
手工打造一款 Word Copilot 应用,自己动手 DIY!(三)
想要节省每月 20 美金的 Copilot Pro 费用吗?通过自己动手 DIY 一个 Word Copilot,你可以节省高达 240 美金!本篇笔记将教你如何利用 Obsidian 和核心插件打造属于自己的 Word Copilot 应用,让你的文字处理更高效、更智能!
本内容将分成 3 篇笔记呈现
1、安装 word copilot 所需的插件,并设置好 APIkey
2、日常使用场景:如何使用 word copilot 进行内容创作
3、如何接入本地大语言模型,实现无限续杯
接下来开始的是“如何接入本地大语言模型,实现无限续杯!”的笔记内容。
一、为什么需要接入本地大语言模型
一般有以下几个原因:
1、无法正常访问 chatgpt,在某些国家或者地区受到限制
由于某些原因,导致某些国家或地区无法正常访问,需要通过魔法才能正常访问。
2、申请 openaikey 需要国外手机号绑定,以及开通 plus 会员支付问题限制
即使第一条你解决了,成功申请了 chatgpt 帐号,但是要申请 openaikey 用于接入第三方应用,比如浏览器插件或者是 obsidian 之中,也需要绑定手机号码,否则无法申请。同时,如果需要开通 plus 会员还需要使用国外卡支付,也是个问题。
3、处于对数据安全的考虑,个人或者企业隐私信息不便发送到网络上面
例如,有些企业或者个人创作者,对自己隐私数据的信息安全很在乎,不想发送到网络平台,以免有泄漏的风险。在这种情况,就需要本地大语言模型来完成执行任务。
4、在一些使用场景之下可以大幅降低使用成本
首先,目前已经有一些开源的 7B 模型可以完全胜任日常的任务。
其次,在某些应用场景,例如需要 AI 自动补全文本,或者是自动给出多条建议辅助写作等等。在这些使用状况之下,会频繁请求 API,容易遭到 openai 的限速或者限制使用。只能升级为企业用,付高额费用才能不限速和使用频率。
总之,接入本地大语言模型有其特殊的应用场景,也可以在一定程度上给用户带来降本增效的好处。当然,也是需要一些硬件要求的,请接下来继续观看。
二、什么样的硬件既可以本地跑大语言模型
推荐配置
显卡:英伟达 NVIDIA 的显卡, 8G 显存及以上。20 系或同规格专业显卡及以上。
内存:日常使用配 16G 内存。如果是长文本创作,例如写小说则内存最好 24G 及以上。
CPU:英特尔 intel 四核八线程,4 代酷睿及以上。
硬盘:固态 SSD 256G 及以上,M.2 固态加载模型会更快。
这个配置,在使用 Q5_K_M 量化模型的情况下,基本上可以发挥整机性能,内容生成的速度能拉满。
入门配置
显卡:英伟达 NVIDIA 的显卡, 6G 显存。10 系或同规格专业显卡及以上。
内存:12G 内存及以上。
CPU:英特尔 intel 四核八线程,4 代酷睿及以上。
硬盘:固态 SSD 256G 及以上,M.2 固态加载模型会更快。
这个配置,模型需要改用 Q4_K_M 量化模型,内容生成的速度也还是不错。
如果你使用的是 amd 或者 intel 的显卡,则在推理加速方面的速度为痛理论性能 N 卡的 30% 的水平及以下。
三、适合小白的模型及软件
1、简单好用的 LM Studio
本地运行大语言模型软件有好几款,经过本人使用体验下来,还是认为 LM Studio 更好用,能适配更多软件和应用。
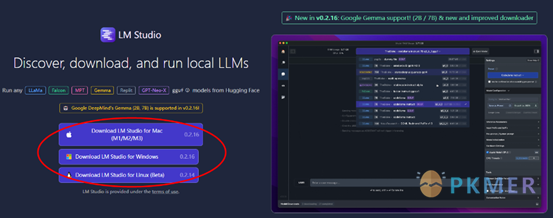
下载官方地址如下,请根据自己的电脑环境选择对应版本。
2、好用的模型
在这里给大家推荐一款好用的模型 openbuddy-zephyr-7b-v14.1 ,它是一个混合模型。其基础模型是 zephyr-7b,这个模型是由 huggingface 的 H4 团队研发的开源模型,并由国内开发人员 OpenBuddy 对模型中文化微调而成。实际使用效果还是不错。
huggingface 官方下载链接地址:
https://huggingface.co/TheBloke/openbuddy-zephyr-7B-v14.1-GGUF/tree/main
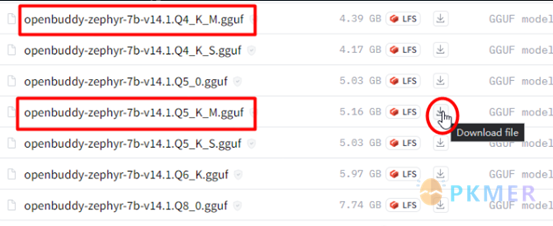
请根据前面的配置推荐,下载两个版本之一即可。Q5_K_M 量化模型是损失最小,最为推荐的。模型体积更大的 Q8_0 对硬件要求最高,输出内容的质量提升不是很明显。
四、使用 LM Studio 启用本地推理服务
1、存放模型的路径
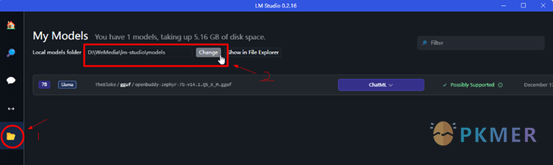
安装好后,最好最如下操作,按照步骤 1~2 如下图,修改模型存放路径,默认是保存在 C 盘,容易造成存储空间不足,建议修改到其它空余硬盘上。
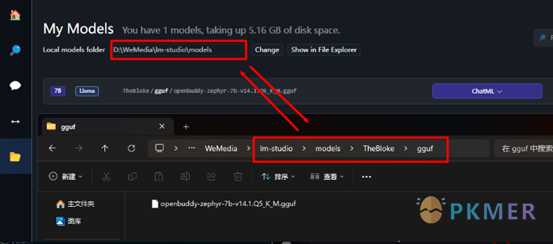
修改好后,将下载的模型存放到 TheBloke 文件夹下的 gguf 文件夹,如下图。
2、启用本地推理服务
按照下图 1~6 步骤一次点击操作或修改,即可完成设置。
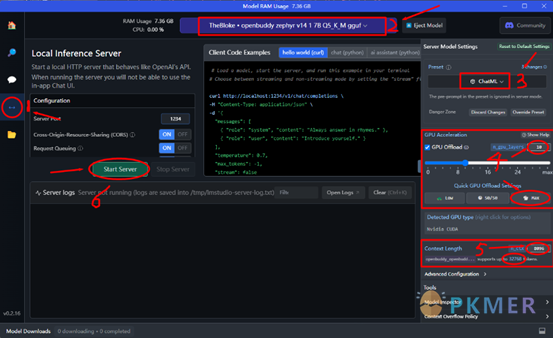
步骤 1:切换至本地推理服务
步骤 2:切换模型,选择之前存放模型
步骤 3:切换预设为 Chatml,这个生成的内容质量最好
步骤 4:设置显卡加速
首先,切换显卡类型为英伟达 Nvidia cuda,一般会自动检测,如果不是鼠标右键在弹出菜单中选择切换。
然后,在 max 位置可以手动输入数值,一般输入 32 即可,或者是点击下方“Max”按钮自动填入。一般,8g 显存使用 7b 的 Q5_K_M 的量化模型能够设置 32,速度最大化。如果你的显存 12g 可以尝试设置 48 或者 64,此时每秒生成的字节数是 50 个,已经是最块速度,设置再高也不会有提升。
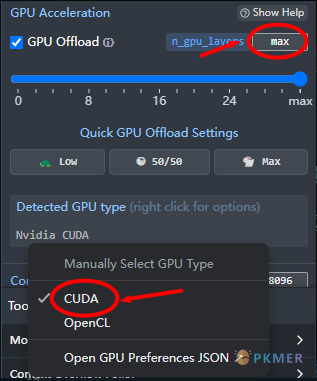
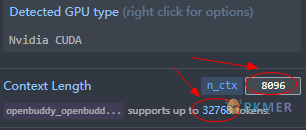
步骤 5:设置上下文的长度
默认设置为 8K,即如图所示的 8096,即可满足日常需要,最大设置不能超过模型支持的长度,如本模型支持最大为 32768 也即是 32K 上下文。如果你需要创作小说这类长文本可以设置的大一些,但是需要的显存和内存要求也会越高。这个需要根据自己的需求慢慢调试,选择一个最优的结果。
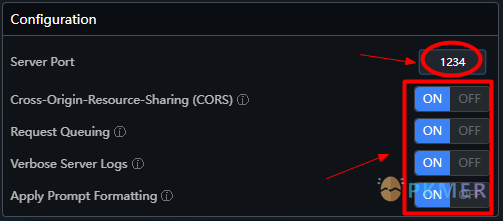
步骤 6:确认服务端口
请确认服务端口,默认是 1234 不要修改,下面的设置都打开,然后点击 “Start Server” 按钮启动服务。
经过上面的设置后, LM Studio 启用本地推理服务就完成了。
五、插件中使用 LM Studio 本地推理服务
1、Text Generator 插件设置修改
打开插件修改页面只需修改服务器地址
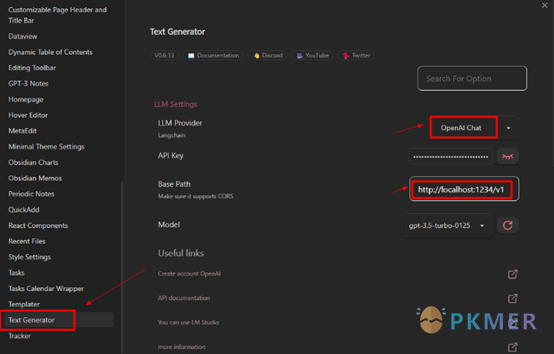
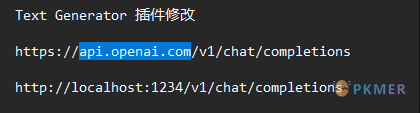
只需要将api.openai.com,修改成本地服务地址 localhost:1234 即可。
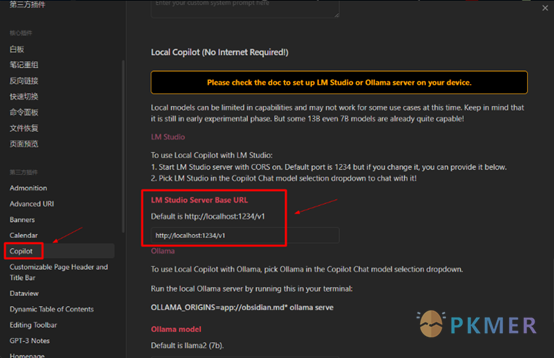
2、Copilot 插件设置修改
Copilot 插件默认是设置好的,如果你使用的不是默认 1234 端口,则在这里需要设置与 LM Studio 中的端口号一致。
3、元神开始启动
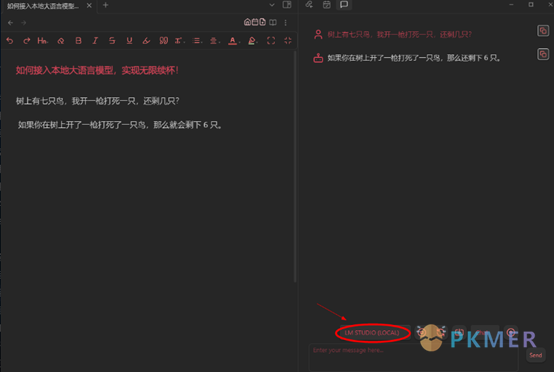
以上都设置完成后,就可以返回到页面之中开始 AI 无限续杯!再也不用担心我,AI 使用额度不够了。
Copilot 需要在对话模式下切换模型至“LM STUDIO (LOCAL)”,如下图。
总结
到此,纯手工打造一款属于自己的 Word Copilot 应用就算完工了。它能让你的文字处理更高效、更智能!如果你只是用于 word 办公,这款应用相比较微软的 Copilot Pro,每年可以帮你节省最高达 240 美金!有这个钱,给家人吃个大餐不香吗!
由于篇幅限制,笔记中有细节不足之处,请参考阅读其他 UP 主的教程。也可以在评论区回复,如果关注的人多,可以出视频在详细讲解。
讨论
若阁下有独到的见解或新颖的想法,诚邀您在文章下方留言,与大家共同探讨。

