo('weeks', 'days').toObject()) // {weeks: 105269, days: 0.5164942129629635}
const dur3 = dur.fromObject({ months: 2, weeks: 3, days: 3})
console.log(dur3.as('days')) // 84
console.log(dur3.shiftTo('weeks', 'days').toObject()) // {weeks: 11, days: 3}
console.log(dur3.shiftToAll().toObject()) // {"years":0,"months":2,"weeks":3,"days":3,"hours":0,"minutes":0,"seconds":0,"milliseconds":0}
```既然有将日期和时间换算成毫秒表示,自然也有对应的将毫秒转换成相应的对象表示形式,这里我们需要用到 rescale(): Duration 函数,使用方法如下:
```dataviewjs
const dur = dv.luxon.Duration
const dur1 = dur.fromObject({milliseconds: 86400000})
console.log(dur1.valueOf()) // 86400000
console.log(dur1.toObject()) // {milliseconds: 86400000}
console.log(dur1.rescale().toObject()) // {days: 1}
console.log(dur.fromMillis(1715245618057).toObject()) // {milliseconds: 1715245618057}
console.log(dur.fromMillis(1715245618057).rescale().toObject()) // {years: 59, months: 1, hours: 9, minutes: 6, seconds: 58, milliseconds: 55}
```总结
相较于 DQL 查询语言,使用 API 可以更灵活地处理数据,但是也不是万能的,这取决于使用者的专业能力和需求。
文章的写作周期比较长,因为这部分内容说实话还真不好写,主要受限于作者个人的实践不够,无法给出比较贴切的实例。
文章比较长,虽然极力想囊括所有 API 的用法,但还是有些过于庞大,有些地方写得太细了,有些地方写得太粗糙了。如果你发现了文章中的错误,欢迎指正。
最后,动动你发财的小手,关注,点赞一键三连,你的鼓励是我坚持下去的动力。有任何问题欢迎加作者微信(jenemy_xl)沟通交流一起成长。
参考
- luxon 3.4.4 | Documentation (moment.github.io)
- moment.github.io/luxon/demo/global.html
- 深入了解ISO 8601:日期和时间的国际标准化-CSDN博客
- JS Intl对象完整简介及在中文中的应用 « 张鑫旭-鑫空间-鑫生活 (zhangxinxu.com)
- Array.prototype.flatMap() - JavaScript | MDN (mozilla.org)
- ISO 8601 - Wikipedia
讨论
若阁下有独到的见解或新颖的想法,诚邀您在文章下方留言,与大家共同探讨。

