
Obsidian 揭秘:深入理解链接的概念及应用
Obsidian 是双链笔记应用中的佼佼者,而作为使用 Obsidian 的用户,我们有必要花点时间认真理解其概念、熟练并合理地应用到个人知识体系中。
本文旨在通过作者目前已有的知识来向广大读者分享一下自己对于 Obsidian 中「链接」的理解和使用过程中需要注意的事项。本文有部分内容来自早前写的 Obsidian达人成长之路-1-使用终极工具Dataview 释放笔记库的潜力-DQL查询语言 文章中关于链接的介绍(修订了部分文字)。
除了介绍相关概念和语法外,本文还会介绍相关的插件(如 Dataview 和 Templater)涉及链接的相关操作。
链接介绍
在文档中插入的 URL 图片地址,网页 URL 地址,我们称之为外部链接。如果在 Obsidian 文档中想要引用其它文档,或者其文档中的标题,部分段落,我们需要创建内部链接。在 Obsidian 中我们通常将内部链接称作双链或者双向链接,然后在 Obsidian 环境中我们使用链接(Link)指代内部链接,如果有特殊情况会单独说明。
在文档中创建链接的语法为 [[文档名称]],当我们输入前两个中括号后,Obsidian 界面中会弹出文档选择下拉列表,然后自动插入文档名称并补全后面的两个中括号。一个文档内部可能会引用多个外部文档的链接,同时文档也会被别的文档引用为链接,这样就行成了一个双向的链接。我们将当前文档引入的链接称之为出链(Outgoing links),如果有其它文档引用了当前文档,则将其它文档称之为反向链接(Backlinks)。
在引入其它文档内容时我们可以选择指向整个文档,也可以引用文档标题,进一步还可以引用某个段落(块),此外还可以对引用的内容指定别名。下面是 4 种链接引用方式举例,其中 x 用来指代任意符合链接规范的文本,在 Obsidian 中输入 [[ 后全是可视化操作选择,例如在选择文档后,在文档后输入 | 会加载文档内容让你选择要引用的段落。
- 链接到文档 (
[[x]]):[[Obsidian 揭秘:深入理解链接的概念及应用]] - 链接到文档中的标题 (
[[x#x]]):[[Obsidian 揭秘:深入理解链接的概念及应用#不规范链接及其副作用]] - 链接到文档中的段落 (
[x#^x]):[[Obsidian 揭秘:深入理解链接的概念及应用#^065c03]] - 链接到文档中的段落并使用别名 (
[x#^x|x]):[[Obsidian 揭秘:深入理解链接的概念及应用#^065c03|这是别名,会替换原文档名]]
下面我们以“测试文件名.md”文档为示例,并填充其内容:
---
aliases:
- 测试链接文件,
---
# 标题一
标题一的内容。
## 标题二
标题二的内容。
标题二要被引用的段落内容。现在我们在其它文档中来引入其内容:
[[测试文件名]]
[[测试文件名|测试链接文件]]
[[测试文件名#标题二]]
[[测试文件名#标题二|标题别名]]
[[测试文件名#^a9e808]]
[[测试文件名#^a9e808|块内容别名]]下面我们分别针对 Obsidian 的 3 种不同视图模式下进行链接显示效果截图:

从上面的截图中可以看出,「阅读视图」中将 # 号替换成了 > 符号。
Tip如果我们在属性中定义了
aliases,在链接中输入|时会提示文档中定义的「别名」,当然也可以自己输入其它的。
不规范链接及其副作用
Obsidian 中文档的文件名在命名时如果出现特殊字符(链接语法使用到的字符)时,会提示:“如果文件名中包含以下任何一个字符,链接将不起作用 # ^ [] |”。但是,我们仍然可以创建成功,只不过后续在插入链接时会存在编辑很多诡异的情况——比如:表格式中无法定位光标、显示错误等问题。
Tip默认情况下,Obsidian 对于文件创建命名还有一个约束条件:“文件名不能包含下列字符:*”/<>:|?”。包含提示中列举的字符都将创建失败。
在【新建】文件时 Obsidian 会自动打开一个新的选项卡,并创建名为“未命名”的新文件。同时,会将工作区显示的名称选中并获得光标焦点。
下面是正常情况下通过【资源管理器】区域左上角的【新建笔记】按钮创建的一个空白笔记。可以看到截图中有 3 处位置显示了“未命名” 字样。其中,标示记号的 2 处是可以获得焦点进行编辑的区域。
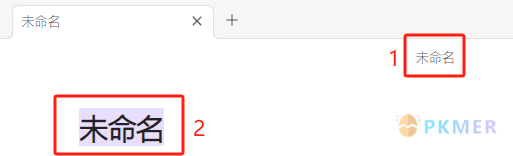
作为用户读者们有没有想过这 2 处同时都可以编辑,是否存在一些功能上的差异?这不,还真有一点小的差异——就是在遇到不规范名称时处理方式不同:
- 截图标注 1:如果出现链接语法中包含的字符会提示:如果文件名中包含以下任何一个字符,链接将不起作用 # ^ [] |。同时,当我们按下 Enter 或光标从编辑名称处跳出会自动恢复自上一次合法的命名状态。
- 截图标注 2:同样的输入,但是这里不会有任何提示,可以成功保存命名。比较有意思的是初次可以修改成功,下次再进行重命名时——显示已修改,实际关闭后再打开并没有改变(只针对已是不规范或改成不规范名称的文件,正常名称不在其列)。
此外,在【资源管理器】的目录树中鼠标聚焦到上面提到的新文件,使用上下文菜单中的【重命名】也能完成相关操作。不同点在于:它会对不符合规范的命名进行提示,同时又默认接受其修改。
上面讨论了如何创建不规范笔记的几种方式。下面,我们来看看不规范文件名对链接的影响。
文件名中带有“#”符号
作为 Obsidian 的用户,大家都清楚如何创建标签,以及标签在文档中的表示形式。但是,如果我们在创建文件时使用了不规范的文件名,比如:测试文件名 #标签:包含标签内容。在被其他笔记作为链接插入后显示成:

这明显不是我们想要的结果。
上述不规范命名对标签的影响前提是:# 号前要有一个空格。如果我们不添加这个空格,会影响吗?答案是肯定的。通过前面对链接的相关知识介绍,不难想到文件名中包含 # 号会破坏链接的“链接标题“和“链接区块”功能。
同样基于前面的示例文本,只不过我们把 # 号前的空格去掉。同时,我们在文档中插入以下内容:
# 标题
文字内容
## 标题二
文字内容二然后,作为链接被其它文档引入,编辑时尝试链接到“标题二”时:
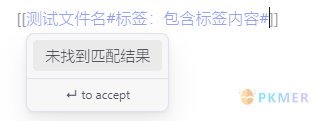
可以看到我们编辑时,“标签:包含标签内容”部分被识别成了标题,但是并不存在于文件“测试文件名”(当前仓库中并不存在)中。当我们尝试通过链接跳转至原文件时,会发现 Obsidian 为我们创建了一个名为“测试文件名”的新文档。当然,我们还是可以使用 | 符号来为链接添加显示别名,但不能使用 ^ 来指定区块——内容不存在。
文件名中带有“[”和“]”符号
现在我们来另外一个比较常见破坏链接的不规范命名场景:文件名中包含 [ 和 ]。为此,我们考虑以下多种包含特殊符号的命名场景:
[[测试文件名:左边包含链接语法的左边符号部分。测试文件名]]:右边包含链接语法的右边符号部分。测试[[文件名或测试]]文件名:内容包含部分(左或右)符号。测试[[文件]]名:内容包含完整的链接符号。[[测试]文件]名或测[试[文件名]]:内容包含完整的链接符合,但符号被文字间隔开。
下面就上述列举的情形在不同的视图模式(源码、实时预览和阅读)进行测试。测试时均采用输入 [[,然后
通过 Obsidian 提供候选文件来插入链接。
情形一:“[[测试文件名”
在文档中输入 [[ 后选择 [[测试文件名,可以看到文字“测试文件名”左边有 4 个 [ 符号,右边为 2 个 ]。
在「源码视图」中,我们通过按住 Ctrl 键,然后鼠标点击链接可以正常跳转到原文件;在「实时预览视图」中,直接点击链接就可以跳转至原文件;在「阅读视图」中,我们会发现出现了不一致的情况:
首先,第一个 [ 被作为了普通文本,另一个 [ 作为了链接的一部分。其次,点击链接跳转的是一个新创建的(名为:“[测试文件名”)的文档。
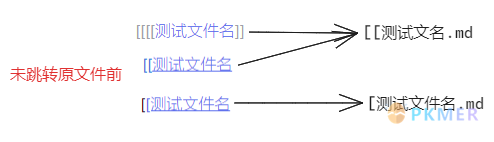
情形二:“测试文件名]]”
这种情形下,我们输入 [[ 时并选择 测试文件名]] 时会发现 Obsidian 智能地忽略了文件名中的 ]] 符号,并且在 3 种视图模式下都能正常的链接到“测试文件名”文件,而不是 “测试文件名]]”文件。虽然,行为一致了,但是毕竟跳转的文件非原文件,所以也是存在问题的。
情形三:“测试[[文件名” 或 “测试]] 文件名”
这种情形我们分成了包含链接语法开始和结束符号两部分,我们分别用 “情形①” 和 “情形②” 来指代 2 种细分情形。
Tip需要注意的是:在 Obsidian 中记录时需要对
[和]进行转义,不然标题中‘[[文件名” 或 “测试]]’会被识别成链接。
通过在不同的视图模式下测试,会发现情形①在「源码视图」和「实时预览视图」中表现一致,但在「阅读视图」中指向“文件名.md”文件,而 [[测试 成了内容的一部分。再来看一下情形②,不管是什么视图全部指向了文件“测试.md”,文件名]] 部分成了文本。
![Obsidian 揭秘:深入理解链接的概念及应用--情形三:“测试[[文件名” 或 “测试]] 文件名”](https://cdn.pkmer.cn/images/202407012039379.png!pkmer)
情形四:“测试[[文件]] 名”
这种情形下,在「源码视图」和「实时预览视图」中表现一致,但都不是原文件。而在「阅读视图」中则指向了文件“文件.md”,原来的 [[测试 和 名]] 均成了普通文本。
![Obsidian 揭秘:深入理解链接的概念及应用--情形四:“测试[[文件]] 名”](https://cdn.pkmer.cn/images/202407012039380.png!pkmer)
情形五:“[[测试] 文件] 名” 和 “测[试[文件名]]”
这种情形下,我们将其细分为:包含链接操作符前后不同的完整部分和中间插入其它字符的部分。同样,分别用 “情形①” 和 “情形②” 来指代 2 种细分情形。
情形①在「源码视图」和「实时预览视图」中表现一致(都指向“[[测试] 文件] 名.md”),而在「阅读视图」中变成了“[测试] 文件] 名.md”。情形②则 3 种视图模式下表现一致——均指向“测[试[文件名.md”文件。
![Obsidian 揭秘:深入理解链接的概念及应用--情形五:“[[测试] 文件] 名” 和 “测[试[文件名]]”](https://cdn.pkmer.cn/images/202407012039381.png!pkmer)
文件中带有“^”符号
虽然前面我们提到文件名不能包含链接语法所包含的特殊符号,但是经过测试发现:不管是 测试^文件名、^测试文件名、^测试^文件名 还是 测试文件名^ 都能成功跳转至原文件。
Dataview 中链接相关知识
有关 Dataview 的前置知识请读者查阅作者《达人成长之路系列》前 3 篇。我们这里就开门见山,直奔主题介绍相关链接的知识点。
DQL 查询语言中的链接知识
在「DQL 查询语言」中使用 FROM [[文档名]] 来查询“文档名.md”被引用的文件、使用 FROM outgoing([[文档名]]) 来查询 “文档名.md” 中引入的外部链接(包含文档、图片、PDF 等)。
Dataview 为每个文档内置了 file 对象属性——在 Obsidian 原始的 TFile 的基础上添加了诸多属性——我们只关心与链接相关的属性。
file.outlinks 数组属性表示「出链」,file.inlinks 数组属性表示「反向链接」。此外,我们还需要留意一下 aliases 属性,因为在通过脚本方式插入链接时有可能需要同时插入文档定义好的别名。
Question这里的【出链】可以理解为:出(来)自外部。【反向链接】可以理解为:反过来被引用。
下面我们以在文档“测试链接.md”中引入“测试文件名.md”和另外任意一个文档和图片(读者可自行选择自己的)为例:
%% 测试链接.md %%
[[测试文件名]]
[[测试文件名|测试链接文件]]
[[测试文件名#标题二]]
[[测试文件名#标题二|标题别名]]
[[测试文件名#^a9e808]]
[[测试文件名#^a9e808|块内容别名]]
[[The Good Doctor]]
[[Basic_Task_Queries_completion_screenshot.png]]接下来我们通过下面的脚本在另外一个新建的空白文档中来查询 ” 测试链接.md” 中所有「出链」:
```dataview
LIST join(rows.file.link, "<br>")
FROM "测试链接.md"
FLATTEN file.outlinks AS outlinks
GROUP BY outlinks
```下面是执行后的结果:

下面我们来分析一下上述结果:
- 查询的显示结果是一个二级的嵌套列表:第一级表示引入的文档(包含同一文档的 3 种不同类型);第二级表示同一文档类型被引用的次数。
- 文档中我们对每一种链接方式(分别使用默认和别名方式)引用了 2 次,实际每一种类型在结果第一级列表中只显示了一次。
- 从结果第二级列表中我们并不能获取到设置的显示别名。
接下来,我们来解决如何获取引入链接别名显示问题。
Dataview 提供了一个 meta() 函数来获取链接的元数据信息。它有以下属性:
display显示别名,没有设置则为null。embed表示链接的内容是否作为引用嵌入到文档中,即以![[]]的形式引入链接,不是则返回false值。subpath为标题或块引用 ID,这个根据链接的类型来决定。type链接的类型,其值为file/header和block,分别对应文件、标题和块区域(也可以称之为段落)。
忘记说了……前面示例的分析中所说的“第一级”列表实际上是 LIST 查询默认显示的列表 ID(实际就是链接)。我们是可以通过 LIST WITHOUT ID 将其隐藏不显示,那么剩下的就是 8 个 “测试链接” 了:

上图左边是 LIST WITHOUT ID rows.file.link 的结果,右边是 LIST WITHOUT ID join(rows.file.link, "<br>") 的结果。
Tip实际上,作者这里故意绕了半天,完全可以使用
LIST WITHOUT ID join(rows.outlinks, "<br>")直接获取最终的结果,只不过查询结果显示的是链接「阅读视图」的结果……。
——作者的目的是为了引入其它链接相关的函数。
现在我们在文档“测试链接.md”中添加一个嵌入的图片(原来的图片链接前加了一个 ! 符号)![[Basic_Task_Queries_completion_screenshot.png]]。查询语句由原来的 LIST 改成 TABLE,同时输出原始的链接和我们通过 link() 函数生成的链接:
```dataview
TABLE WITHOUT ID
join(rows.file.link, "<br>") AS 链接,
join(rows.outlinks, "<br>") AS 原始链接,
join(rows.newLink, "<br>") AS 拼接的链接
FROM "测试链接.md"
FLATTEN file.outlinks AS outlinks
FLATTEN meta(outlinks) AS metaLink
FLATTEN link(metaLink.path, metaLink.display) AS newLink
GROUP BY outlinks
```结果:
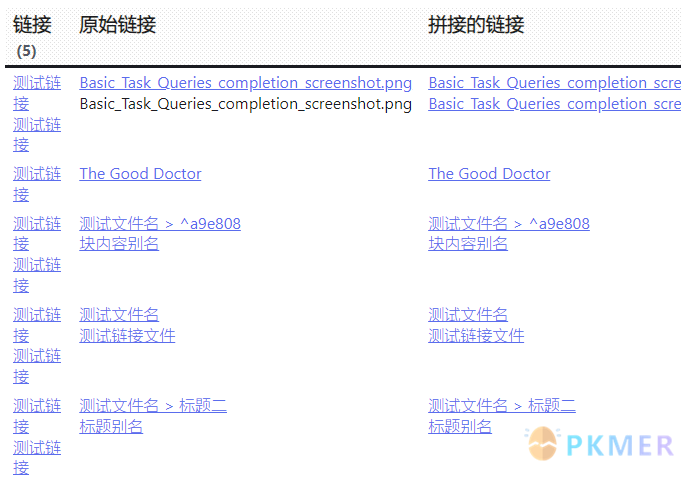
从结果来看除了嵌入的图片和 ” 原始链接 ” 对应不上外,其它都正常显示。
要实现图片链接(指 ![[]] 而非 ![]())嵌入,我们需要使用 embed() 函数,并将第 2 个参数传递 true 值。下面是改进后的实现:
```dataview
TABLE WITHOUT ID
join(rows.file.link, "<br>") AS 链接,
join(rows.outlinks, "<br>") AS 原始链接,
join(rows.newLink, "<br>") AS 拼接的链接
FROM "测试链接.md"
FLATTEN file.outlinks AS outlinks
FLATTEN meta(outlinks) AS metaLink
FLATTEN link(metaLink.path, metaLink.display) AS commonLink
FLATTEN embed(link(metaLink.path, metaLink.display), true) AS embedLink
FLATTEN choice(metaLink.embed, embedLink, commonLink) AS newLink
GROUP BY outlinks
```至此,有关「 DQL 查询语言」中所有链接相关的函数已介绍完毕。
Dataview 查询 API 中链接相关知识
使用 API 的方式,我们同样需要从 file.inlinks 和 file.outlinks 中获取链接信息——只不过我们通过 dv.list() 和 dv.table() 显示结果时,嵌入的图片不再是显示成纯文本,而是渲染成了图片。
```dataviewjs
const pages = dv.pages('"测试链接.md"')
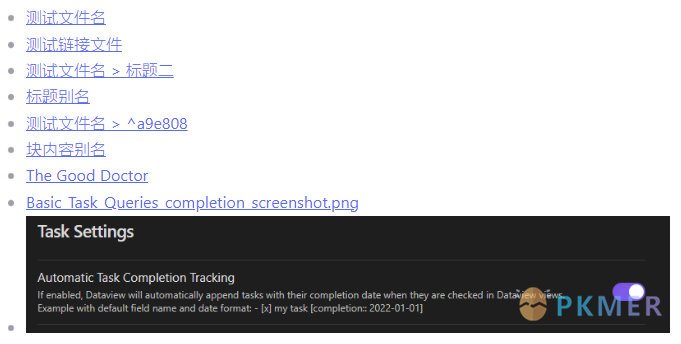
dv.list(pages.map(p => p.file.outlinks)[0])
```上面代码中,我们读取了结果数组第 1 项(因为 dv.list() 返回的是一个列表,而 outlinks 是一个数组),因为查询文档只有一个。
结果:
不同于「DQL 查询语言」,使用 API 方式,我们需要根据链接的类型来选择构建链接的函数:
dv.fileLink(path, [embed?], [display-name])普通链接。dv.sectionLink(path, section, [embed?], [display?])链接到标题。dv.blockLink(path, blockId, [embed?], [display?])链接到块区域(或叫段落)。
下面我们通过以上 3 个 API 来实现“拼接的链接”:
```dataviewjs
const pages = dv.pages('"测试链接.md"')
dv.table(['链接', '原始链接', '拼接的链接'], pages.flatMap(p => {
return p.file.outlinks.flatMap((l, i) => {
let customLink;
if (l.type === 'file') {
if (/.png$/.test(l.path) && l.embed) {
customLink = l.display
} else {
customLink = dv.fileLink(l.path, l.embed, l.display)
}
} else if (l.type === 'block') {
customLink = dv.blockLink(l.path, l.subpath, l.embed, l.display)
} else if (l.type === 'header') {
customLink = dv.sectionLink(l.path, l.subpath, l.embed, l.display)
} else {
customLink = l.path;
}
return [[p.file.link, l, customLink]]
})
}))
```结果:

上述代码中变量 l 实际上已经是一个链接 (Link) 对象了,我们这里其实直接返回就可以了。但是,为了演示 API 的用法我们额外做了一个判断来保持与「DQL 查询语言」中的结果一致。脚本中两个 flatMap() 函数用法很关键,读者可自行研究。
Templater 中链接相关知识
在 Templater 中要实现对链接的查询,我们需要使用到 Obsidian 提供的 API 来实现。
通过 app.metadataCache.resolvedLinks 属性可以获取到仓库中所有笔记中所包含的链接名称和引用次数,同时使用 app.metadataCache.unresolvedLinks 可以获取到笔记中的空链接名称和引用次数。这二个对象都是以文件的路径作为键值,以包含的链接数组作为对象值。
下面我们来获取一下在 Dataview 章节中示例文件“测试链接.md”中的链接信息,同时在文档后面追加一行:
[[不存在的链接]]然后,进行查询:
<%*
const filename = "测试链接"
const links = app.metadataCache.resolvedLinks[`${filename}.md`]
const ulinks = app.metadataCache.unresolvedLinks[`${filename}.md`]
_%>
- 已解析的链接
| 链接 | 引用次数 |
| --- | ---- |
<%* Object.keys(links).forEach(key => { _%>
| <% key %>|<% links[key] -%> |
<%* }) -%>
- 未解析的链接
| 链接 | 引用次数 |
| --- | ---- |
<%* Object.keys(ulinks).forEach(key => { _%>
| <% key %>|<% ulinks[key] -%> |
<%* }) %>结果:

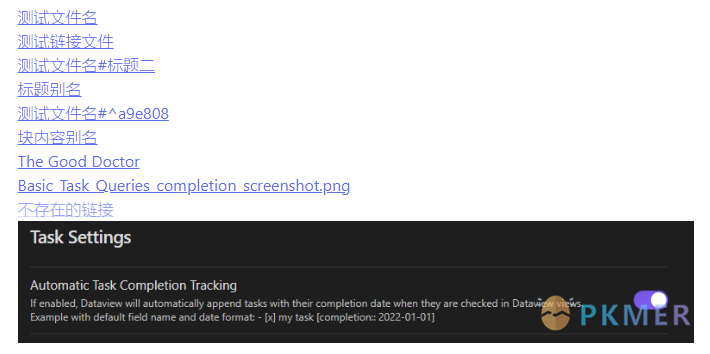
从结果可以看到:成功识别了我们添加的“[[不存在的链接]]”。
下面我们将通过 app.metadataCache.getLinks() 方法来获文档“测试链接.md”所引入的所有的链接信息:
<%*
const filename = "测试链接"
const links = app.metadataCache.getLinks()[`${filename}.md`]
_%>
<%* links.forEach(link => { -%>
<% link.original %>
<%* }) -%>
结果:
接下来,我们来做 2 件事:
- 过滤掉未解析的链接。
- 将嵌入的图片显示为纯文本。
对于「未解析的链接」,我们可以通过 2 种方式来识别。
一)使用 unresolvedLinks 对像中的数据作为参照
unresolvedLinks 返回的是链接的原始名称。因此,在处理由 getLinks() 拿到的数据时,需要进行名称匹配。getLinks() 返回的数据包含以下 3 个属性:
displayText显示的名称(通常为文件名),如果有指定别名则显示别名。link链接不包含[[和]]以及「别名」部分内容。original完整的链接原始内容。
上面 3 个属性中我们选择从 link 中获取链接的原始名称。我们需要从形如 测试文件名、测试文件名|别名 、测试文件名#标题二、测试文件名#标题二|别名、测试文件名#^a9e808 和 测试文件名#^a9e808|别名 的数据中提取出 测试文件名。由于,unresolvedLinks 对象的键值和 link 属性是一致的,这里我们只需要过滤掉 unresolvedLinks 对象中的值即可:
<%*
const filename = "测试链接"
const ulinks = Object.keys(app.metadataCache.unresolvedLinks[`${filename}.md`])
const links = app.metadataCache.getLinks()[`${filename}.md`].filter(l => !ulinks.includes(l.link))
_%>
<%* links.forEach(link => { -%>
<% link.original %>
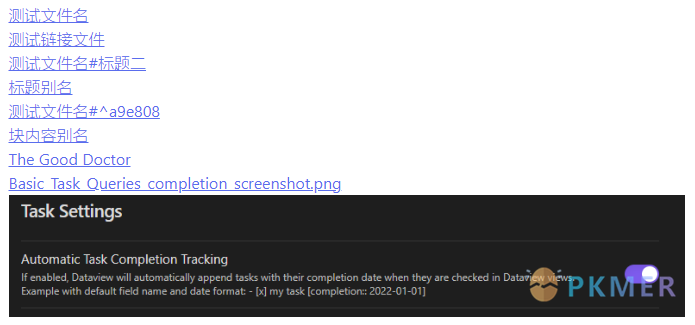
<%* }) -%>二)使用 t.file.find_tfile() 判断文件是否存在来实现
这个实现的关键点在于提取出 link 中的原始文件名并传入 t.file.find_tfile() 中。这里,我们使用正则表达式 /(.+?)(?:(#.+$)|(\|.+$)?)/gm 来匹配 link 中的文件名。此外,还需要注意脚本中的异步方式地使用。
<%*
const filename = "测试链接"
const filenameReg = /(.+?)(?:(#.+$)|(\|.+$)?)/gm
const ulinks = Object.keys(app.metadataCache.unresolvedLinks[`${filename}.md`])
let links = []
await app.metadataCache.getLinks()[`${filename}.md`].forEach(async l => {
const rawFilename = l.link.replace(filenameReg, "$1")
const tfile = await tp.file.find_tfile(rawFilename)
if (tfile) links.push(l)
})
_%>
<%* links.forEach(link => { -%>
<% link.original %>
<%* }) -%>最终结果:
现在我们来解决「图片显示成纯文本」的问题。
这里我们需要识别出图片的链接,同时还需要判断图片是否作为内容嵌入到文档中。图片(以 .png 为例)我们只需要判断 link 属性的扩展名即可;是否嵌入,则需要判断 original 属性值文本是否以 ! 作为起始文本就可以了。
由于渲染时我们是从 link.original 中获取的值,因此对于纯文本,需要将其原来的值覆盖——不然就要改渲染逻辑了。
<%*
const filename = "测试链接"
const filenameReg = /(.+?)(?:(#.+$)|(\|.+$)?)/gm
const ulinks = Object.keys(app.metadataCache.unresolvedLinks[`${filename}.md`])
let links = []
await app.metadataCache.getLinks()[`${filename}.md`].forEach(async l => {
const rawFilename = l.link.replace(filenameReg, "$1")
const tfile = await tp.file.find_tfile(rawFilename)
if (tfile) {
if (/\.png$/.test(l.link) && l.original.startsWith("!")) {
l.original = l.link
links.push(l)
} else {
links.push(l)
}
}
})
_%>
<%* links.forEach(link => { -%>
<% link.original %>
<%* }) -%>接下来,我们对已有的知识进行应用扩展,为文章增添点亮点。
为空链接创建文件
前面我们介绍了链接的多种形式,而对于「未解析的链接」或称之为「空链接」——我们不关心它所引用的标题和块内容。如果链接存在别名,我们就将其添加到属性 aliases 中;如果链接包含有路径信息,我们就创建不存在在的目录。
现在我们采用另外一种方式来获取指定文档的所有链接:使用 app.metadataCache.getFileCache(file)?.links 属性。使用 app.metadataCache.getFileCache(file) 还可以获取诸如:属性(frontmatter)、标签(tags)、块内容(blocks)、标题(headings)和嵌入资源(embeds)等内容。
这里我们还将前面的“测试链接.md”文件用 tp.config.target_file 替代,以便作用于任意目标文档。
下面直接上实现方式:
<%*
// 应用模板的目标文件
const file = tp.config.target_file
// 目标文件中的所有链接
const links = app.metadataCache.getFileCache(file)?.links || []
// 匹配链接中的文件名
const filenameReg = /(.+?)(?:(#.+$)|(\|.+$)?)/gm
// 只匹配文件的别名,不匹配标题和内容的
const fileAliasReg = /(^.+?)(?<!#.*?)(?=\|)(.+$)/gm
if (links.length > 0) {
links.forEach(async l => {
const rawFilePath = l.link.replace(filenameReg, "$1")
const rawFilename = rawFilePath.split('/').pop()
const tfile = await tp.file.find_tfile(rawFilePath)
if (!tfile) {
const folder = tp.file.folder(true)
const createdFromPath = folder === '/' ? file.name : `${folder}/${file.name}`
await tp.file.create_new(
`文件自动创建自:${createdFromPath}`,
rawFilename,
false,
rawFilePath.split('/').slice(0, -1).join('/')
)
// 延迟 200ms 后再更新文件别名
if (l.displayText !== rawFilename && fileAliasReg.test(l.original)) {
const newFile = await tp.file.find_tfile(rawFilePath)
setTimeout(async () => {
await app.fileManager.processFrontMatter(newFile, fm => {
fm.aliases = l.displayText
})
}, 200)
}
}
})
}
-%>注意:上述实现对于多个链接到同一个的链接只设置一次别名。
将文档内容关联链接
我们这里要实现的目标是对文档内容进行链接匹配,什么意思呢?——就是将文档内容中凡是文本中包含指定的文件名的全部替换成链接,如:测试文字 -> [[测试文字]]。这对于某些用户来说是很有必要的,它极大地减少了手工添加链接的时间,剩下的就只需要校验即可。当然,我们这里也不止是作用于链接,对于标签同样适用。
对于标签,作者为了方便测试,直接放置在了一个单独文档中,数据如下:
# 共产党主要将领
#刘少奇 #周恩来 #朱德 #任弼时 #邓小平 #彭德怀 #叶剑英 #杨尚昆 #李先念 #薄一波 #贺龙 #刘伯承 #林彪 #徐向前 #聂荣臻 #罗荣桓 #罗瑞卿 #左权 #粟裕 #叶挺 #吕正操 #杨得志 #杨勇 #陈毅 #张云逸 #王震 #黄克诚 #彭雪枫 #张爱萍 #杨靖宇 #赵尚志 #马本斋 #陈锡联 #陈赓 #王树声 #谭政 #许光达 #曾生
# 国民革命军方面
#蒋光鼐 #蔡廷锴 #冯玉祥 #张学良 #李宗仁 #阎锡山 #白崇禧 #厉尔康 #陈诚 #傅作义 #何应钦 #宋哲元 #孙连仲 #卫立煌 #张治中 #张自忠 #佟麟阁 #赵登禹 #戴安澜 #郝梦龄 #王铭章 #余程万 #黄光锐 #林伟俦 #司徒非 #谭邃 #谢晋元 #薛岳 #杜聿明 #郑洞国 #马占山 #高志航 #范筑先 #张发奎 #余汉谋 #李品仙 #刘湘 #胡宗南 #顾祝同 #刘峙 #唐生智 #徐永昌 #杨虎城 #蒋鼎文 #程潜 #李烈钧 #鹿钟麟 #苏炳文 #邱清泉 #张灵甫 #黄伯韬 #庞炳勋 #刘汝明 #汤恩伯 #罗卓英 #刘戡 #周至柔 #陈绍宽 #饶国华 #陈安宝 #唐淮源 #李家钰 #王耀武
# 日本战犯
#松井石根 #板垣征四郎 #武藤章 #土肥原贤二 #广田弘毅 #木村兵太郎 #梅津美治郎 #冈村宁次 #阿南惟几 #杉山元 #山下奉文 #南云忠一 #石原莞尔 #阿部规秀 #寺内寿一至于要链接的文档,作者这里就不给出了。读者可以自行去百度抗日战争相关的词条,然后复制内容,并对如条约、战役等按词条创建文档即可测试。
在实现时,我们需要考虑到词条优先级。我们这里对标签和链接名按文字长度进行排序,优先匹配长词条。
下面是完整地实现:
<%*
// 放置标签的文档,自行替换
const metaTagFile = "咨询二/标签元数据/标签"
// 放置需要链接的目录
const linkFolders = ["咨询二/重要事件"]
// 所有元数据标签
let metaTags
// 所有使用链接的关键词
let linkKeys
const fileCache = app.metadataCache.getFileCache(tp.file.find_tfile(metaTagFile))
metaTags = fileCache.tags.map(tag => tag.tag.replace(/#/, '')).sort((a, b) => b.length - a.length)
linkKeys = app.vault.getMarkdownFiles()
.filter(file => file.path.startsWith(linkFolders))
.map(file => file.basename)
.sort((a, b) => b.length - a.length)
const tfile = tp.config.target_file
const linkReg = /\[([^\]]+)\]\(([^)]+)\)/g
const tagReg = /#([^\s]+)/g
const content = await app.vault.read(tfile)
const lines = content.split('\n')
const newLines =lines.map((line, index) => {
if (!/#\s./.test(line) && line.trim() !== '') {
return replaceTag(replaceLink(line))
} else {
return line
}
})
await app.vault.modify(tfile, newLines.join('\n'))
function replaceLink(text) {
const reg =new RegExp(`(?<!(?<=\\[\\[(?:.*?)).*(?=(?:.*?)\\]\\]))(${linkKeys.join('|')})(?!(?<=\\[\\[(?:.*?)).*(?=(?:.*?)\\]\\]))`, 'gm')
return text.replace(reg, '[[$&]]')
}
function replaceTag(text) {
const reg = new RegExp(`(?<!(?<=\\[\\[(?:.*?)).*(?=(?:.*?)\\]\\]))(${metaTags.join('|')})(?!(?<=\\[\\[(?:.*?)).*(?=(?:.*?)\\]\\]))`, 'gm')
return text.replace(reg, ' #$& ')
}
_%>演示效果:

总结
本文主要介绍了链接的相关概念、在使用过程中需要规避的问题以及主流插件 Dataview 和 Templater 中相关的操作。其实,本文在写作的过程中,原本规划的内容还包含了 3 个与之相关的社区插件介绍——但是,由于相关插件部分已经归档,所以没办法(这些插件需要修复相关问题并匹配新的 Obsidian 版本)让用记在自己仓库中实践。
讨论
若阁下有独到的见解或新颖的想法,诚邀您在文章下方留言,与大家共同探讨。

