
Brian 的分类系统
自从整个 PKM/B(base)事情开始流行以来,关于如何组织东西的讨论一直没完没了的。系统似乎还一直在推荐给我,从 PARA 到 Johnny Decimal,再到 folksonomies 等等。这是一个非常迷人和有趣的时代,看到这种发展也非常令人兴奋。然而,在所有这些来回和争论中丢失的一件事是,有一整个领域专门用于知识的表示组织编目和分类,这个领域已经存在了数百年并且拥有数千人的有经验人士:图书馆和信息科学。据我所知,这些新诞生的 PKM 或 PKB 组织系统几乎都没有从图书馆和信息科学中受益。 LIS 领域可以提供很多东西来帮助所有 PKM 人员。我将在下面稍稍讨论一下。但你为什么要相信我呢?我有什么资格?这两个都是好问题!我叫 Brian M. Watson(这是我的 推特 )。我是一位在不列颠哥伦比亚大学信息学院的一位在读博士生。我在画廊、档案馆、图书馆、博物馆和特藏 (GLAMS) 学习公平编目(equitable cataloging),我在印第安纳大学布卢明顿分校获得图书馆学硕士学位,在那里我学习元数据和数字人文学科。我还拥有德鲁大学的文学硕士学位,主要研究书籍的历史和性行为。换句话说,我研究人们如何组织事物,以及机构如何以更合乎道德的方式进行组织。但这不是我今天来这里的目的。今天我要谈谈我的系统
首先,是一些定义:
分类 classification
起源:借用自拉丁语,Etymon: Latin classificatio.
词源说明:< post-classical Latin classificatio (1673 in a German source; 1767 in Linnaeus) < classical Latin classis class n. + -ficātiōn- , -ficātiō
- 分类的结果;根据共同的特征或感知的或推断的亲缘关系,将事物有系统地分布、分配或安排在若干不同的类别中。同样指:分类的系统或方法。
- 根据共同特征或可感知的亲缘关系在类中进行分类或安排的行动;分配到一个或多个适当的类。
目录 catalogue
词源说明:< French catalogue, and < late Latin catalogus, < Greek κατάλογος register, list, catalogue, < καταλέγειν to choose, pick out, enlist, enroll, reckon in a list, etc., < κατά down + λέγειν to pick, choose, reckon up, etc
- 一个列表,登记,或完整的枚举;这个简单的意思现在是过时和陈旧的。
- 现在通常通过系统的或有方法的安排,按字母或其他顺序,并经常增加简短的细节,描述或帮助识别,表明地点、位置、日期、价格或类似情况,来区别于单纯的清单或枚举。
说人话:
编目通常具有称为受控词汇表的东西。受控词汇表通常看起来像这样(这玩意儿来自美国国会图书馆主题标题 Library of Congress Subject Headings PDF Files,关于这玩意儿深入有价值的东西可以看我的博客 Internship Diaries #3: Thesaurasize Me, Captain – bloggings & musings):

当我看到像内容地图 (moc:Map of Content) 这样带有标签定义的东西时,我看到一个受控的词汇表跳过了分层分类系统。 不受控制的词汇表更像是你在图书馆里看到的混乱的标记系统(或者可能是组织不良的 PKM)
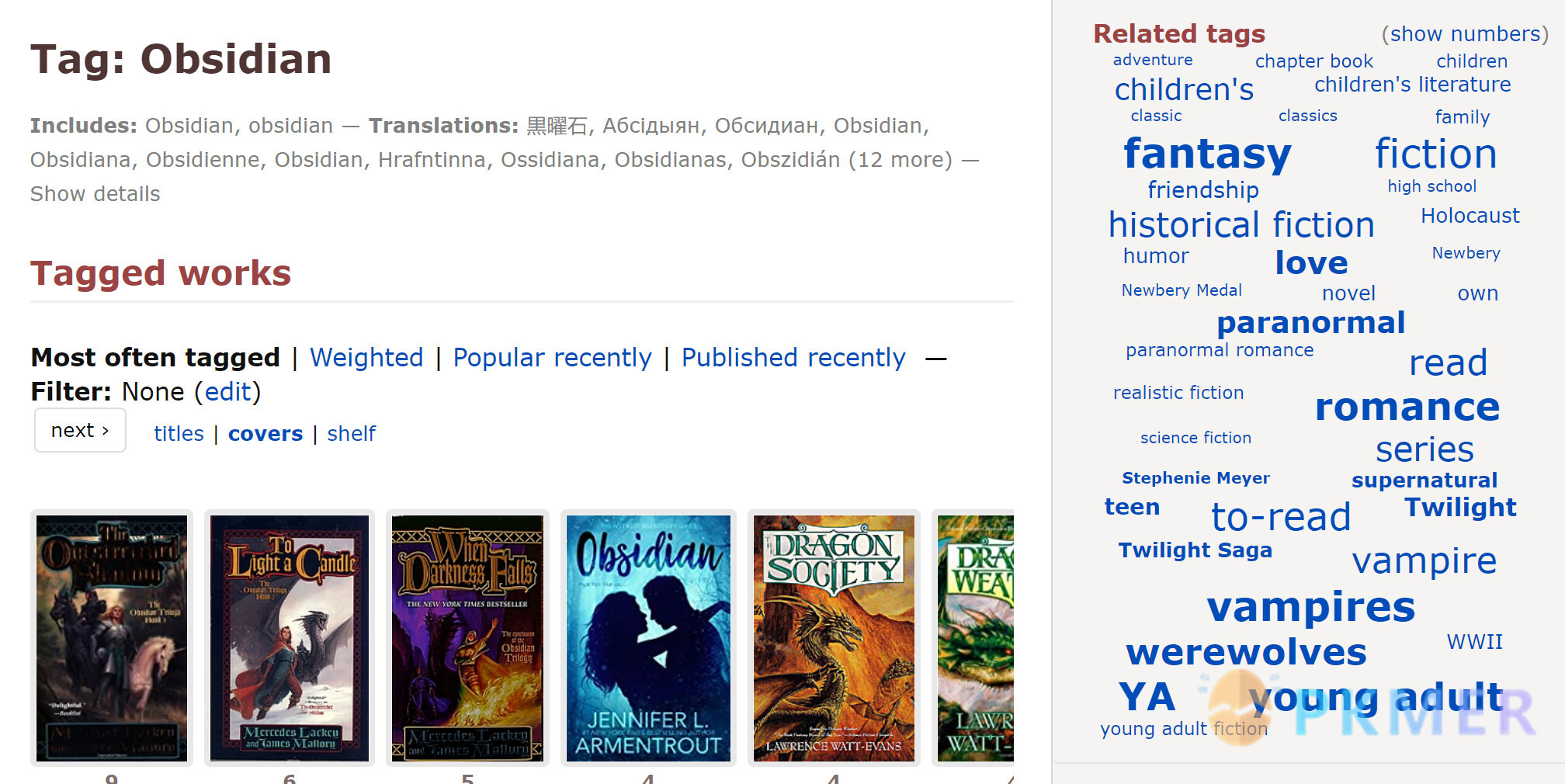
打标签非常有用,但是缺乏控制和意义的标签会很快破坏掉整个系统。正如一篇文章所说,“一个(受控术语)胜过一千个标签”。“a (controlled term) is worth a thousand tags”
我在这里的部分观点是说,i18n1 组织你的 PKB,你应该搞个受控词汇表,并在可能的情况下搞个分类系统。
但我不是来传道的。如果你不想要它,或者它不适合你,没关系。下面我要做的是谈谈我自己的系统,我花了几个月的时间设计来满足我的 PKB 需求。
十进制分割的 PKB 系统
The Decimal-Cutter PKB System
这个系统的灵感来自于以下主要系统: PARA, Johnny Decimal, Universal Decimal Classification. 和 Cutter Expansive Classification. 我还从 Nick Milo 的 LYT Kit 592、色彩理论、美国国会图书馆分类法、布利斯分类法、统一十进制中获得了灵感。
PARA
Tiago Forte 的 PARA Method: A Universal System for Organizing Digital Information
从 PARA 中,我接受的建议是数字系统应该是:
- 跨平台,能够与任何应用进程一起使用,不管是现在存在的还是尚未开发的
- 以结果为导向,以支持交付有价值的工作的方式构建信息
- 灵活,能够处理您现在和将来承担的任何项目或活动
- 通用,包括来自任何来源的任何可以想象的信息
我也从 PARA(项目 - 领域 - 资源 - 档案)的想法中得到了一些启发。对于蒂亚戈来说,这些是:
A project is “a series of tasks linked to a goal, with a deadline.”
An area of responsibility is “a sphere of activity with a standard to be maintained over time.”
A resource is “a topic or theme of ongoing interest.”
Archives include “inactive items from the other three categories.”项目是“与目标相关的一系列任务,有截止日期”。
一个领域代表“一个有标准的活动范围,需要长期保持”。
资源是“持续感兴趣的主题或主题”。
档案包括“其他三类非活动项目”。
我用我的顶级文档组织来即兴发挥这些:
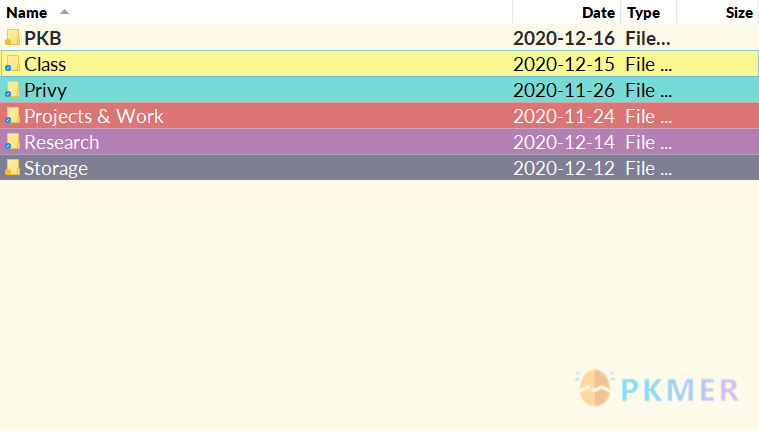
我在窗口中使用目录 Opus 来用颜色标记某些区域。在我的 Zotero,我的 Airtable,我的 Google 日历和我的文档中,颜色是相似的。这意味着我一眼就能看出它来自我生活的哪个领域。
其余部分,我们只关注 PKB 文件夹。
Johnny 十进制
Johnny Noble 的 Johnny Decimal
我吸纳了 Johnny 十进制中的数字文件夹结构(分类),具体步骤如下:
第一步:把所有东西分成十类
- 把你所有需要组织的东西排序,最多分是个大类
- 确保每个类绝对没有交叉
- 对每个类贴上标签
这迫使你对事物进行相当广泛的分组,但这就是重点。它可能长这样:
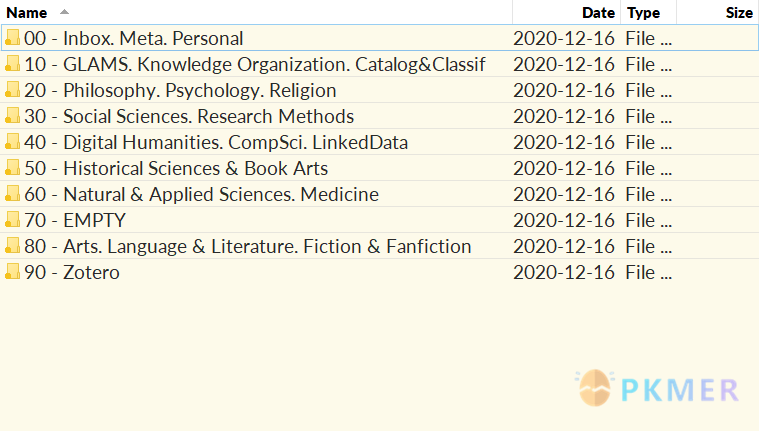
我将稍后讲解文件夹标题,每个子文件夹同样这样用 Johnny 十进制进行标注。
文件夹目录的小数点
小数点前:目录
小数点是用来把数字分割的,但更重要的是提醒大家,小数点前的数字才是重要的部分。这是类别。
小数点后:ID
小数点后的数字只是一个计数器。我们称之为 ID:它从.01 开始,并随着您创建的每件事物而增加。
Zotero PARA Sidebar
我不会按 Zotero PARA Sidebar 那样的数字顺序进行规划,还记得 PARA 吗?这个分类系统应该在任何地方都能应用,我的 Zotero 也一样。
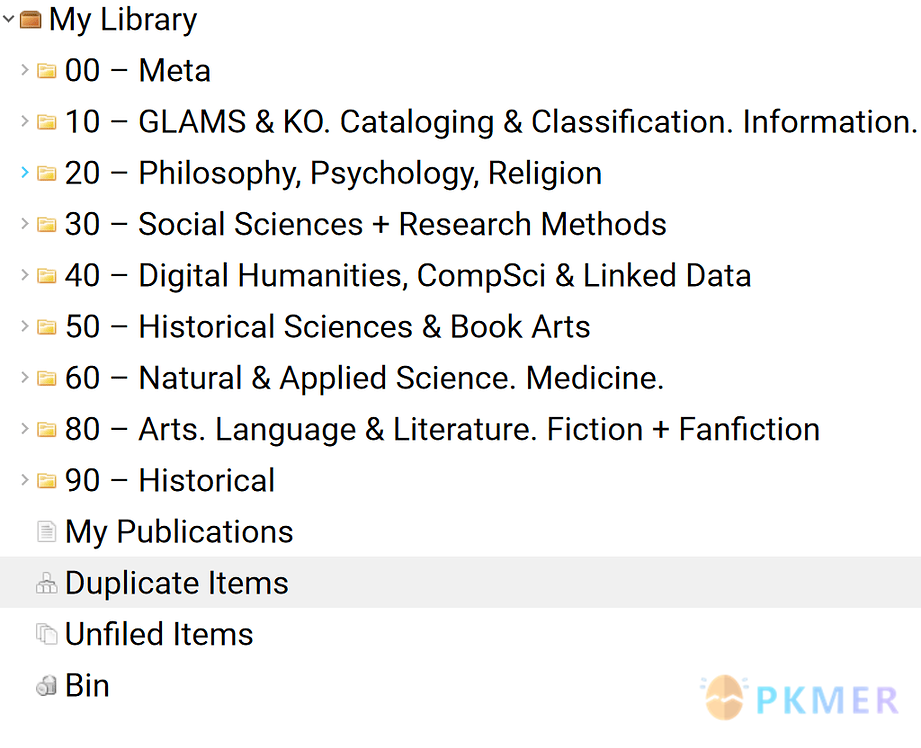

诚然,其中大部分仍在建设中,所以类别数字还没有出现。它们最终会有的!
作为一个边栏,你可以看到我的 zotero 中每个提示色的要点是什么(也与我的文件夹颜色 + 颜色理论有关,但我只是把它作为一个数据点。)


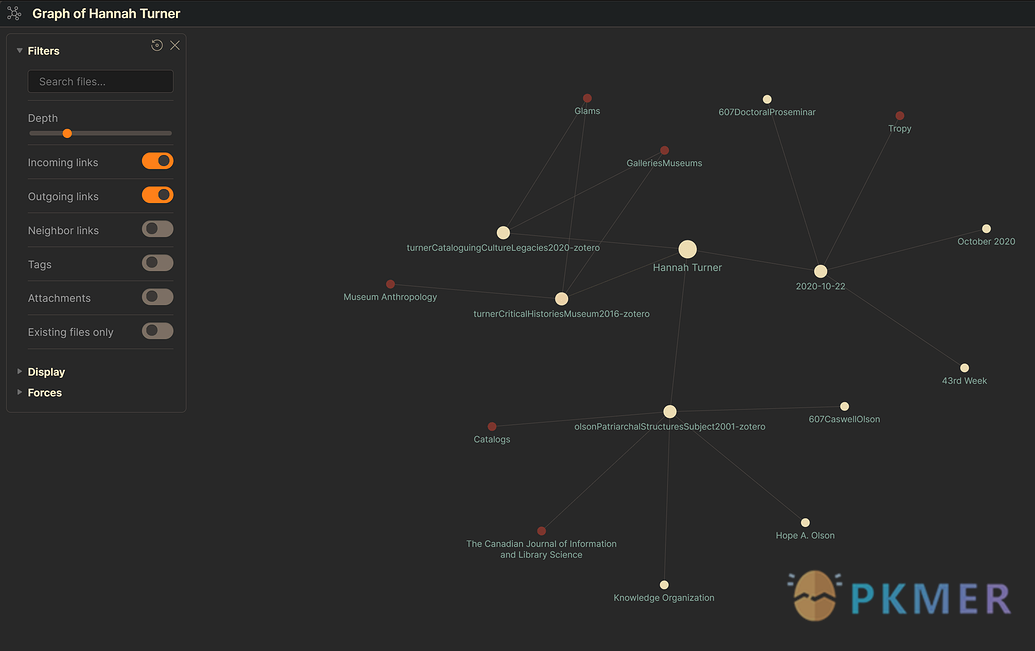
这些笔记最终出现在 Obsidian 中,我可以在那里看看图谱,看看 Hannah Turner 是如何进入我的学术工作的:
通用十进制分类
- UDC Consortium’s Universal Decimal Classification
- Charles Ammi Cutter’s Expansive Classification
- Nick Milo’s LYT Kit
不管怎么说,回到开头吧。我最喜欢的分类系统是通用十进制,部分原因是它可以做很酷的事情,比如:
数字序列被精确类型的标点符号分隔,这表明表达式是类的组合而不是简单的类,例如 34:32 中的冒号表明有两个不同的记号元素: 34 法律.法学和 32 政治;以下代码 913(574.22) “19”(084.3) 中的结尾和开头的括号和双引号表示四个独立的记号元素: 913 区域地理,(574.22)北哈萨克斯坦(Soltüstik Qazaqstan);“19”20 世纪和(084.3)地图(文件形式)。
事物也可以用 ”+” 来协调分割,用 ”/” 来标记为第一个术语的扩展,用 [] 来分组,用 “A/Z ” 来指定它的包容性,并通过 ”*” 引入其他系统。
所以搜索 “1960-80 年由双性恋作者创作的关于挪威女同性恋消防员的小说 ” 是一个合法的查询。
我一直想把我的系统强行纳入通用十进制,但一直在反对它所要描述的类别有多大和不可能有多大。然后我遇到了卡特分类法。
查尔斯 - 阿米 - 卡特(Charles Ammi Cutter)受到他的同代人梅尔维尔 - 杜威(Melvil Dewey)的十进制分类法的启发,并在杜威的鼓励下,为温彻斯特镇图书馆制定了自己的分类方案。当他发表该方案时,许多图书馆发现这个系统对于他们的需求来说过于详细和复杂,卡特收到了许多小型图书馆的馆员的请求,他们希望该分类法能够适应他们的藏书。
结果是《扩展性分类法》,这个分类系统可以向上或向下扩展,以满足从大到小的图书馆的需要。在他去世前,卡特完成并出版了前六种分类法的导言和时间表,但他在第七种分类法上的工作却因他 1903 年的去世而中断了。美国国会图书馆将他所做的工作纳入了国会图书馆系统。
第一个分类法看起来是这样的:
For a very small Library
A — Works of reference and works of a general character covering several classes Includes such works as are usually kept in the Delivery Room or the Reading Room for the free use of the public, such as the best dictionaries of languages and other subjects ; encyclopaedias, both general and special, handbooks of dates, dictionaries of biography and peerages, gazetteers, manuals of statistics, books of quotations, concordances, etc.
B — Philosophy and Religion Includes Moral philosophy.
E — Historical sciences Includes Biography, History, and Geography and Travels.
H — Social sciences Includes Statistics, Political Economy, Commerce, the Poor, Charity, Education, Peace, Temperance, the Woman question, Politics, Government, Crime, Legislation, Law.
L — Sciences and Arts, both Useful and Fine
X — Language
Y — Literature Includes Literary history, Bibliography, and the arts that have to do with books.
Yf — Fiction To save time it is not unusual to omit the class-mark of the class Fiction, calling for and charging novels by the book-mark alone.从中获得灵感,当我与 Nick Milo 交谈时,我正在做一个非常个性化的版本。
如果你最近一直在关注 Nick Milo 的 LYT 工具包,你会注意到从杜威十进制分类法中跳出来的一大步。尼克听取了人们对杜威是一个种族主义和性别歧视的大人物的担忧,即使在他的时代也是如此。(资料来源一:one,二:two,三:three)。
在与尼克进行了一次愉快的交谈后,我们共同合作,将 UDC 和 Cutter 分类结合起来,形成了现在的 LYT:
The Self
000 Knowledge Management
100 Personal Management
200 Philosophy & Psychology; Spirituality & Religion
Others
300 Social Sciences
400 Communications & Rhetoric; Language & Linguistics
Others + Self
500 Natural Sciences
600 Applied Sciences
700 Art & Recreation
800 Literature
History of Others & Self
900 History & Biography & Geography尼克已经非常清楚的一件事,我也会清楚的是,这是一个个人知识库,所以你应该把这些分类作为一个起点,自己做。这就是我所做的:
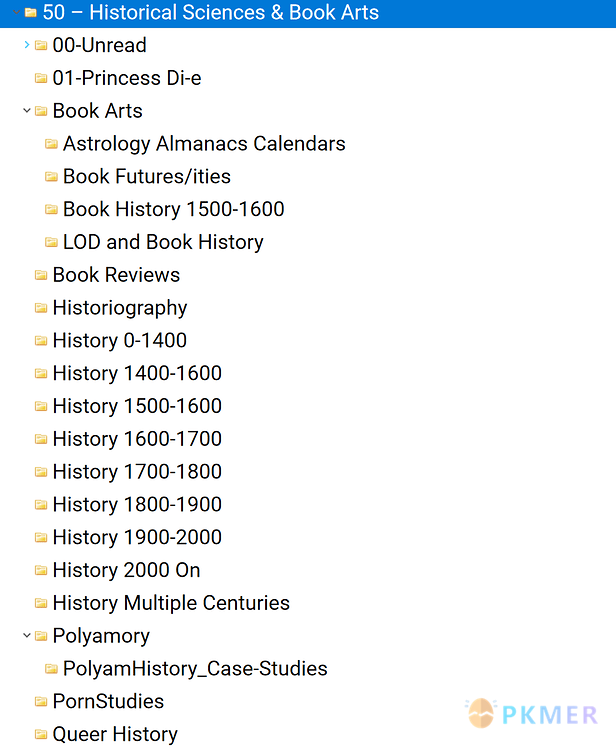
我有一个比大多数人大得多的历史部分,所以对我来说重要的是它有自己的部分,就像这样:
Footnotes
-
i18n(国际化,internationalization,因为最开始的字母 i 和最后的字母 n 之间有 18 个字符,简写成 i18n),让软件支持不同国家的语言实现国际化,通过建立词汇表,可以实现国际化是因为在不同的语言环境下,同一个词汇可能有不同的翻译,如果每次都需要重新编写代码来适应不同的语言环境,就会增加代码的维护难度和复杂度。而通过建立词汇表,将需要翻译的文本放在一个集中的地方,即使需要支持新的语言或者修改某些翻译内容,也只需要修改词汇表中的内容,而不需要修改代码。这样也可以让翻译工作更加专业化,提高翻译的质量和效率。因此,建立词汇表是实现国际化的重要手段之一,也是现代软件开发中常用的方法。 ↩
讨论
若阁下有独到的见解或新颖的想法,诚邀您在文章下方留言,与大家共同探讨。

