
硬核工作流:实现以图搜图
引言:话题的开始
想提出一个观点,那就是以图片为中心的文献管理方式,每篇文献平均也就 10 张图,能看懂这 10 张图,这篇文献自然就看懂了。
👉 可以参考钟澄教授的方法
- 提醒事项
本文主要介绍实现这个工作流程的一些方法和思路,仅供参考,不为流程的细节 (包括 Python 环境配置,Quicker 动作制作) 做过多的描述。
提取 PDF 图片的方法
PP-Structure
Python 可以采用 PP-Structure 的文档分析系统,完成版面分析实现提取 PDF 中图片的功能
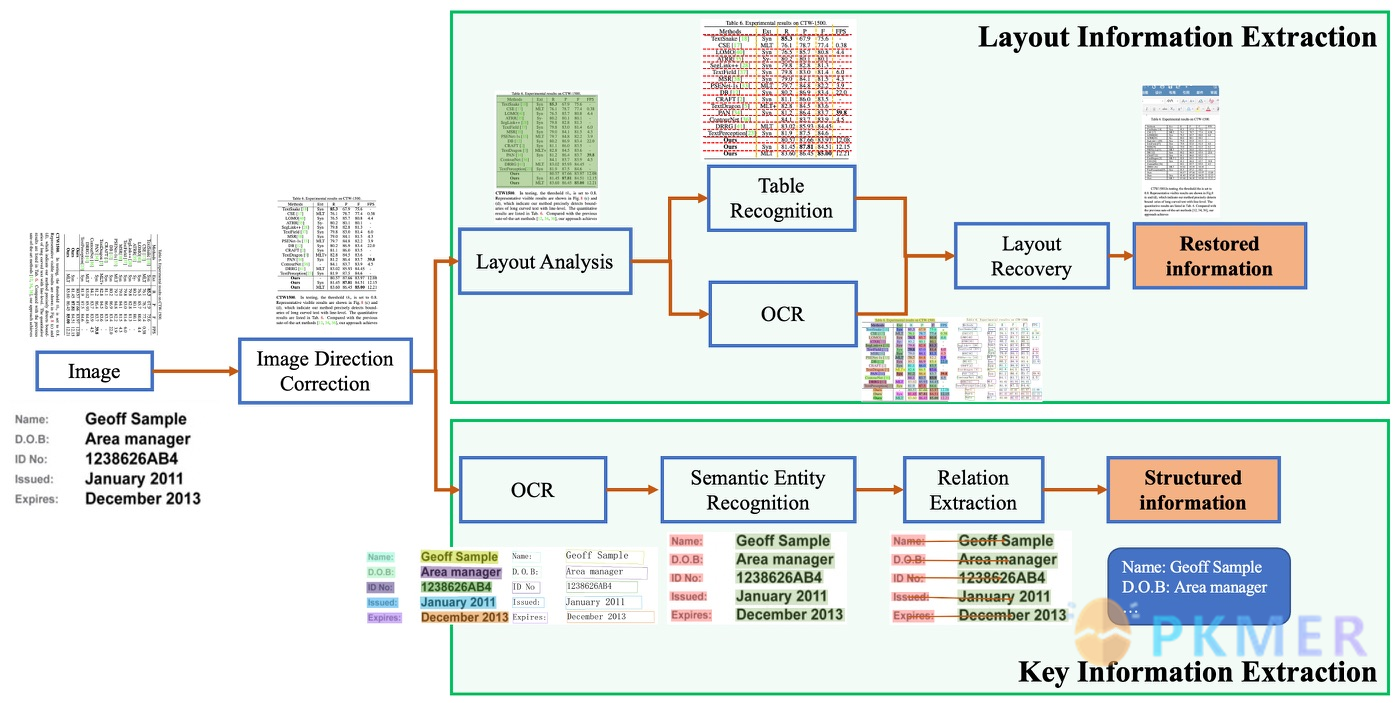

模型的设置:
model = lp.PaddleDetectionLayoutModel(config_path="lp://PubLayNet/ppyolov2_r50vd_dcn_365e_publaynet/config",
threshold=0.5,
label_map={0: "Text", 1: "Title",
2: "List", 3: "Table", 4: "Figure"},
enforce_cpu=True,
enable_mkldnn=True)为了更快的提取 PDF 图片,可以关闭 table 和 layout 以及 show_log
table_engine = PPStructure(table=False, ocr=False, show_log=False)管理图片的方法
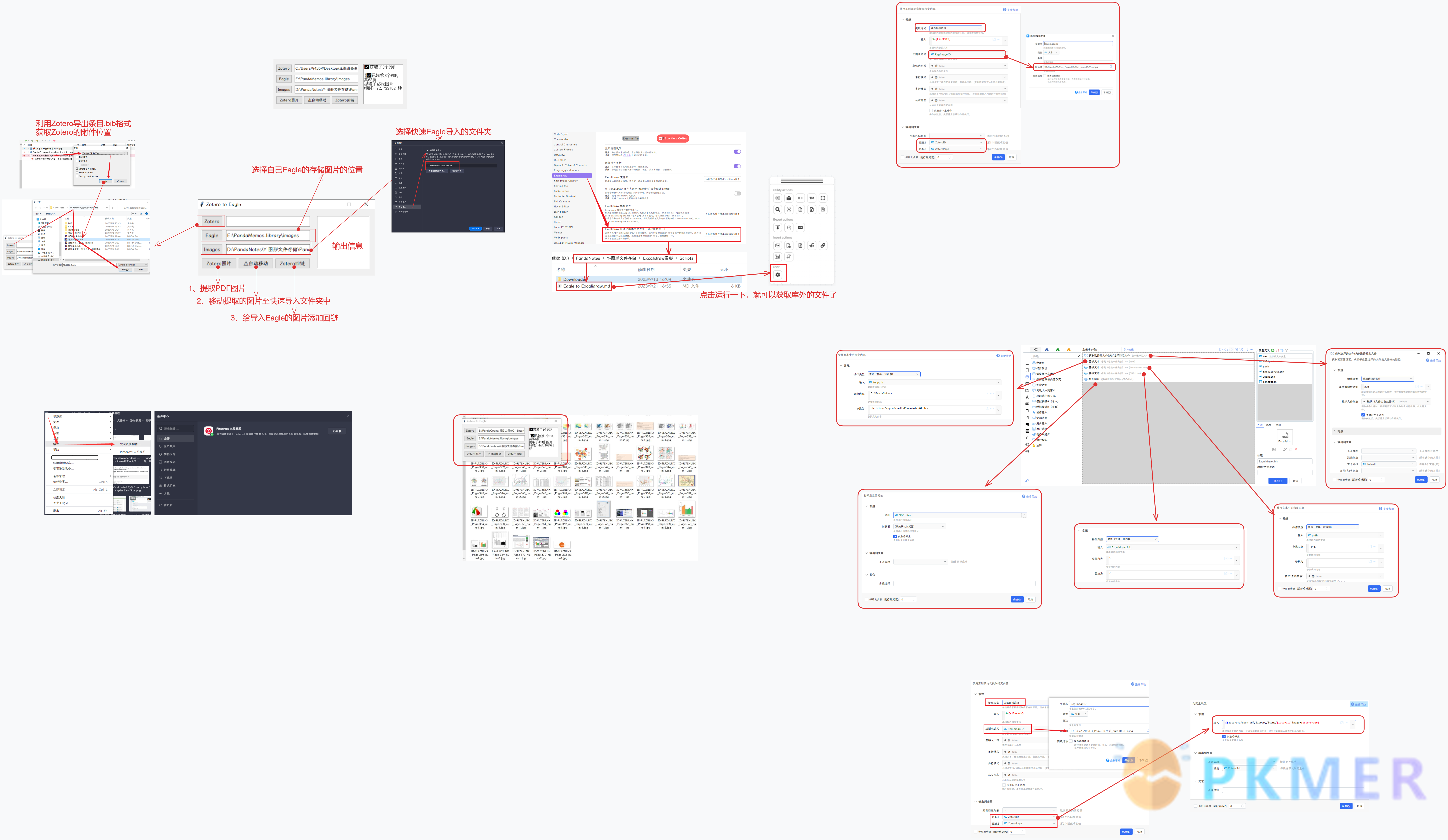
在说管理图片的方法之前,额外提一下文献的管理工具,首先提取 PDF 的前提是你要有自己一套良好的文献管理库,笔者 (熊猫) 主要用到的文献管理的工具是 Zotero,所以具体实施对象是 Zotero 中的 PDF,主要给该方法一个参考案例。
实现的效果就是可以通过图片来定位到 Zotero 具体 PDF 的图片所在的页面上。
如何自定义需要提取的 Zotero 中的 PDF?
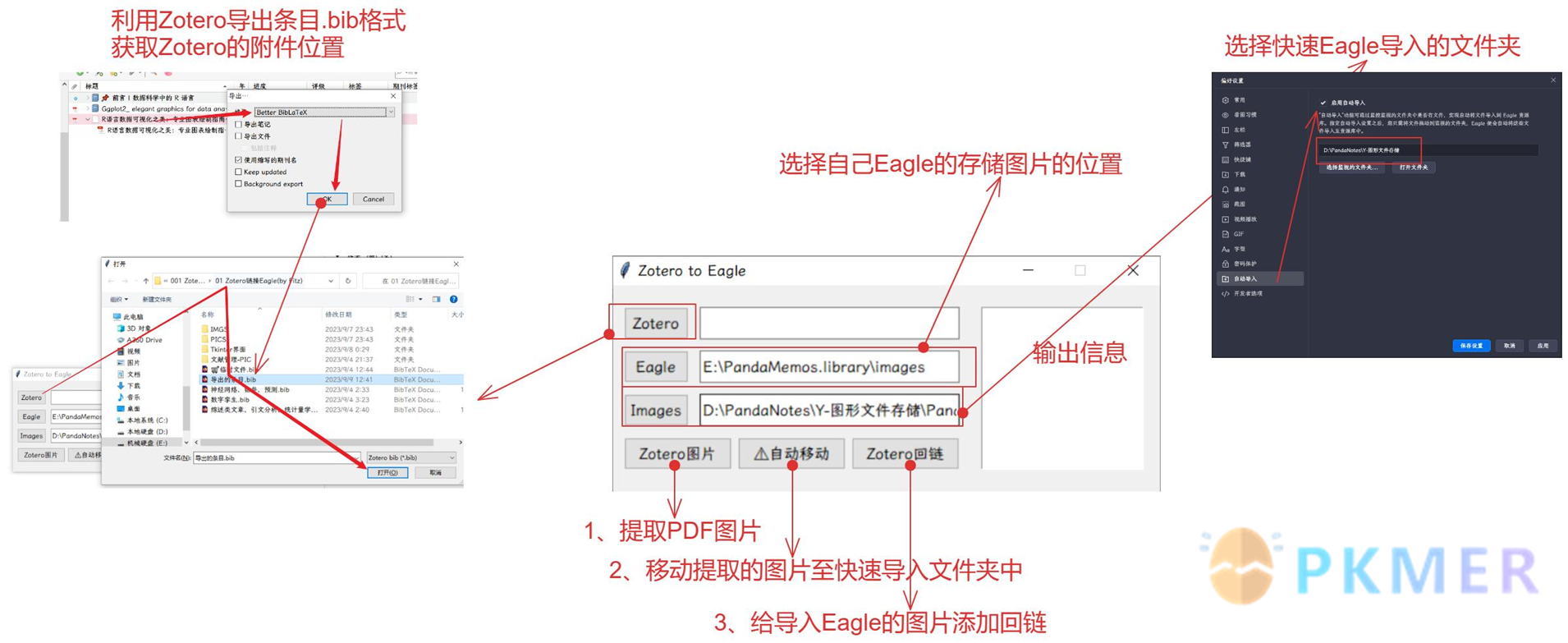
关于这一点其实非常好实现,相信很多人导出过条目吧,我就是通过就是通过导出条目来进行定位的,用的是 Better BibTex 插件的导出格式 Better BibLateX,具体选项如下:
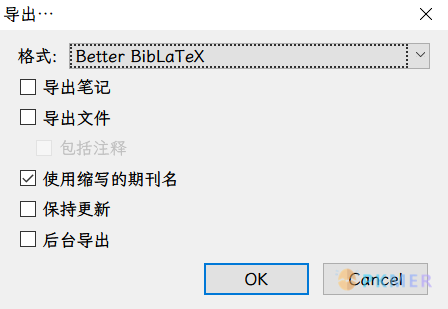
注意不要选择导出文件的选项,这样会定位不到 Zotero 中 PDF 的文件夹名称的,导出的 bib 格式如下:
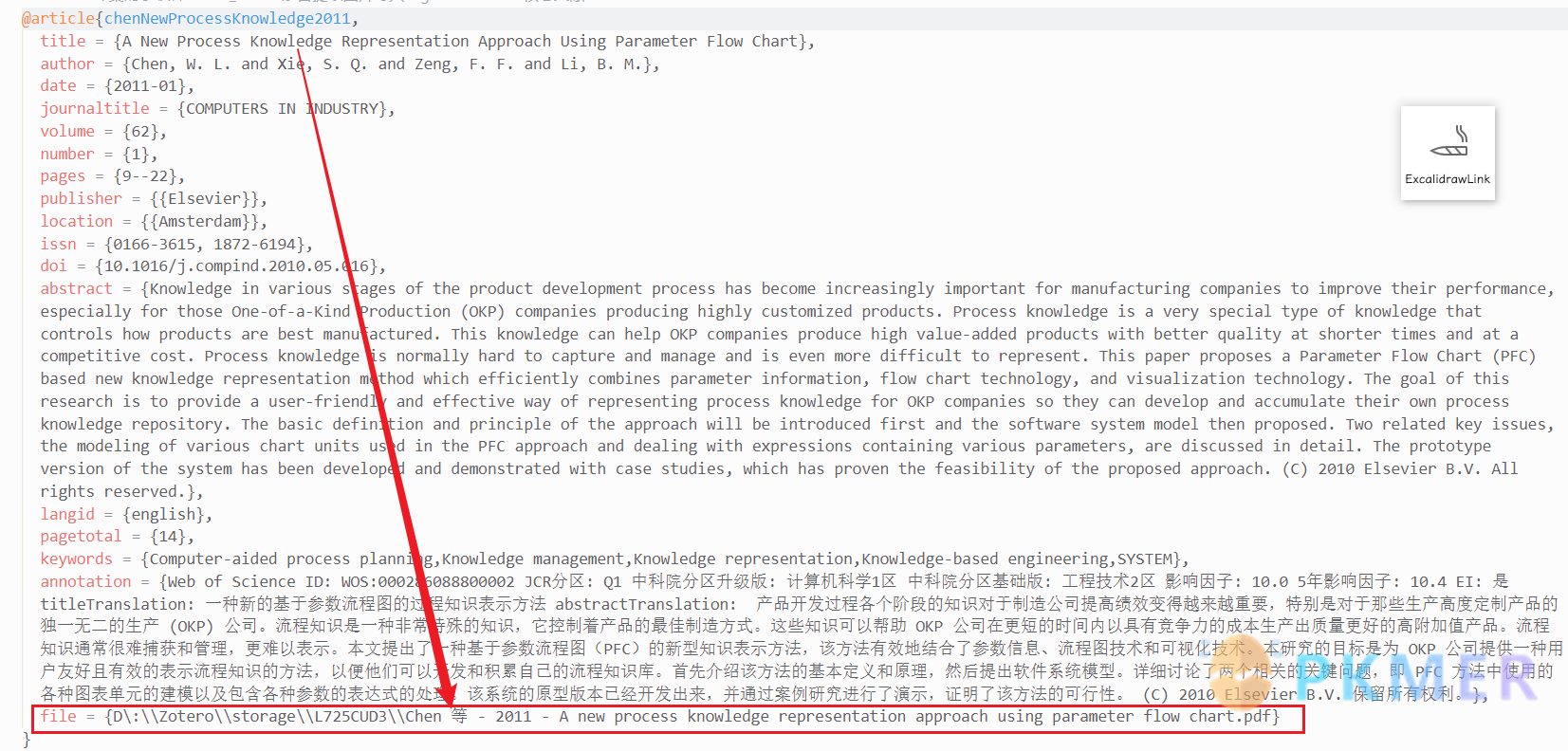
也就是可以通过导出的 bib 文件来定位到你想要的 PDF 以及文件夹。
如何管理提取的文献图片?
目前有 2 款比较好用的图片素材管理工具:Billfish、Eagle,这两款软件都是不错的素材管理软件,可以自行考虑使用。
可以根据它们强大的标签和分类功能,对图片素材整理和归类,创建自己的图片素材库。
如何通过图片跳转到 PDF?
在社区文章 通过 Python 脚本实现 Eagle 管理 Zotero 标注的图片 中介绍了 Zotero 回链的组成,以及如何用 Eagle 管理 Zotero 标注的图片。
同时我们知道了 Zotero 对应图片的的外部回链的形式,就可以通过提取的图片来定位到 Zotero 的 PDF 的某一页的。
所以采用 Zotero 链接图片的回链有:
- PDF 存放的文件夹名称对应图片链接
zotero://open-pdf/library/items/{folder_name}?page={pdf_page}{folder_name}是存放 PDF 的文件夹名称,{pdf_page}是图片所在的 PDF 的页码
如果以特定的标识符命名图片,那只要知道图片名或者获取图片名重新组合成为一个 Zotero 回链的话就可以进行跳转了。
如我设定图片的名称为:ID-{folder_name}_Page-{pdf_page}_num-{num},这里的 num 是每页提取的图片数量的计数,并没有太大作用,主要是防止图片覆盖掉。
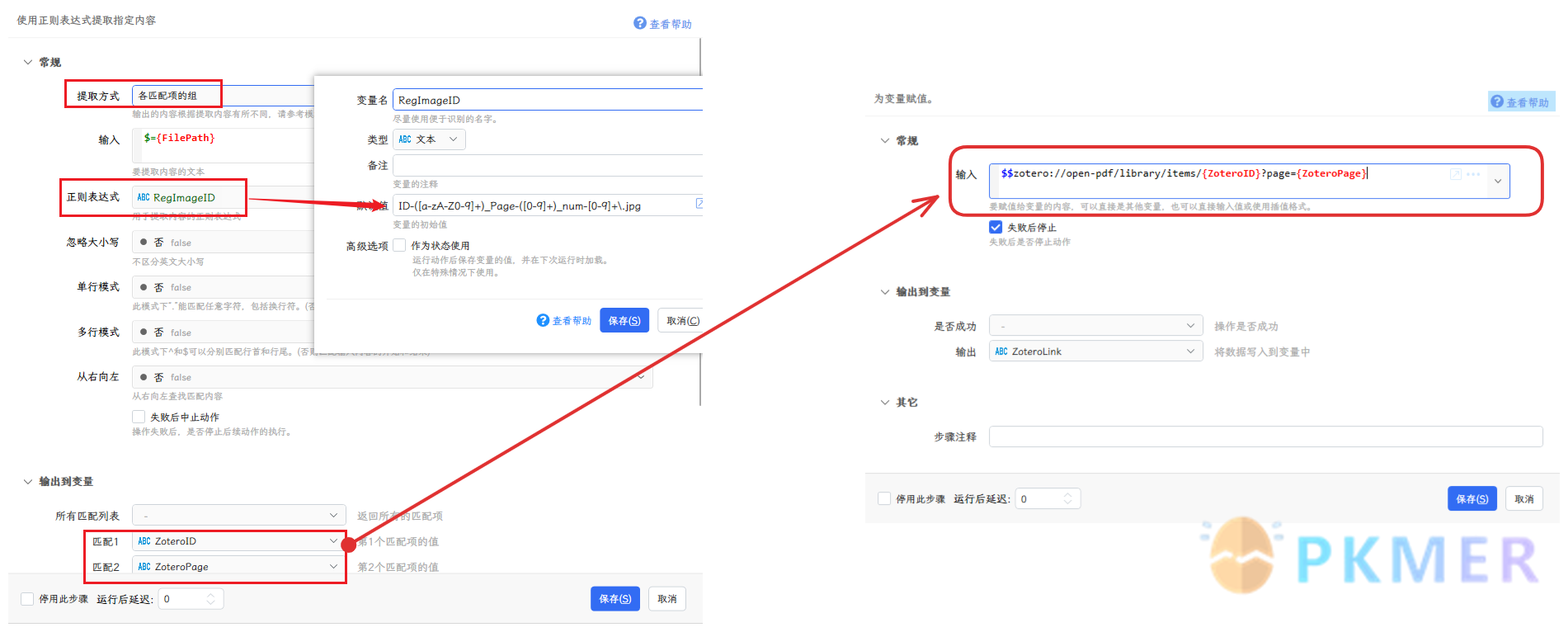
针对 Billfish 或者 Eagle,可以使用 Quicker 来达到自动组合连接并打开的快捷方式:

该动作主要负责重组选中的图片的文件名,转换为 Zotero 的外部回链,然后设置该动作的快捷方法就行了。
当然管理的图片还分为提取的图片和手动摘录的图片,两者的回链组成不一样,所以提取方法也就不一样了,所以该动作还会根据图片是否为提取或者摘录的图片做了一个判断过程。

Eagle 的图片信息都保存在了素材文件的下 metadata.json 文件中了
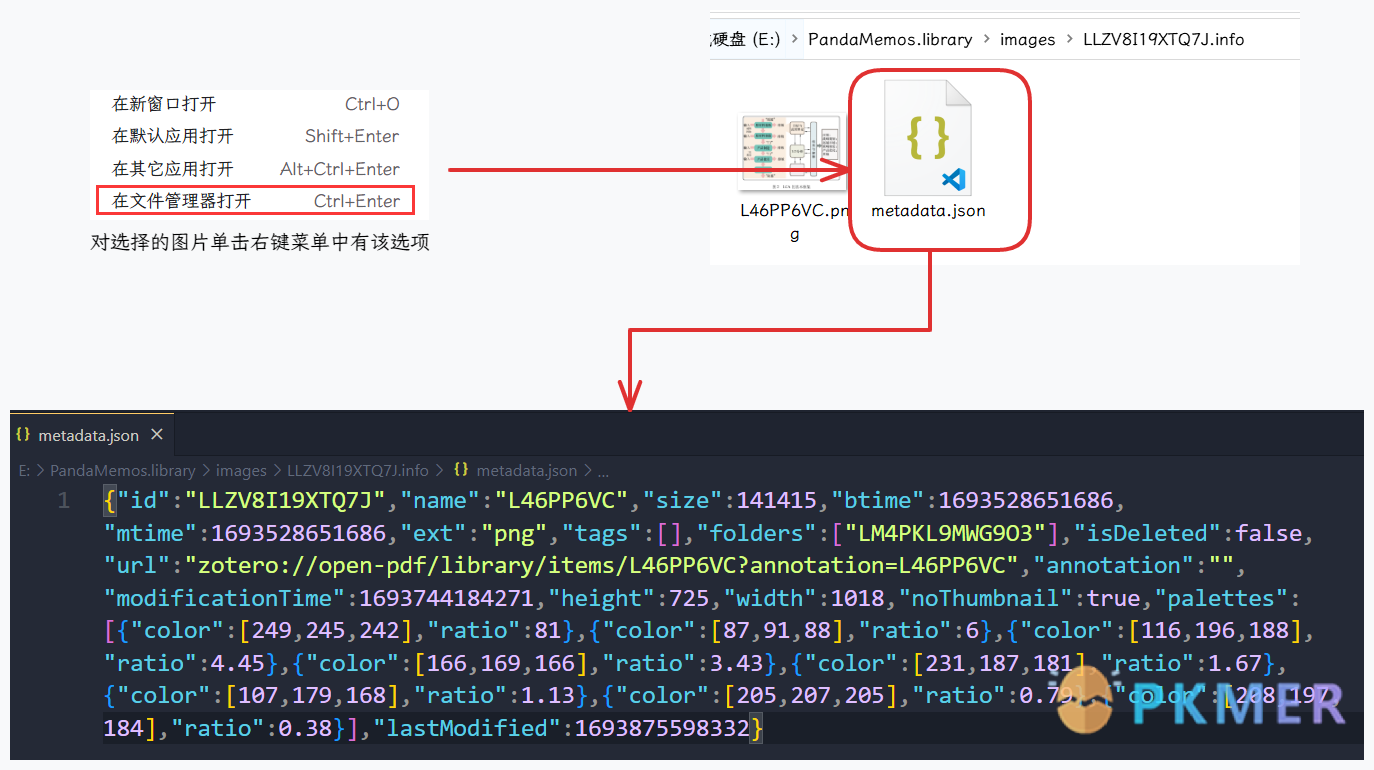
提取 Zotero 文献图片的完整 Python 脚本代码 (仅供参考使用)
这里我用 Tkinter 简单做了一个界面,关于提取 Zotero 的图片到 Eagle 的,里面的一些第三方库需要您手动下载,PPStructure 第一次使用需要下载一些包,之后就不需要下载了:
改代码仅供参考使用,具体工作流程请自行修改。
# -*- coding: utf-8 -*-
"""
Created on Fri Sep 1 07:21:40 2023
@author: 熊猫别熬夜
"""
from tkinter import *
from tkinter.ttk import *
from tkinter import ttk, filedialog
from typing import Dict
import bibtexparser
import os
import fitz
import shutil
import re
from wand.image import Image as ImageJPX
from PIL import Image
import json
import subprocess
from paddleocr import PPStructure, save_structure_res
import datetime
import warnings
import cv2
import layoutparser as lp
warnings.simplefilter("ignore")
# 配置环境变量
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
model = lp.PaddleDetectionLayoutModel(config_path="lp://PubLayNet/ppyolov2_r50vd_dcn_365e_publaynet/config",
threshold=0.5,
label_map={0: "Text", 1: "Title",
2: "List", 3: "Table", 4: "Figure"},
enforce_cpu=True,
enable_mkldnn=True)
class WinGUI(Tk):
def __init__(self):
super().__init__()
self.__win()
self.tk_input_ZoteroPath = self.__tk_input_ZoteroPath(self)
self.tk_input_EaglePath = self.__tk_input_EaglePath(self)
self.tk_button_zotero = self.__tk_button_zotero(self)
self.tk_button_Eagle = self.__tk_button_Eagle(self)
self.tk_check_button_move_files = self.__tk_check_button_move_files(
self)
self.tk_button_add_ZoteroURL = self.__tk_button_add_ZoteroURL(self)
self.tk_input_lm3k6yb9 = self.__tk_input_lm3k6yb9(self)
self.tk_button_Images = self.__tk_button_Images(self)
self.tk_button_lm3lxend = self.__tk_button_lm3lxend(self)
self.tk_input_message = self.__tk_input_message(self)
def __win(self):
self.title("Zotero to Eagle")
# 设置窗口大小、居中
width = 505
height = 190
screenwidth = self.winfo_screenwidth()
screenheight = self.winfo_screenheight()
geometry = '%dx%d+%d+%d' % (width, height,
(screenwidth - width) / 2, (screenheight - height) / 2)
self.geometry(geometry)
self.resizable(width=False, height=False)
# 自动隐藏滚动条
def scrollbar_autohide(self, bar, widget):
self.__scrollbar_hide(bar, widget)
widget.bind("", lambda e: self.__scrollbar_show(bar, widget))
bar.bind("", lambda e: self.__scrollbar_show(bar, widget))
widget.bind("", lambda e: self.__scrollbar_hide(bar, widget))
bar.bind("", lambda e: self.__scrollbar_hide(bar, widget))
def __scrollbar_show(self, bar, widget):
bar.lift(widget)
def __scrollbar_hide(self, bar, widget):
bar.lower(widget)
def vbar(self, ele, x, y, w, h, parent):
sw = 15 # Scrollbar 宽度
x = x + w - sw
vbar = Scrollbar(parent)
ele.configure(yscrollcommand=vbar.set)
vbar.config(command=ele.yview)
vbar.place(x=x, y=y, width=sw, height=h)
self.scrollbar_autohide(vbar, ele)
def __tk_input_ZoteroPath(self, parent):
ipt = Entry(parent, )
ipt.place(x=80, y=20, width=240, height=30)
return ipt
def __tk_input_EaglePath(self, parent):
ipt = Entry(parent, )
ipt.insert(0, "E:\PandaMemos.library\images") # 设置初始值
ipt.place(x=80, y=60, width=240, height=30)
return ipt
def __tk_button_zotero(self, parent):
def select_bib():
# 打开文件对话框,选择PDF文件
file_path = filedialog.askopenfilename(
filetypes=[("Zotero bib", "*.bib")])
if file_path:
# 获取选择的文件路径
self.tk_input_ZoteroPath.delete(0, END) # 清空文本框内容
self.tk_input_ZoteroPath.insert(0, file_path) # 设置文本框内容为文件路径
bibtex_file_path = file_path
self.pdf_path_list = get_pdf_paths_from_bibtex(
bibtex_file_path)
self.tk_input_message.delete('1.0', END) # 清空文本框内容
self.tk_input_message.insert(
'1.0', "✅获取了%d个PDF\n\n" % (len(self.pdf_path_list)))
btn = Button(parent, text="Zotero", takefocus=False,
command=select_bib)
btn.place(x=10, y=20, width=60, height=30)
return btn
def __tk_button_Eagle(self, parent):
def select_folder():
folder_path = filedialog.askdirectory(
initialdir="E:\PandaMemos.library\images")
if folder_path:
self.tk_input_EaglePath.delete(0, END) # 清空文本框内容
self.tk_input_EaglePath.insert(0, folder_path) # 设置文本框内容为文件夹路径
btn = Button(parent, text="Eagle", takefocus=False,
command=select_folder)
btn = Button(parent, text="Eagle", takefocus=False,)
btn.place(x=10, y=60, width=60, height=30)
return btn
def __tk_check_button_move_files(self, parent):
def on_button_click():
target_folder = self.tk_input_lm3k6yb9.get() # 获取tk_input_lm3k6yb9输入框中的路径
if target_folder:
# 调用move_files函数,并传递target_folder作为参数
move_files(target_folder)
self.tk_input_message.insert('end', "✅图片导入完成\n\n")
else:
self.tk_input_message.insert('end', "❌请输入目标文件夹路径\n\n")
btn = Button(parent, text="⚠自动移动", takefocus=False,
command=on_button_click)
btn.place(x=115, y=140, width=100, height=30)
return btn
def __tk_button_add_ZoteroURL(self, parent):
def mod_metadat():
destination_folder = self.tk_input_EaglePath.get()
mod_Eagle_metadata_to_Zotero_url(destination_folder)
self.tk_input_message.insert('end', f"✅已添加Zotero回链\n\n")
pass
btn = Button(parent, text="Zotero回链",
takefocus=False, command=mod_metadat)
btn.place(x=220, y=140, width=100, height=30)
return btn
def __tk_input_lm3k6yb9(self, parent):
ipt = Entry(parent, )
ipt.insert(0, "D:\PandaNotes\Y-图形文件存储\PandaMemos") # 设置初始值
ipt.place(x=80, y=100, width=240, height=30)
return ipt
def __tk_button_Images(self, parent):
def select_folder():
folder_path = filedialog.askdirectory(
initialdir="D:\PandaNotes\Y-图形文件存储\PandaMemos")
if folder_path:
self.tk_input_lm3k6yb9.delete(0, END) # 清空文本框内容
self.tk_input_lm3k6yb9.insert(0, folder_path) # 设置文本框内容为文件夹路径
btn = Button(parent, text="Images",
takefocus=False, command=select_folder)
btn.place(x=10, y=100, width=60, height=30)
return btn
def __tk_button_lm3lxend(self, parent):
def extract_pdf_paths():
text = Zotero_images(self.pdf_path_list)
# self.tk_input_message.delete(0, END) # 清空文本框内容
self.tk_input_message.insert('end', text)
# 获取当前程序路径
current_path = os.getcwd()
# 要打开的文件夹路径
folder_path = os.path.join(current_path, "IMGS")
# 在命令行中打开文件夹
subprocess.run(["start", folder_path], shell=True)
btn = Button(parent, text="Zotero图片",
takefocus=False, command=extract_pdf_paths)
btn.place(x=10, y=140, width=100, height=30)
return btn
def __tk_input_message(self, parent):
ipt = Text(parent)
ipt.place(x=340, y=20, width=150, height=150)
return ipt
def extract_id_and_page(pdf_path):
# 获取Zotero_url和page
pattern = r"ID-(.*?)_Page-(\d+)_num"
match = re.search(pattern, pdf_path)
if match:
id = match.group(1)
page = match.group(2)
return id, page
else:
return None, None
def get_pdf_paths_from_bibtex(bibtex_file_path):
# 从bib中导入数据
pdf_path_list = []
with open(bibtex_file_path, 'r', encoding="utf-8") as bibtex_file:
bib_database = bibtexparser.load(bibtex_file)
for entry in bib_database.entries:
try:
if "file" in entry:
pdf_path = entry["file"].split(";")[0].replace(
"\\\\", "\\").replace("\\:", ":")
if os.path.exists(pdf_path) and (pdf_path.lower().endswith('.pdf')):
pdf_path_list.append(pdf_path)
else:
print(f"❌ PDF文件不存在或不是有效的PDF文件: {pdf_path}")
except Exception as e:
print(f"❌ 提取PDF文件路径时出错: {e}")
return pdf_path_list
def rename_and_disperse(foldername):
# 获取文件夹下的所有子文件夹
subfolders = [f.path for f in os.scandir(foldername) if f.is_dir()]
# 对每个子文件夹进行处理
for subfolder in subfolders:
# 获取子文件夹的名称
subfolder_name = os.path.basename(subfolder)
# 获取子文件夹下的所有图片文件
image_files = [f for f in os.listdir(subfolder) if f.endswith((".jpg", ".jpeg", ".png"))]
# 对图片文件进行重新命名
for i, image_file in enumerate(image_files):
name, ext = os.path.splitext(image_file)
new_name = f"{subfolder_name}_num-{i+1}{ext}"
os.rename(os.path.join(subfolder, image_file), os.path.join(subfolder, new_name))
# 移动图片文件到父文件夹
src = os.path.join(subfolder, new_name)
dst = foldername
try:
shutil.move(src, dst)
except:
print("跳过已存在的图片")
pass
# 删除子文件夹
shutil.rmtree(subfolder)
# 提取图片
def process_images(img_dir, save_folder):
# 设置提取的引擎
image_engine = PPStructure(table=False, ocr=False, layout=True, show_log=False)
if not os.path.exists(save_folder):
os.makedirs(save_folder)
files = os.listdir(img_dir)
for fi in files:
img_path = os.path.join(img_dir, fi)
# img_path = os.path.normpath(img_path)
img = cv2.imread(img_path)
# encoded_path = img_path.encode('utf-8')
# img = cv2.imread(encoded_path.decode('utf-8'))
result = image_engine(img)
save_structure_res(result, save_folder, os.path.basename(img_path).split('.')[0])
rename_and_disperse(save_folder)
# print('🥏',fi)
return len(files)
# 单个pdf提取
def pyMuPDF_fitz(pdfPath, imagePath):
# print("imagePath=" + imagePath)
pdfDoc = fitz.open(pdfPath)
pdf_filename=os.path.basename(pdfPath).split(".pdf")[0]
for pageIndex in range(pdfDoc.page_count):
page = pdfDoc[pageIndex]
rotate = int(0)
# 每个尺寸的缩放系数为4,这将为我们生成分辨率提高4的图像。
# 此处若是不做设置,默认图片大小为:792X612, dpi=96
zoom_x = 4 # (1.33333333-->1056x816) (2-->1584x1224)
zoom_y = 4
mat = fitz.Matrix(zoom_x, zoom_y).prerotate(rotate)
pix = page.get_pixmap(matrix=mat, alpha=False)
if not os.path.exists(imagePath): # 判断存放图片的文件夹是否存在
os.makedirs(imagePath) # 若图片文件夹不存在就创建
# print(pdf_filename)
parent_dir = os.path.dirname(pdfPath)
ZoteroID = os.path.basename(parent_dir)
# 将图片写入指定的文件夹内
# pix.save(imagePath + '/' + f'{pdf_filename} ID:{ZoteroID} Page:{pageIndex+1}.png')
pix.save(imagePath + '/' + f'ID-{ZoteroID}_Page-{pageIndex+1}.png')
# 批量pdf提取
def Zotero_images(filepaths,n=False):
startTime = datetime.datetime.now() # 开始时间
page_nums=0;
for fi in filepaths:
if n:
# 将转换的图片保存到对应imgs的对应子目录下
pyMuPDF_fitz(fi, os.path.join('MIGS', fi[:-4]))
# img_dir = './IMGS'
# save_folder = './PICS'
# process_images(img_dir, save_folder)
else:
startTime_pdf2img = datetime.datetime.now() # 开始时间
# 将图片生成在程序文件夹下
img_dir = './IMGS'
save_folder = './PICS'
pyMuPDF_fitz(fi, img_dir)
page_num=process_images(img_dir, save_folder)
page_nums+=page_num
# 删除并重建文件进行清空变量
shutil.rmtree(img_dir)
os.makedirs(img_dir)
endTime_pdf2img = datetime.datetime.now() # 结束时间
print('🥏耗时', (endTime_pdf2img - startTime_pdf2img).seconds,'秒',f"{fi}")
endTime = datetime.datetime.now() # 结束时间
files = os.listdir(save_folder)
text=f'✅已转换{len(filepaths)}个PDF,共{page_nums}页\n提取了{len(files)}张图片\n耗时', (endTime - startTime).total_seconds(),'秒'
print(text)
return text
# 添加回链
def mod_Eagle_metadata_to_Zotero_url(destination_folder):
# # 遍历目标文件夹及其子文件夹
i = 0
for root, dirs, files in os.walk(destination_folder):
for filename in files:
# 检查文件扩展名是否为PNG
if filename.endswith(".png") or filename.endswith(".jpg"):
# 构建目标文件的完整路径
destination_file = os.path.join(root, filename)
metadata_file = os.path.join(root, "metadata.json")
# 读取metadata.json文件
with open(metadata_file, "r", encoding="utf-8") as file:
data = json.load(file)
ZoteroID, pageIndex = extract_id_and_page(filename)
if ZoteroID and pageIndex:
zotero_url = f"zotero://open-pdf/library/items/{ZoteroID}?page={pageIndex}"
print(filename)
data["url"] = zotero_url
i = i+1
# 写入修改后的数据到metadata.json文件
with open(metadata_file, "w", encoding="utf-8") as file:
json.dump(data, file)
print(f"✅总计修改了{i}个metadata")
print("✅程序执行完成")
def move_files(target_folder):
# 获取源文件夹内的所有文件名
source_folder = "./PICS"
file_names = os.listdir(source_folder)
# 遍历文件名列表
for file_name in file_names:
# 构建源文件的完整路径
source_path = os.path.join(source_folder, file_name)
# 构建目标文件的完整路径
target_path = os.path.join(target_folder, file_name)
# 移动文件
shutil.move(source_path, target_path)
print("文件移动完成!")
class Win(WinGUI):
def __init__(self):
super().__init__()
self.__event_bind()
self.attributes('-topmost', 1)
def __event_bind(self):
pass
if __name__ == "__main__":
win = Win()
win.mainloop()对图片做笔记的方法
由于对图片的编辑需要一定的可视化编辑过程,传统的线性笔记可能满足不了多个图片并行处理的问题,对图片的进一步关联可以借助 Excalidraw 画板来编辑,这里会借助一些 Excalidraw 的 JS 脚本和 Http Sever 服务以及 Quicker 动作来更方便的完善工作流。
Eagle 联动库外素材到 Excalidraw

首先由于 Eagle 的管理特性,并不适合在 Obsidian 里面管理图片,否则会生成一堆配置文件,基本每导入一个图片就会产生配置文件,所以 Eagle 适合库外建立,需要的时候再进行联动。
对于库外的文件直接拖入 Excalidraw 画板是行不通,但是可以通过一些 Javascript 脚本实现,切确的说是添加 Excalidraw 的脚本:
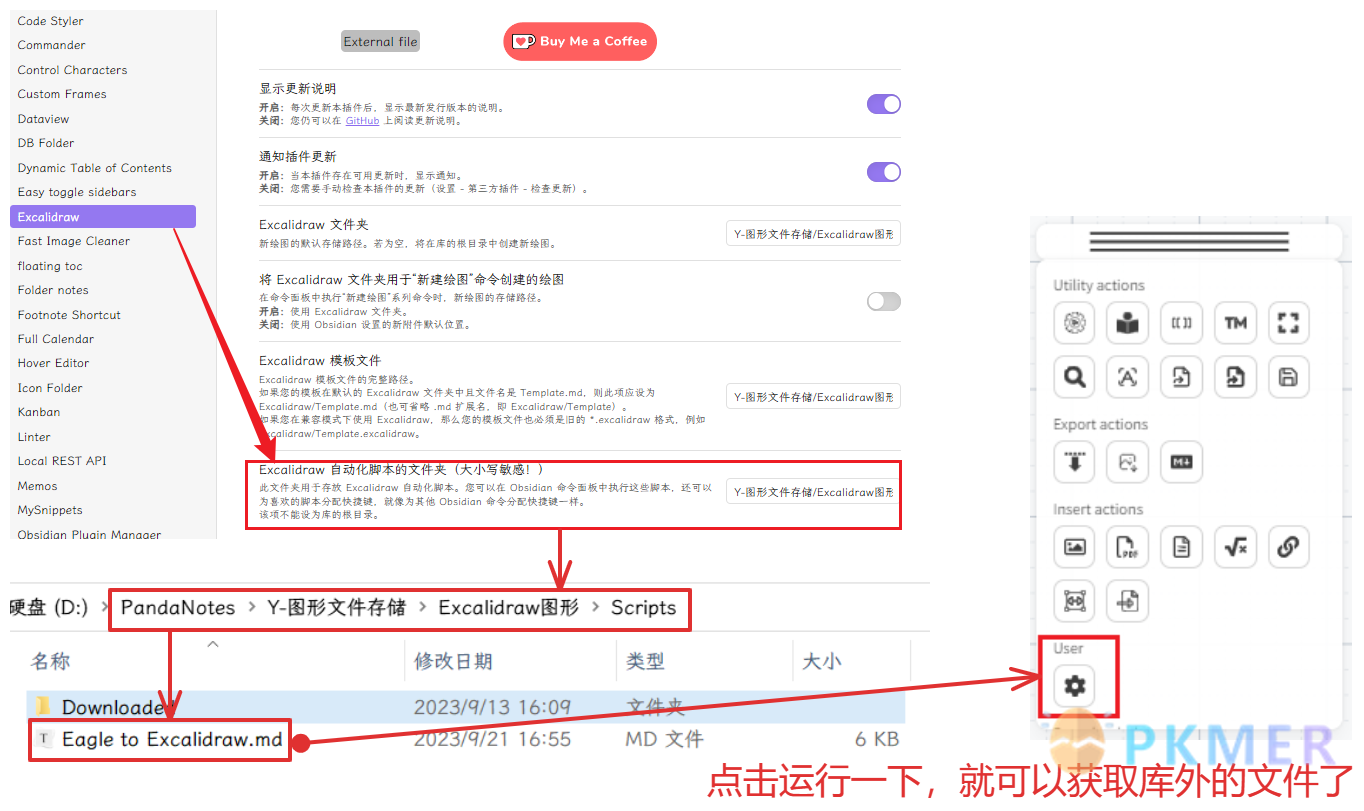
复制下面代码,在 Excalidraw 的 Script 文件中另存为一个 Eagle to Excalidraw 的 md 文件,注意要修改📌注释的路径为你自己定义的路径,当你启动 Excalidraw 画板时,工具面板会出现这个脚本,点击运行一下就可以链接局域网中文件了。为了防止有人看不懂,我还是附上图片示意一下:
/*
```javascript
*/
const path = require('path');
const fs = require("fs");
let api = ea.getExcalidrawAPI();
let el = ea.targetView.containerEl.querySelectorAll(".excalidraw-wrapper")[0];
el.ondrop = async function (event) {
console.log("ondrop");
event.preventDefault();
if (event.dataTransfer.types.includes("Files")) {
console.log("文件类型判断");
for (let file of event.dataTransfer.files) {
let directoryPath = file.path;
console.log(directoryPath);
if (directoryPath) {
console.log("获取路径");
let folder = directoryPath.match(/([^\\]+)\.info/i);
// let file_name = directoryPath.match(/([^\\]+)\.(png|jpg|jpeg|html|mhtml|pdf|ppt|pptx)/i);
let file_name = directoryPath.match(/([^\\]+)(\.[^\\]*)?$/i);
if (folder && file_name) {
eagle_id = folder[0].replace('.info', '');
folder = folder[0];
file_name = file_name[0];
console.log(`folder: ${folder};file_name:${file_name};eagle_id:${eagle_id}`);
// 将图片文件移动到指定文件夹
let sourcePath = directoryPath;
// 📌定义Obsidian内部附件保存的地址
let destinationPath = path.join(
"D:",
"PandaNotes",
"Y-图形文件存储",
"EagleImages",
file_name
);
fs.copyFileSync(sourcePath, destinationPath);
// 让默认插入文本为文件名
let insert_txt = file_name;
// 清空插入的环境变量
event.stopPropagation();
ea.clear();
await new Promise((resolve) => setTimeout(resolve, 300)); // 暂停一会儿
// 📌定义Eagle的路径,并读取metadata.json文件
const metadataPath = `E:\\PandaMemos.library\\images\\${folder}\\metadata.json`; // 替换为实际的文件路径
const metadataContent = fs.readFileSync(metadataPath, 'utf8');
// 解析为JSON对象
const metadata = JSON.parse(metadataContent);
// 设置不同文件类型的导入方式ea.addText为文本、ea.addImage为图片
if (
// 对网页统一用内部链接的形式
file_name.toLowerCase().endsWith(".html") ||
file_name.toLowerCase().endsWith(".mhtml") ||
file_name.toLowerCase().endsWith(".htm")
) {
let id = await ea.addText(0, 0, `[[${insert_txt}]]`, { width: 400, box: true, wrapAt: 50, textAlign: "center", textVerticalAlign: "middle", box: "box" });
let el = ea.getElement(id);
el.link = `eagle://item/${eagle_id}`;
await ea.addElementsToView(true, false, false);
if (ea.targetView.draginfoDiv) {
document.body.removeChild(ea.targetView.draginfoDiv);
delete ea.targetView.draginfoDiv;
}
} else if (
// 对图片统一用导入图片后附加链接的形式
file_name.toLowerCase().endsWith(".png") ||
file_name.toLowerCase().endsWith(".jpg") ||
file_name.toLowerCase().endsWith(".jpeg")
) {
let id = await ea.addImage(0, 0, insert_txt);
let el = ea.getElement(id);
if (metadata.url) {
// 将el.link的值设置为metadata.json中的url
el.link = metadata.url;
} else {
// 将el.link的值设置为Eagle的回链
el.link = `eagle://item/${eagle_id}`;
}
await ea.addElementsToView(true, false, false);
if (ea.targetView.draginfoDiv) {
document.body.removeChild(ea.targetView.draginfoDiv);
delete ea.targetView.draginfoDiv;
}
} else if (file_name.toLowerCase().endsWith(".url")) {
// 对url文件采用文本加入json的连接形式
link = metadata.url;
let id = await ea.addText(0, 0, `🌐[${insert_txt.replace(".url", "")}](${link})`, { width: 400, box: true, wrapAt: 50, textAlign: "center", textVerticalAlign: "middle", box: "box" });
let el = ea.getElement(id);
// 将el.link的值设置为Eagle的回链
el.link = `eagle://item/${eagle_id}`;
await ea.addElementsToView(true, false, false);
if (ea.targetView.draginfoDiv) {
document.body.removeChild(ea.targetView.draginfoDiv);
delete ea.targetView.draginfoDiv;
}
} else {
// 其余统一插入eagle连接
let id = await ea.addText(0, 0, `[[${insert_txt}]]`, { width: 400, box: true, wrapAt: 50, textAlign: "center", textVerticalAlign: "middle", box: "box" });
let el = ea.getElement(id);
// 将el.link的值设置为Eagle的回链
el.link = `eagle://item/${eagle_id}`;
await ea.addElementsToView(true, false, false);
if (ea.targetView.draginfoDiv) {
document.body.removeChild(ea.targetView.draginfoDiv);
delete ea.targetView.draginfoDiv;
}
}
}
}
}
}
};联动的不仅仅是图片
其实联动的不仅仅是图片,Eagle 还有另一个隐藏用法,那就是管理离线的网页。
Eagle 提供的浏览器拓展插件 Eagle for Edge,主要功能介绍:
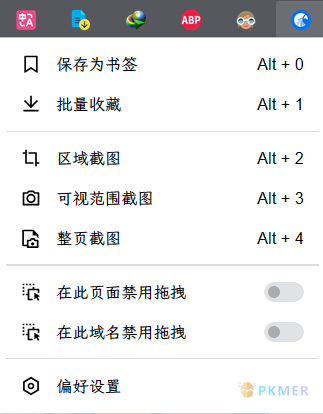
- 保存为书签:可以把网页剪藏到 Eagle 中,不过保存的是快捷方式,如果需要离线保存的话可以借助另外一个浏览器拓展插件 Singfile,可以把网页离线保存到本地。
- PS:直接复制链接粘贴到 Eagle 里面也可以获取网页的快捷方式,在内部查看;
- PS:这两款插件我都挺强推的,配合使用效果拉满,也可以等 Eagle 支持离线保存,不过目前保存快捷方式也挺方便。
- 批量收藏、区域截图、可视范围截图、整页截图都是截取网页图片,通过 Eagle for Edge 插件截取的都回附带网站链接,可以配合上述 Excalidraw 脚本使用,通过图片定位到网页。

Billfish 管理库内 Excalidraw 文件
Billfish 可以说是 Obsidian 最好的附件辅助管理工具了,采用文件夹的结构,而且并不会产生什么配置文件。

Billfish 是不会显示 Obsidian 笔记库中的 md 笔记的,主要显示图片、word、ppt、xmind 等格式文件。
我设想用 Billfish 专门管理 Excalidraw 的图形库,需要借助 Excalidraw 设置中的自动导出 PNG 设置,通过图片去定位 Excalidraw 画板。

首先需要了解一下 Obsidian 外部回链的构造,Obsidian 的回链构造很简单,就是笔记库名和相对路径。
obsidian://open?vault={笔记库名称}&file={笔记的相对路径(不带后缀)},以下用 Quicker 简单实现的方法:
- 先获取选中文件的路径;
- 对文件路径替换前面的绝对路径为 Obsidian 的外部回链,注意
{笔记库名称},我的为 PandaNotes; - 将 Excalidraw 自动导出的 PNG 的后缀
.png去掉; - 将路径符号转义一下;
- 打开链接
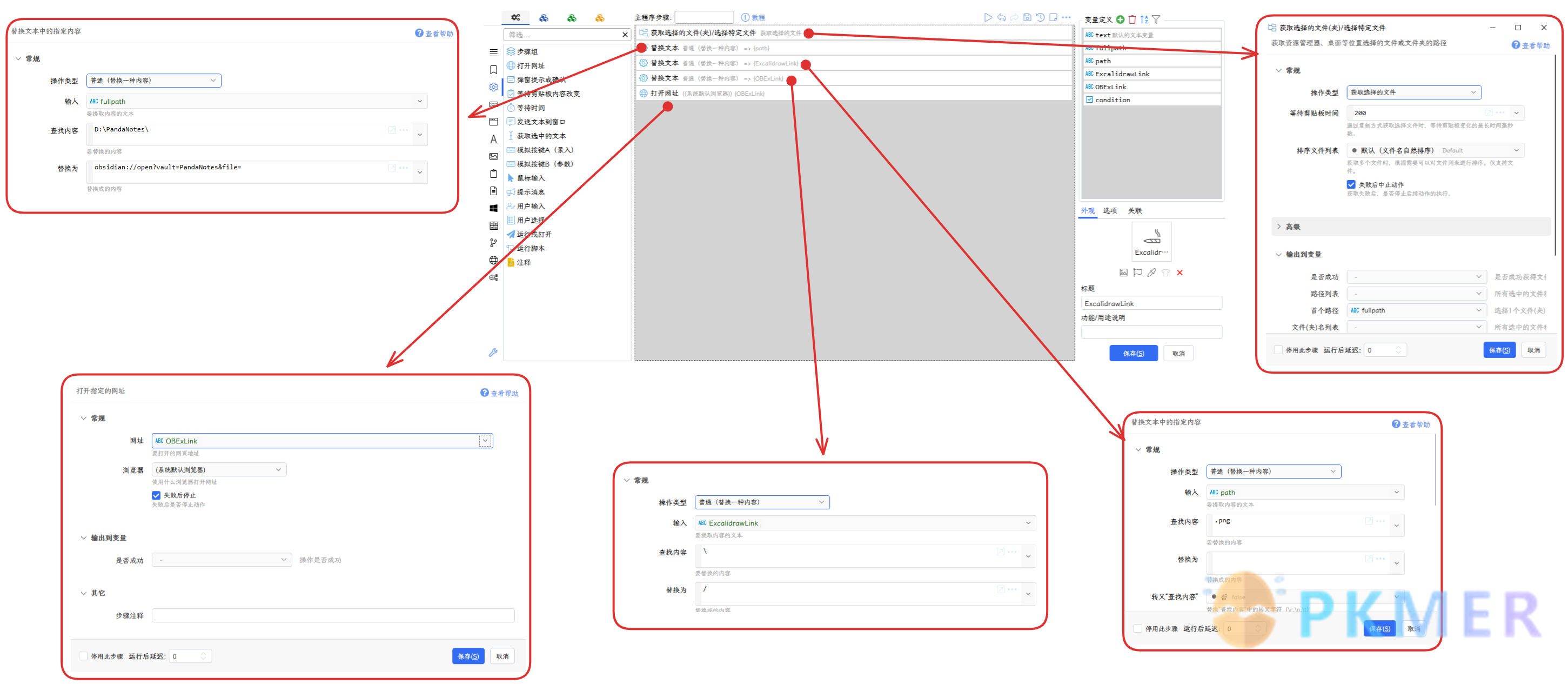
因为 Billfish 本来就是管理笔记库内部文件,构造的步骤也十分简单。
以图搜图
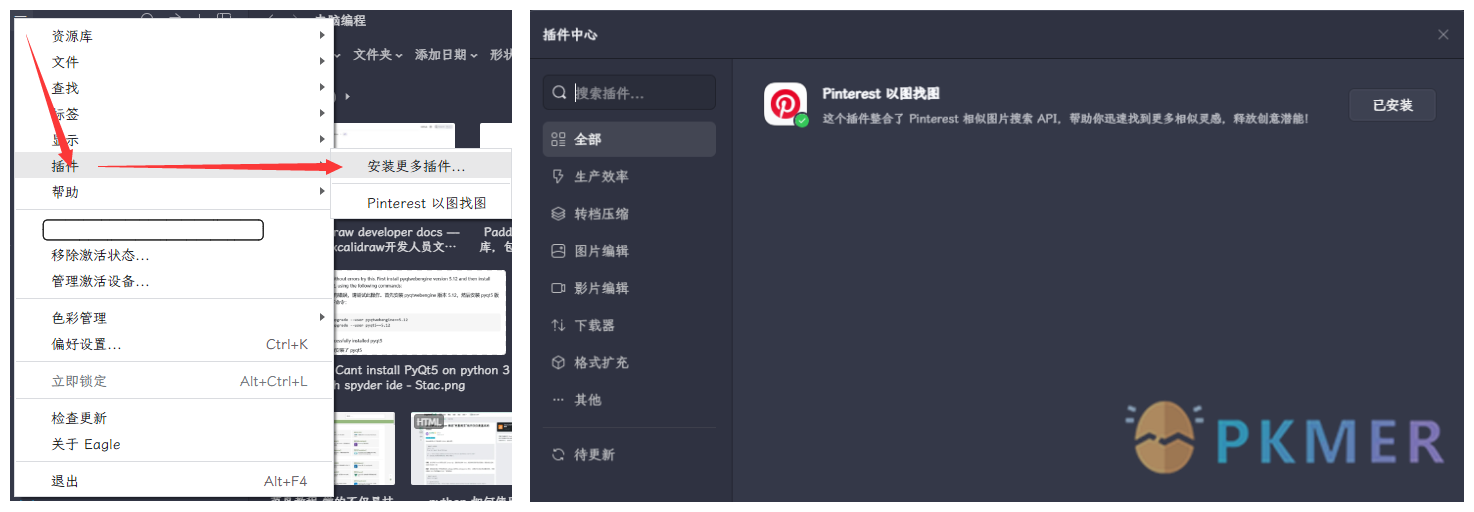
Eagle 插件:Pinterest 以图找图
默认的谷歌搜索的快捷键是 Shift + G
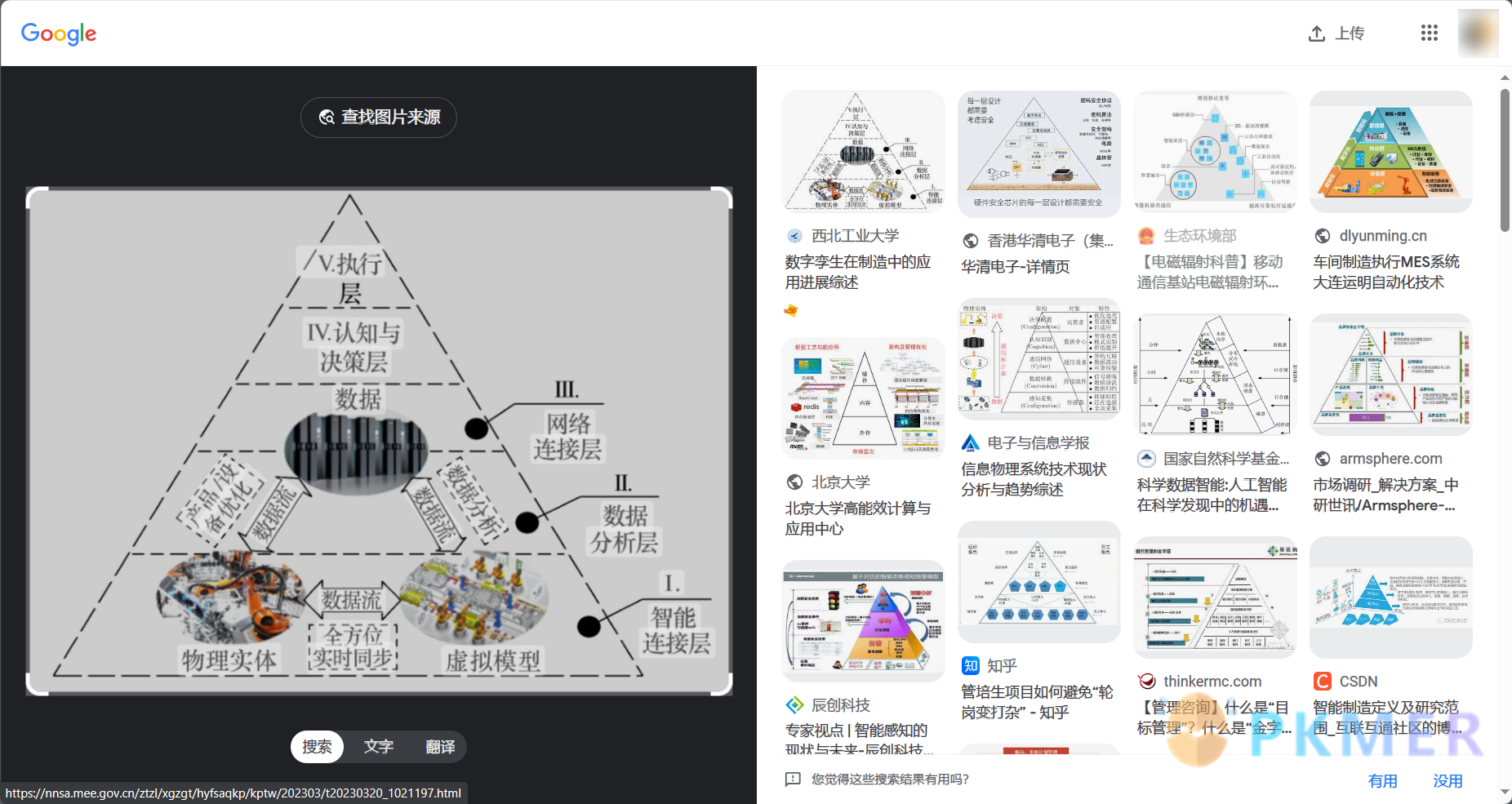
配合谷歌搜索引擎还可以提取并翻译图片的文字:
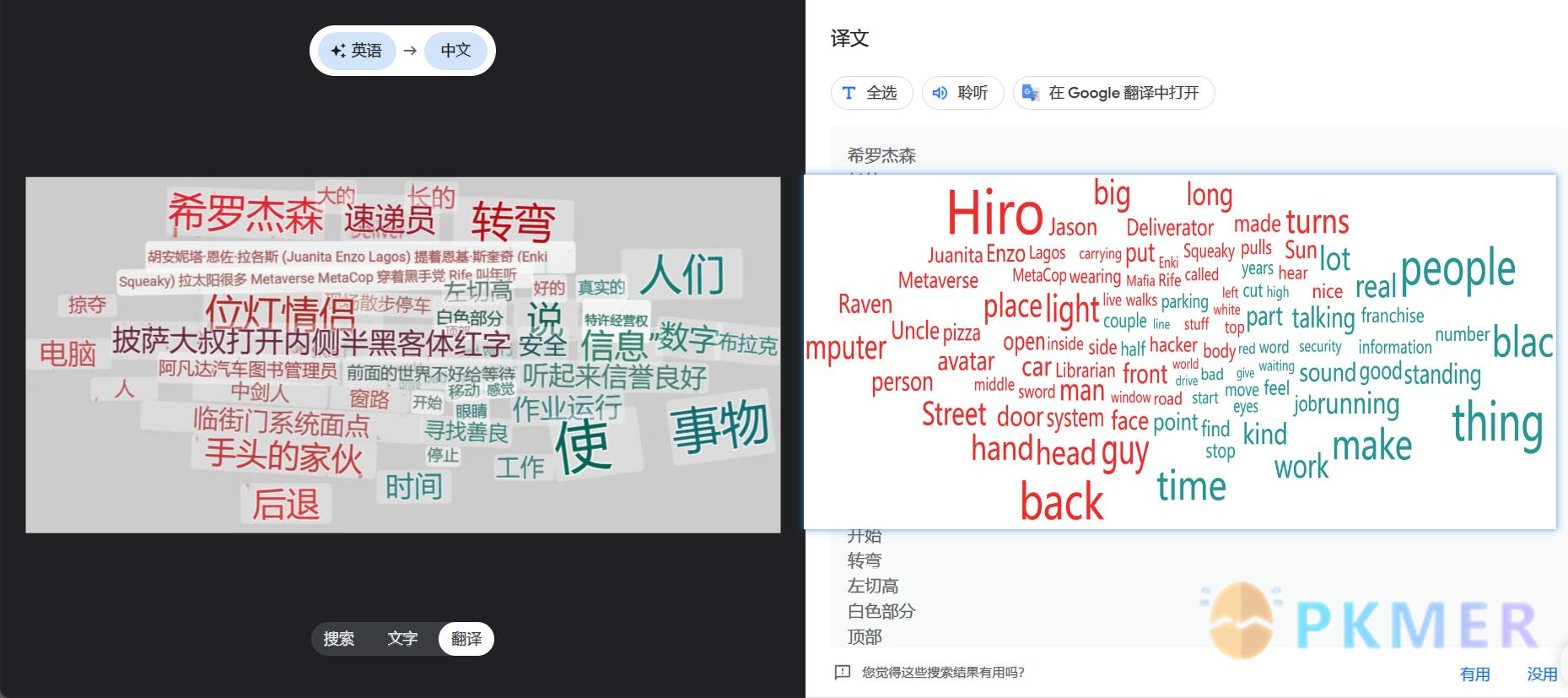
Eagle 提供的插件中心目前只提供了一个插件,诚心的希望以后功能越来越多🥰。
自建图片向量图以图搜图
通过本地图片建立向量库可以用 GitHUb 上的项目:reverse_image_search,来建立反向图像搜索。
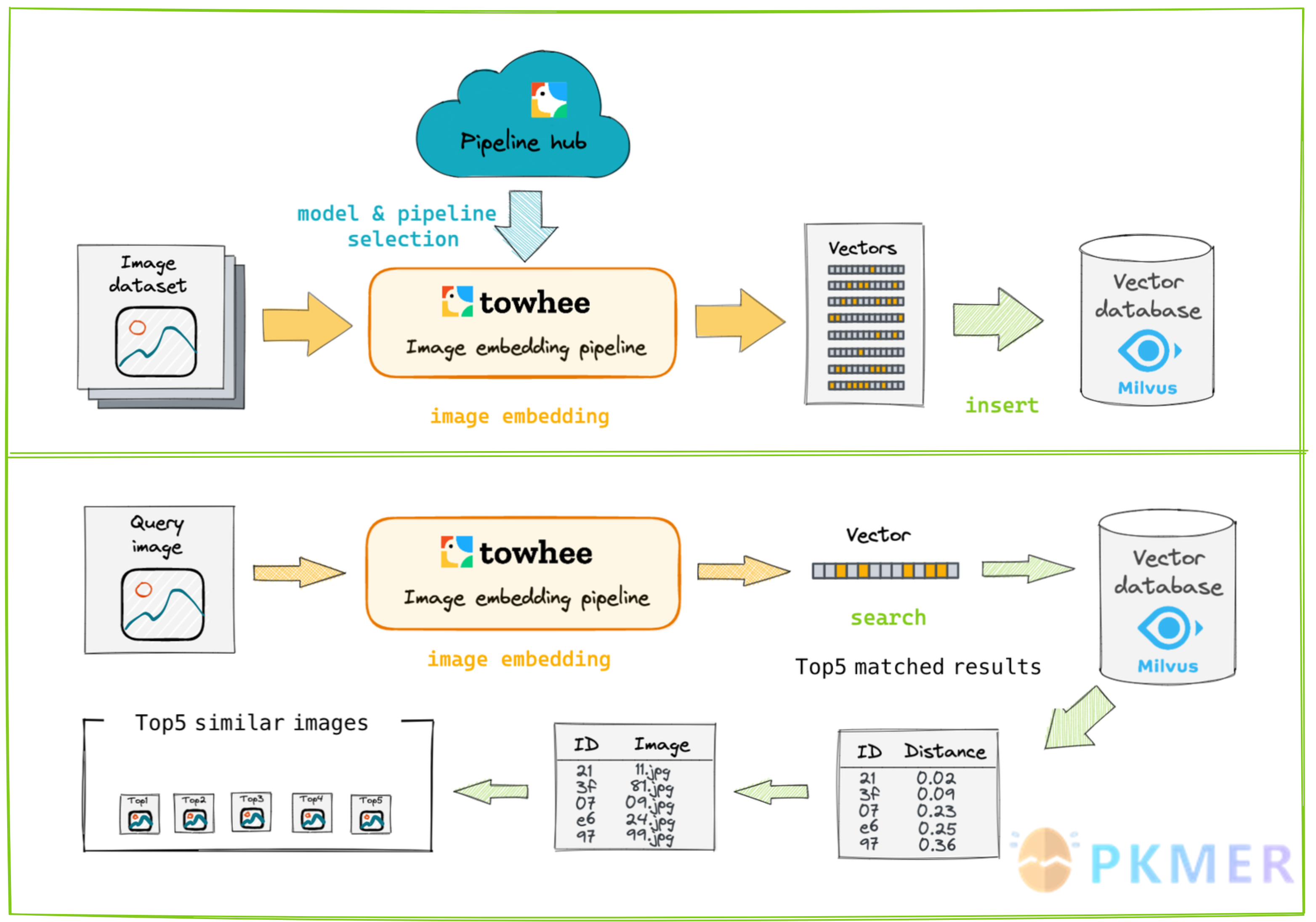
反向图像搜索将图像作为输入,并根据其内容检索最相似的图像。语义图像搜索背后的基本思想是将每个图像表示为预训练深度学习模型提取的特征的嵌入。然后可以通过存储和比较图像嵌入来执行图像检索。

由于环境配置比较复杂,这里就不详细讲述了,如果你感兴趣可以 GitHUB 上查看并实现,以下是实现效果:

以上就是我目前探索的工作流,主要通过 Eagle 来收集和管理素材,用 Excalidraw 对图片以及其他信息做笔记,这样就不会局限于线性笔记,用 Billfish 对 Obsidian 笔记库中 Excalidraw 的画板进行分类管理。
当然还是要以 Obsidian 的双链为主,画板主要整理思路的,如果你感兴趣,欢迎一起讨论😁。
讨论
若阁下有独到的见解或新颖的想法,诚邀您在文章下方留言,与大家共同探讨。

